Weighted Dataset Mixing#
Ray Data allows you to combine multiple datasets into a single streaming dataset with control over how often rows from each source appear. This is useful for:
Class / scenario balancing: upsample rare scenarios or harder tasks so that training batches see them more often.
Multi-task pretraining: combine code and web text datasets at fixed ratios.
Catastrophic forgetting prevention: keep a small fraction of an older dataset in the mix while training on a newer one.
Quickstart#
import ray.data
from ray.train.torch import TorchTrainer
from ray.train import ScalingConfig
# Read and preprocess each source independently.
# NOTE: These are mocked datasets for demonstration purposes.
def preprocess(row):
return row
ds1 = ray.data.from_items([{"x": 1} for _ in range(750)]).map(preprocess)
ds2 = ray.data.from_items([{"x": 2} for _ in range(250)]).map(preprocess)
# Output batches will contain 75% rows from ds1, 25% from ds2 (in expectation).
mixed = ds1.mix(ds2, weights=[0.75, 0.25])
def train_fn_per_worker(config):
shard = ray.train.get_dataset_shard("train")
for batch in shard.iter_torch_batches(batch_size=128):
print(batch)
trainer = TorchTrainer(
train_loop_per_worker=train_fn_per_worker,
scaling_config=ScalingConfig(num_workers=4),
datasets={"train": mixed},
)
Mixing strategies#
You can compose mix() with other Ray Data operations to implement different mixing strategies, depending on how granular you want the mixing ratio to be. The sections below cover per-block mixing (mix() on its own) and random mixing (mix() followed by a shuffle).
Per-block mixing#
By default, each output block comes from exactly one input dataset. mix() keeps a running row count per source and, on every step, pulls the next block from whichever dataset is furthest behind its target ratio. Over time, the cumulative row counts converge to the requested weights.
Suppose you mix two datasets ds1 and ds2 with weights=[0.75, 0.25], and both sources produce blocks of equal size. This data pipeline then splits across 4 training workers, and data parallel training constructs a global batch across all workers.
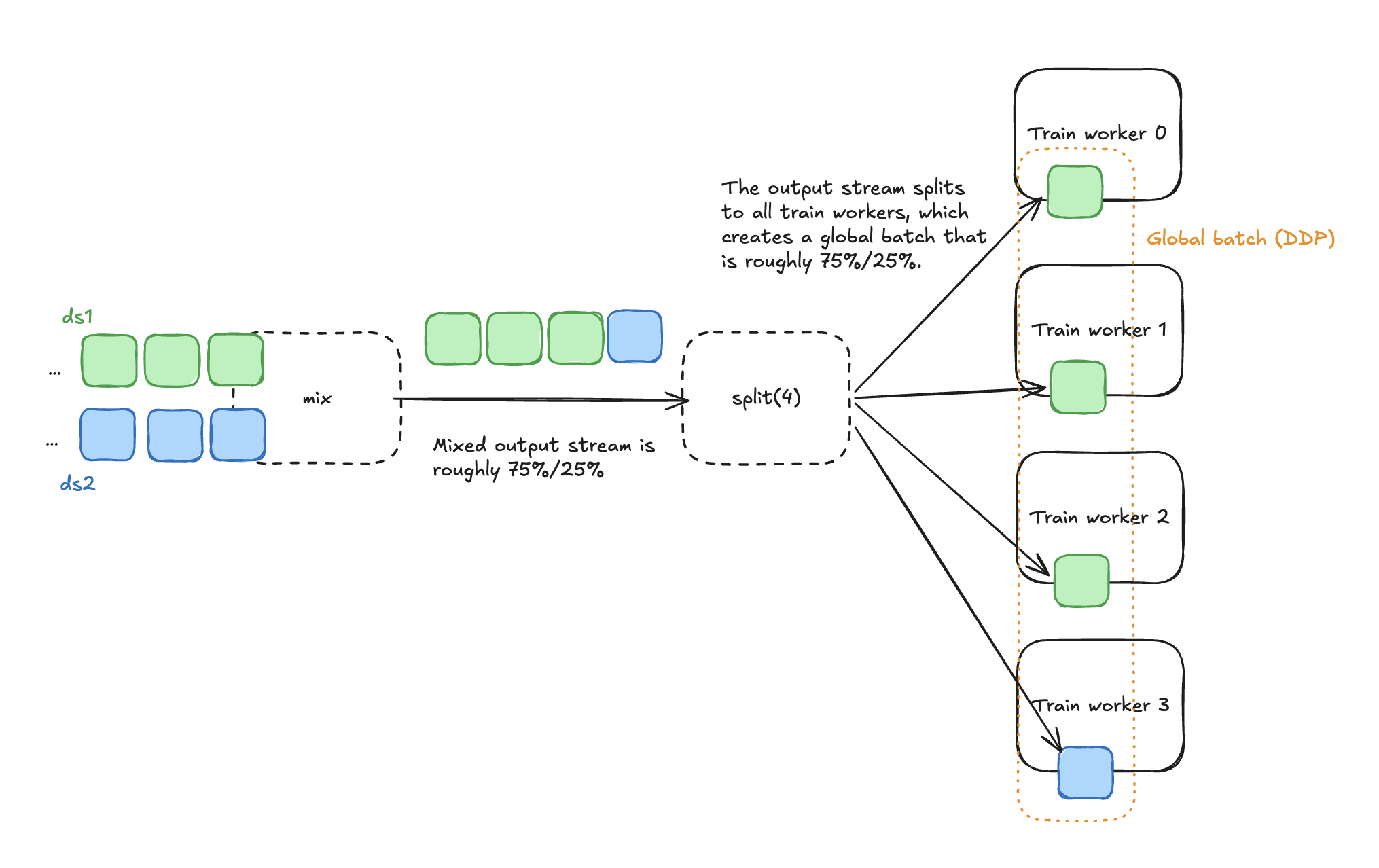
With uniform block sizes, the ratio is exact within any window of 1 / min(weights) blocks. With weights=[0.9, 0.1], you’re guaranteed a block from the second dataset at least once in every 10-block window.
Note
Blocks are the unit of data transfer in Ray Data, and they don’t map 1:1 to training batches. Workers construct each batch by pulling rows from one or more blocks. With per-block mixing, this means each local batch may contain data from one or more of the input datasets, depending on how block sizes compare to batch sizes. The next section covers how to align them with a streaming repartition.
Advanced: Standardize input block sizes#
If your input datasets produce blocks of very different sizes, a single large block can temporarily push that source ahead of its target ratio. mix() self-corrects on subsequent pulls, so the ratio is still correct in expectation—but a global batch built from a small number of those blocks can look skewed.
To tighten the per-batch window, standardize input block sizes upstream with ds.repartition(target_num_rows_per_block):
LOCAL_BATCH_SIZE = 128
ds1 = ray.data.from_items([{"x": 1} for _ in range(750)]).map(preprocess)
ds2 = ray.data.from_items([{"x": 2} for _ in range(250)]).map(preprocess)
# Standardize block sizes so the ratio holds within tighter windows.
ds1 = ds1.repartition(target_num_rows_per_block=LOCAL_BATCH_SIZE)
ds2 = ds2.repartition(target_num_rows_per_block=LOCAL_BATCH_SIZE)
mixed = ds1.mix(ds2, weights=[0.75, 0.25])
Note
You may want to repartition to some multiple of batch size (for example, N * LOCAL_BATCH_SIZE) if your rows are small in terms of bytes. This prevents splitting blocks into extremely small pieces that increase overhead.
Random mixing#
The per-batch ratio quality of per-block mixing depends on two things: the sizes of the input blocks (covered in the preceding section) and the number of training workers contributing to each global batch. A global batch aggregates num_workers * grad_accum_steps local batches, each drawn from a single dataset, so the more local batches you have per global batch, the closer the ratio holds to the target.
The extreme case: training on a single worker with no gradient accumulation means every global batch is a local batch, so every batch comes from a single dataset.
Adding a streaming shuffle after mix() switches you to random mixing: the shuffle redistributes rows across block boundaries so each batch directly contains rows from multiple datasets in roughly the requested proportion, regardless of how many workers you’re training on. mix() still governs the ratio; the shuffle just spreads it within each batch.
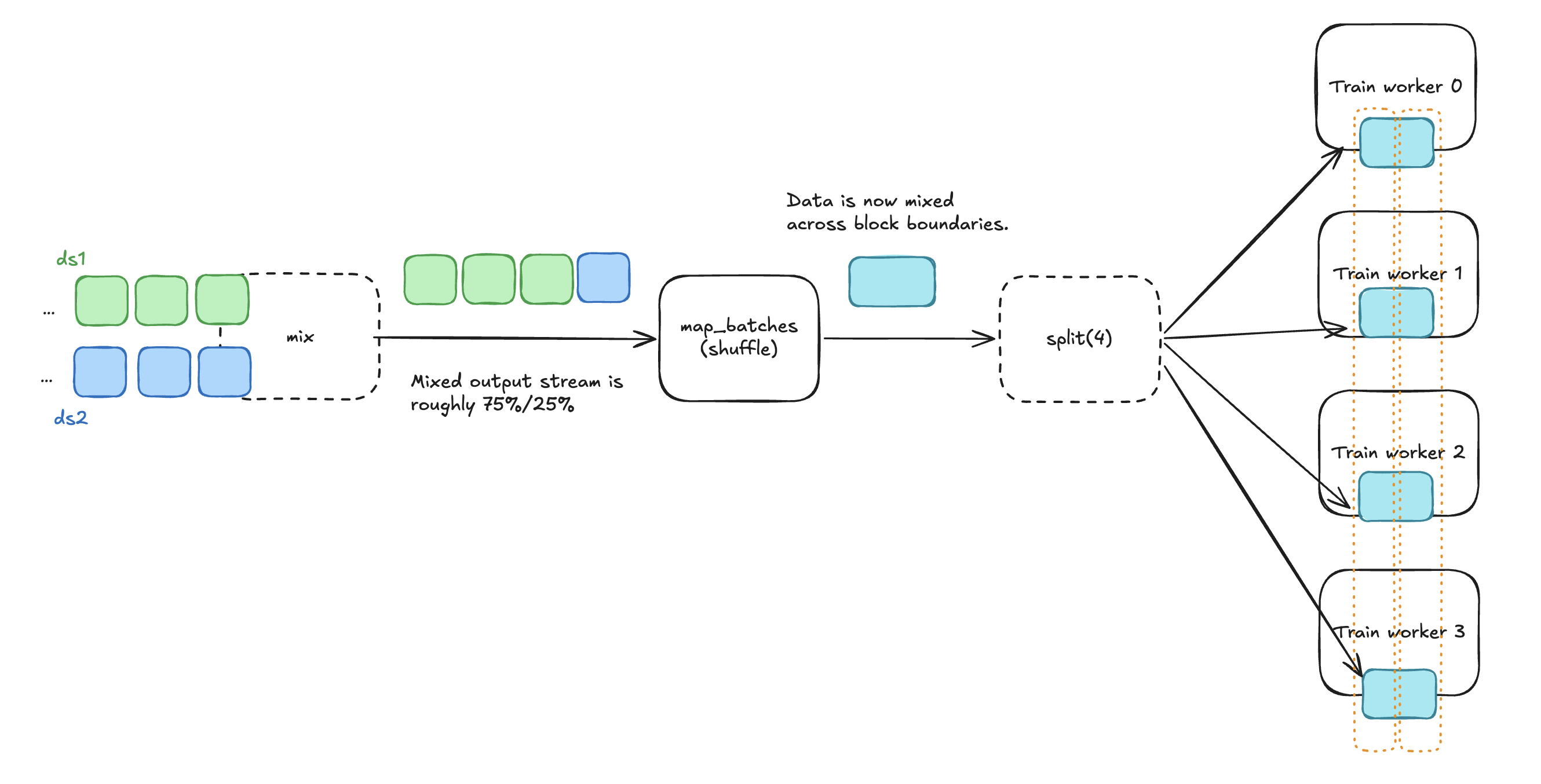
Two streaming-friendly shuffle options in Ray Data:
Local buffer shuffle (
iter_batches()withlocal_shuffle_buffer_size)
import numpy as np
import pyarrow as pa
LOCAL_BATCH_SIZE = 128
ds1 = ray.data.from_items([{"x": 1} for _ in range(750)]).map(preprocess)
ds2 = ray.data.from_items([{"x": 2} for _ in range(250)]).map(preprocess)
ds1 = ds1.repartition(target_num_rows_per_block=LOCAL_BATCH_SIZE)
ds2 = ds2.repartition(target_num_rows_per_block=LOCAL_BATCH_SIZE)
mixed = ds1.mix(ds2, weights=[0.75, 0.25])
# Add a shuffle after mix() to get random mixing.
def random_shuffle(batch: pa.Table) -> pa.Table:
indices = np.random.permutation(len(batch))
return batch.take(indices)
# Set the shuffle buffer size to be large enough for good mixing quality across datasets.
SHUFFLE_BUFFER_SIZE = 64 * LOCAL_BATCH_SIZE
mixed = mixed.map_batches(random_shuffle, batch_size=SHUFFLE_BUFFER_SIZE, batch_format="pyarrow")
Stopping conditions#
Condition |
Behavior |
|---|---|
|
Pipeline ends when the longest dataset is exhausted. Shorter datasets drop out once exhausted; remaining batches come from the still-active datasets. |
|
Pipeline ends when the shortest dataset is exhausted. Other datasets are truncated. |
See MixStoppingCondition for more details.
Limitations#
Avoid
map()/filter()aftermix(). Downstream transformations can combine or split blocks before they reach the trainer, which breaks the row-ratio guaranteesmix()provides. Apply per-dataset transforms upstream ofmix().Schemas must match.
mix()does not unify schemas for you. Applymap()orselect_columns()upstream to make all inputs structurally identical.Heavily skewed weights (current limitation). All input datasets currently execute concurrently with some portion of cluster resources equally divided between them. With heavily skewed weights (for example,
[0.95, 0.05]), the high-weight dataset may bottleneck while the low-weight dataset idles. For now, keep weights within roughly 5x of each other (for example,[0.4, 0.3, 0.2, 0.1]).