Distributed RAG pipeline#
This tutorial covers end-to-end Retrieval-Augmented Generation (RAG) pipelines using Ray, from data ingestion and LLM deployment to prompt engineering, evaluation and scaling out all workloads in the application.
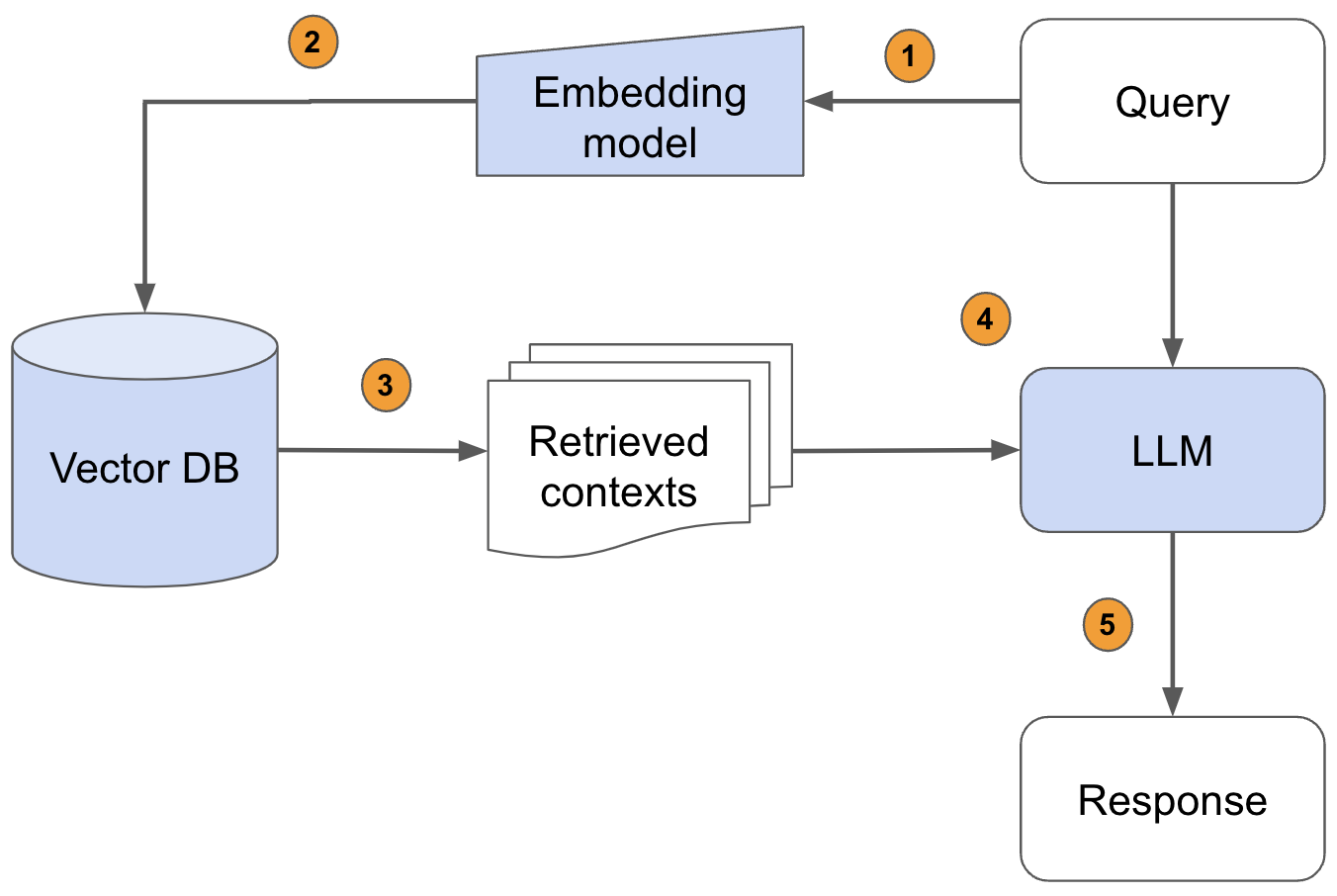
Notebooks#
01_(Optional)_Regular_Document_Processing_Pipeline.ipynb
Demonstrates a baseline document processing workflow for extracting, cleaning, and indexing text prior to RAG.02_Scalable_RAG_Data_Ingestion_with_Ray_Data.ipynb
Shows how to build a high-throughput data ingestion pipeline for RAG using Ray Data.03_Deploy_LLM_with_Ray_Serve.ipynb
Guides you through containerizing and serving a large language model at scale with Ray Serve.04_Build_Basic_RAG_Chatbot
Combines your indexed documents and served LLM to create a simple, interactive RAG chatbot.05_Improve_RAG_with_Prompt_Engineering
Explores prompt-engineering techniques to boost relevance and accuracy in RAG responses.06_(Optional)_Evaluate_RAG_with_Online_Inference
Provides methods to assess RAG quality in real time through live queries and metrics tracking.07_Evaluate_RAG_with_Ray_Data_LLM_Batch_inference
Implements large-scale batch evaluation of RAG outputs using Ray Data + LLM batch inference.
Note: Notebooks marked “(Optional)” cover complementary topics and can be skipped if you prefer to focus on the core RAG flow.