Batch inference#


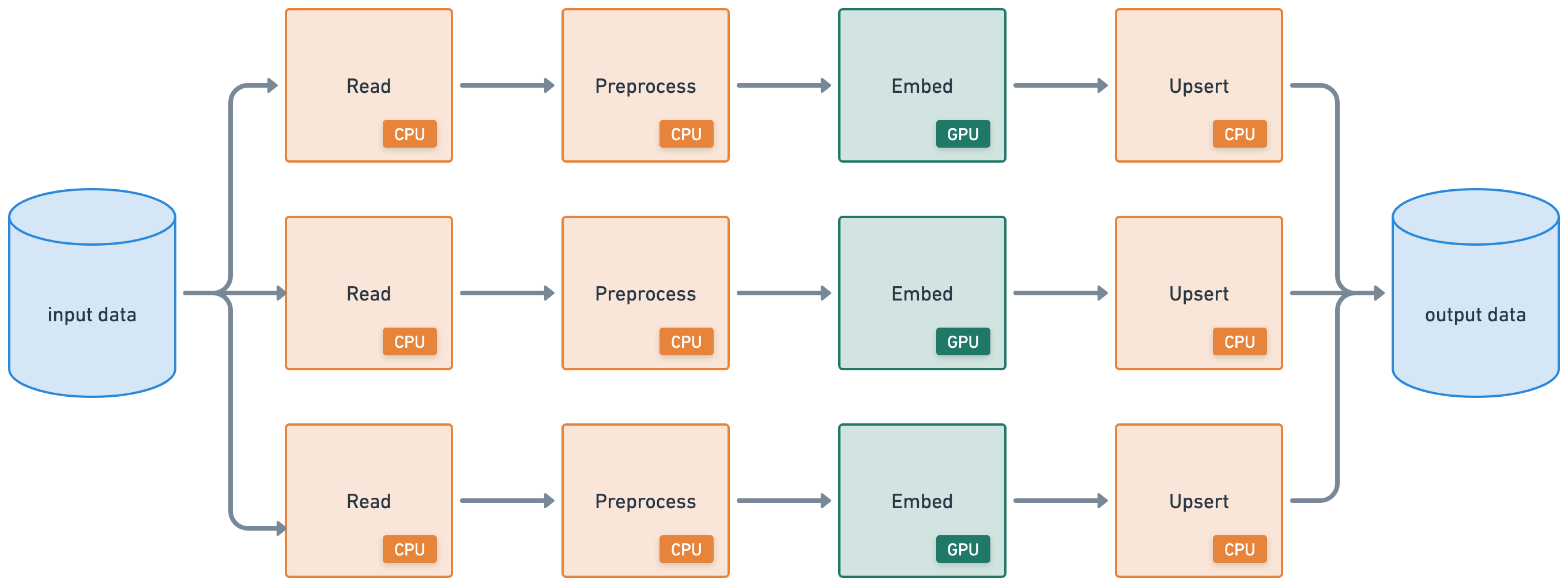
This tutorial executes a batch inference workload that connects the following heterogeneous workloads:
distributed read from cloud storage (CPU)
apply distributed preprocessing (CPU)
batch inference (GPU)
distributed write to cloud storage (CPU)
%%bash
pip install -q -r /home/ray/default/requirements.txt
pip install -q -e /home/ray/default/doggos
Successfully registered `ipywidgets, matplotlib` and 4 other packages to be installed on all cluster nodes.
View and update dependencies here: https://console.anyscale.com/cld_kvedZWag2qA8i5BjxUevf5i7/prj_cz951f43jjdybtzkx1s5sjgz99/workspaces/expwrk_23ry3pgfn3jgq2jk3e5z25udhz?workspace-tab=dependencies
Successfully registered `doggos` package to be installed on all cluster nodes.
View and update dependencies here: https://console.anyscale.com/cld_kvedZWag2qA8i5BjxUevf5i7/prj_cz951f43jjdybtzkx1s5sjgz99/workspaces/expwrk_23ry3pgfn3jgq2jk3e5z25udhz?workspace-tab=dependencies
Note: A kernel restart may be required for all dependencies to become available.
If using uv, then:
Turn off the runtime dependencies (
Dependenciestab up top > Toggle offPip packages). And no need to run thepip installcommands above.Change the python kernel of this notebook to use the
venv(Click onbase (Python x.yy.zz)on top right cordern of notebook >Select another Kernel>Python Environments...>Create Python Environment>Venv>Use Existing) and done! Now all the notebook’s cells will use the virtual env.Change the py executable to use
uv runinstead ofpythonby adding this line after importing ray.
import os
os.environ.pop("RAY_RUNTIME_ENV_HOOK", None)
import ray
ray.init(runtime_env={"py_executable": "uv run", "working_dir": "/home/ray/default"})
%load_ext autoreload
%autoreload all
import os
import ray
import sys
sys.path.append(os.path.abspath("../doggos/"))
# If using UV
# os.environ.pop("RAY_RUNTIME_ENV_HOOK", None)
# ray.init(runtime_env={"py_executable": "uv run", "working_dir": "/home/ray/default"})
from doggos import utils
Data ingestion#
Start by reading the data from a public cloud storage bucket.
# Load data.
ds = ray.data.read_images(
"s3://doggos-dataset/train",
include_paths=True,
shuffle="files",
)
ds.take(1)
2025-08-28 05:00:43,606 INFO worker.py:1771 -- Connecting to existing Ray cluster at address: 10.0.17.148:6379...
2025-08-28 05:00:43,617 INFO worker.py:1942 -- Connected to Ray cluster. View the dashboard at https://session-jhxhj69d6ttkjctcxfnsfe7gwk.i.anyscaleuserdata.com
2025-08-28 05:00:43,621 INFO packaging.py:588 -- Creating a file package for local module '/home/ray/default/doggos/doggos'.
2025-08-28 05:00:43,625 INFO packaging.py:380 -- Pushing file package 'gcs://_ray_pkg_7400f2bea399eebc.zip' (0.02MiB) to Ray cluster...
2025-08-28 05:00:43,625 INFO packaging.py:393 -- Successfully pushed file package 'gcs://_ray_pkg_7400f2bea399eebc.zip'.
2025-08-28 05:00:43,628 INFO packaging.py:380 -- Pushing file package 'gcs://_ray_pkg_a31dca6092632244a5c9467084f1b1f8df982200.zip' (1.10MiB) to Ray cluster...
2025-08-28 05:00:43,634 INFO packaging.py:393 -- Successfully pushed file package 'gcs://_ray_pkg_a31dca6092632244a5c9467084f1b1f8df982200.zip'.
2025-08-28 05:00:48,035 INFO dataset.py:3248 -- Tip: Use `take_batch()` instead of `take() / show()` to return records in pandas or numpy batch format.
2025-08-28 05:00:48,039 INFO logging.py:295 -- Registered dataset logger for dataset dataset_1_0
2025-08-28 05:00:48,101 INFO streaming_executor.py:159 -- Starting execution of Dataset dataset_1_0. Full logs are in /tmp/ray/session_2025-08-28_04-57-43_348032_12595/logs/ray-data
2025-08-28 05:00:48,102 INFO streaming_executor.py:160 -- Execution plan of Dataset dataset_1_0: InputDataBuffer[Input] -> TaskPoolMapOperator[ListFiles] -> LimitOperator[limit=1] -> TaskPoolMapOperator[ReadFiles]
2025-08-28 05:00:48,137 WARNING resource_manager.py:134 -- ⚠️ Ray's object store is configured to use only 27.3% of available memory (8.7GiB out of 32.0GiB total). For optimal Ray Data performance, we recommend setting the object store to at least 50% of available memory. You can do this by setting the 'object_store_memory' parameter when calling ray.init() or by setting the RAY_DEFAULT_OBJECT_STORE_MEMORY_PROPORTION environment variable.
2025-08-28 05:00:52,084 INFO streaming_executor.py:279 -- ✔️ Dataset dataset_1_0 execution finished in 3.98 seconds
[{'image': array([[[ 71, 93, 81],
[ 71, 93, 81],
[ 71, 91, 79],
...,
[ 99, 129, 137],
[101, 131, 139],
[102, 132, 140]],
[[ 61, 81, 70],
[ 61, 81, 70],
[ 61, 81, 69],
...,
[ 93, 123, 131],
[ 96, 125, 133],
[ 97, 127, 135]],
[[ 51, 68, 58],
[ 51, 68, 58],
[ 50, 68, 56],
...,
[ 82, 111, 117],
[ 85, 112, 119],
[ 86, 115, 121]],
...,
[[ 83, 101, 103],
[ 83, 101, 103],
[ 84, 102, 106],
...,
[ 94, 82, 56],
[ 97, 85, 59],
[ 99, 87, 61]],
[[ 82, 100, 102],
[ 82, 100, 102],
[ 83, 101, 105],
...,
[ 95, 83, 57],
[ 98, 86, 60],
[ 99, 87, 61]],
[[ 85, 100, 103],
[ 85, 100, 103],
[ 83, 101, 103],
...,
[ 95, 84, 56],
[ 99, 88, 60],
[100, 89, 61]]], dtype=uint8),
'path': 'doggos-dataset/train/malamute/malamute_11814.jpg'}]
Ray Data supports a wide range of data sources for both loading and saving from generic binary files in cloud storage to structured data formats used by modern data platforms. This example reads data from a public S3 bucket prepared with the dataset. This read operation, much like the write operation in a later step, runs in a distributed fashion. As a result, Ray Data processes the data in parallel across the cluster and doesn’t need to load the data entirely into memory at once, making data loading scalable and memory-efficient.
trigger lazy execution: use
taketo trigger the execution because Ray has lazy execution mode, which decreases execution time and memory utilization. But, this approach means that you need an operation like take, count, write, etc., to actually execute the workflow DAG.shuffling strategies: to shuffle the dataset because it’s all ordered by class, randomly shuffle the ordering of input files before reading. Ray Data also provides an extensive list of shuffling strategies such as local shuffles, per-epoch shuffles, etc.
materializeduring development: usematerializeto execute and materialize the dataset into Ray’s shared memory object store memory. This way, you save a checkpoint at this point and future operations on the dataset can start from this point. You won’t rerun all operations on the dataset again from scratch. This feature is convenient during development, especially in a stateful environment like Jupyter notebooks, because you can run from saved checkpoints.ds = ds.map(...) ds = ds.materialize()
Note: only use this during development and use it with small datasets, as it will load it all into memory.
You also want to add the class for each data point. When reading the data with include_paths Ray Data saves the filename with each data point. The filename has the class label in it so add that to each data point’s row. Use Ray Data’s map function to apply the function to each row.
def add_class(row):
row["class"] = row["path"].rsplit("/", 3)[-2]
return row
# Add class.
ds = ds.map(add_class)
❌ Traditional batch execution, for example, non-streaming like Spark without pipelining, SageMaker Batch Transform:
Reads the entire dataset into memory or a persistent intermediate format.
Only then starts applying transformations like .map, .filter, etc.
Higher memory pressure and startup latency.
✅ Streaming execution with Ray Data:
Starts processing chunks (“blocks”) as they’re loaded. No need to wait for entire dataset to load.
Reduces memory footprint (no OOMs) and speeds up time to first output.
Increase resource utilization by reducing idle time.
Online-style inference pipelines with minimal latency.
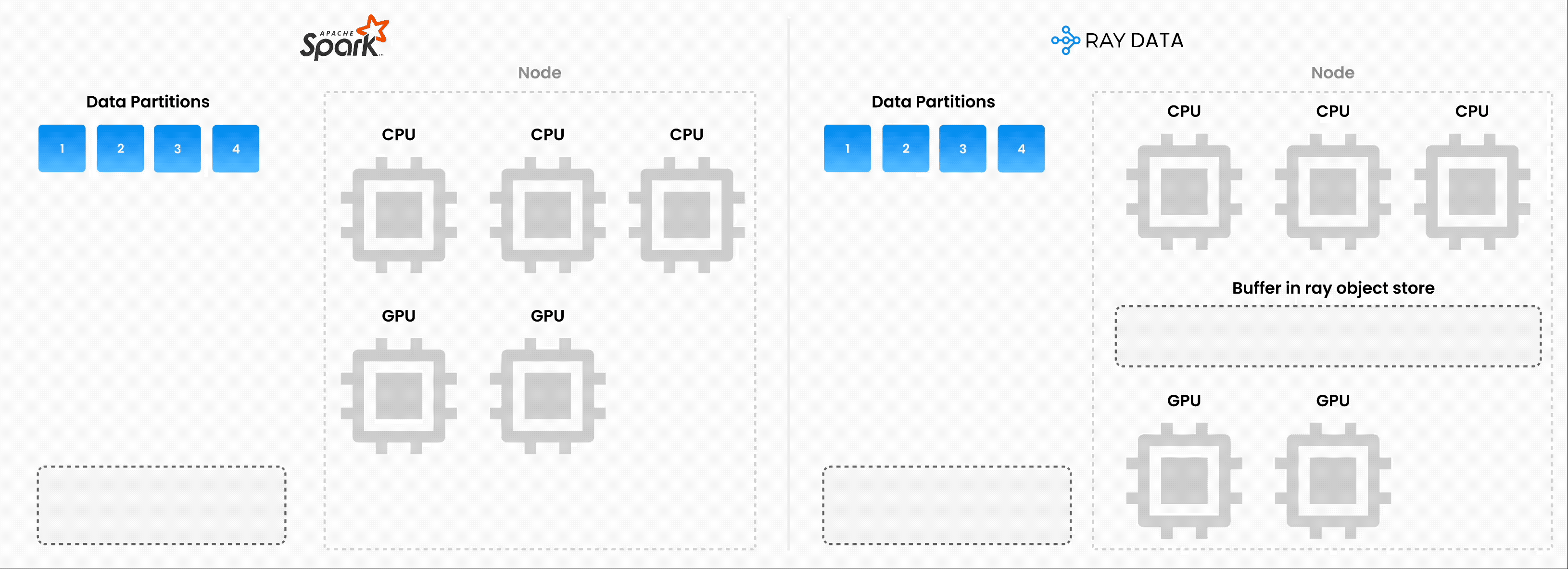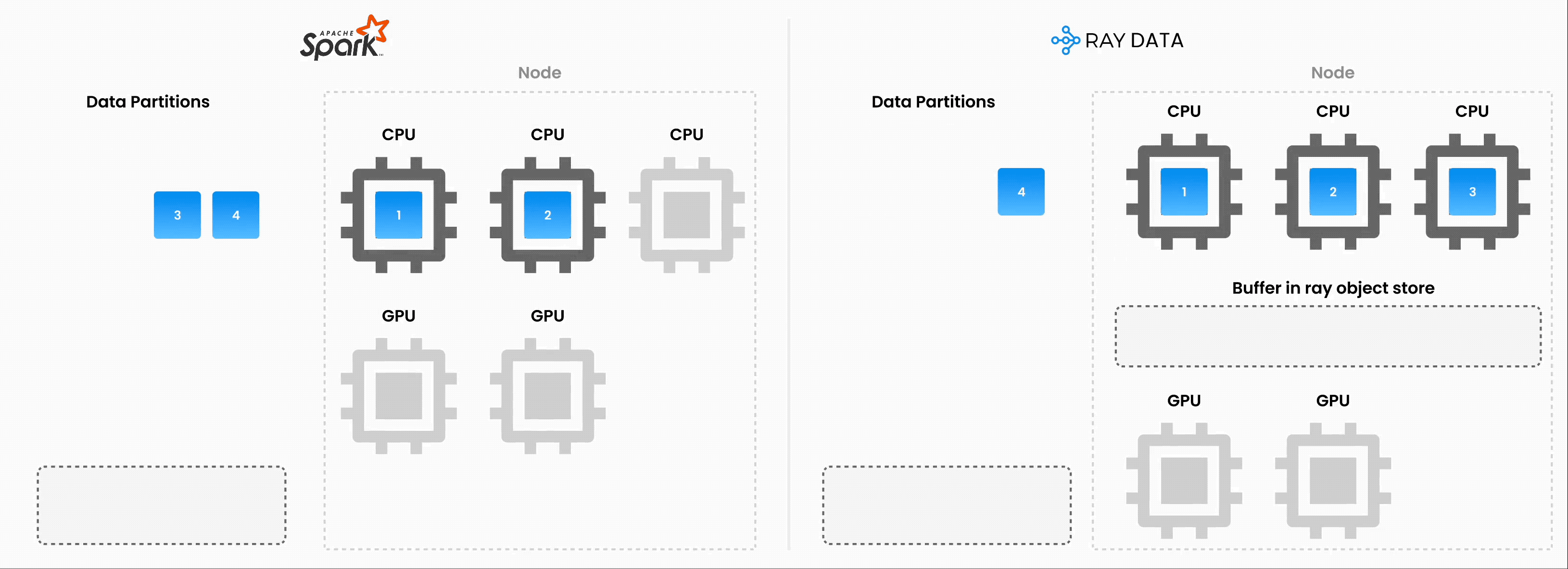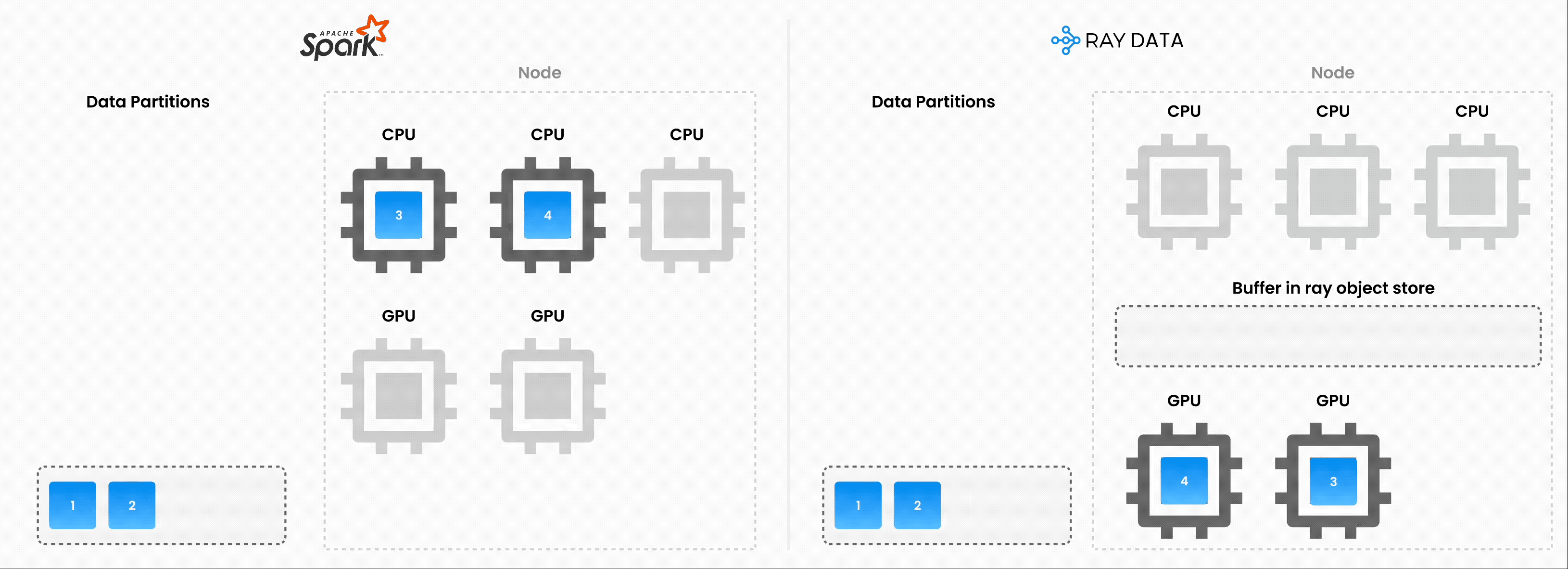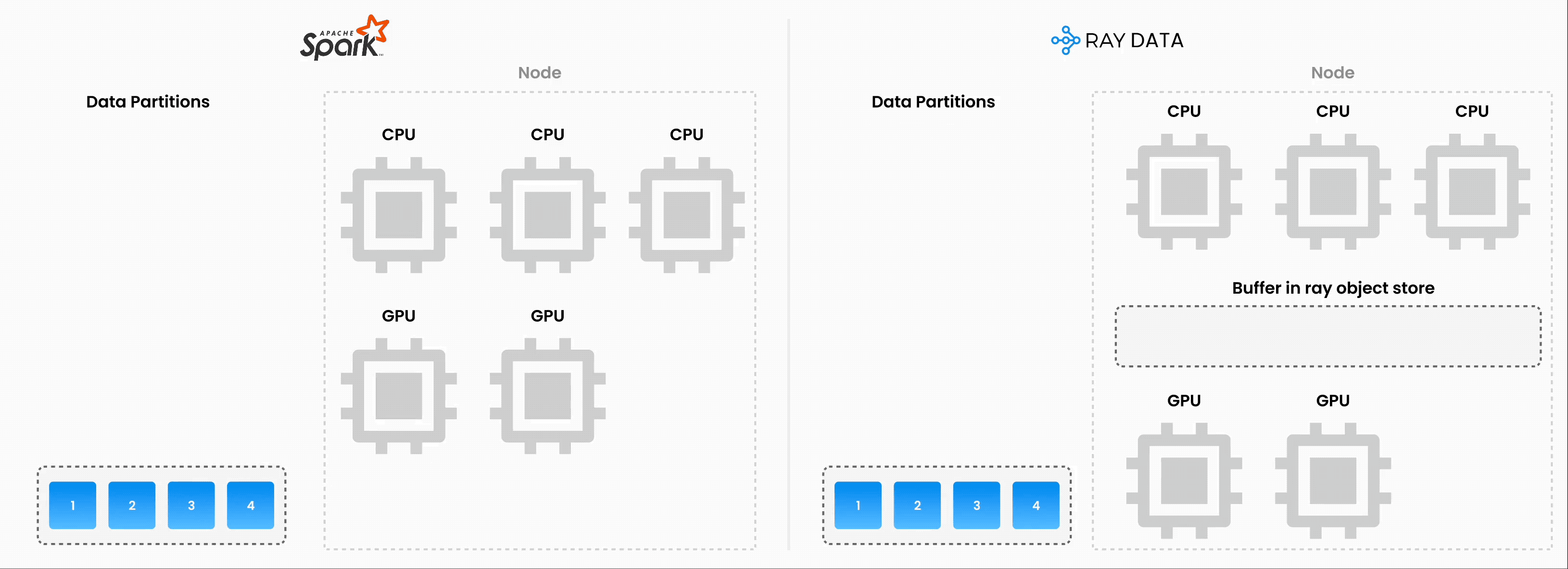
Note: Ray Data isn’t a real-time stream processing engine like Flink or Kafka Streams. Instead, it’s batch processing with streaming execution, which is especially useful for iterative ML workloads, ETL pipelines, and preprocessing before training or inference. Ray typically has a 2-17x throughput improvement over solutions like Spark and SageMaker Batch Transform, etc.
Batch embeddings#
The previous section applied a mapping operation using a function to each row in the dataset. Now you’re ready to generate embeddings from the data and using Ray Data’s map_batches to apply an operation across batches of the data. The operation is in the form of a callable, which is a function or a class with a __call__ method.
import numpy as np
from PIL import Image
import torch
from transformers import CLIPModel, CLIPProcessor
class EmbedImages(object):
def __init__(self, model_id, device):
# Load CLIP model and processor
self.processor = CLIPProcessor.from_pretrained(model_id)
self.model = CLIPModel.from_pretrained(model_id)
self.model.to(device)
self.device = device
def __call__(self, batch):
# Load and preprocess images
images = [Image.fromarray(np.uint8(img)).convert("RGB") for img in batch["image"]]
inputs = self.processor(images=images, return_tensors="pt", padding=True).to(self.device)
# Generate embeddings
with torch.inference_mode():
batch["embedding"] = self.model.get_image_features(**inputs).cpu().numpy()
return batch
Instead of initializing the same model for each instance of the class above, we can instead use references to Ray’s shared memory object store. We can load the model once, store it inside the default object store and then have each instance of our class refer to it.
model = load_model(...)
model_ref = ray.put(model)
class Foo:
def __init__(self, model_ref):
self.model = ray.get(model_ref)
...
# Generate batch embeddings
embeddings_ds = ds.map_batches(
EmbedImages,
fn_constructor_kwargs={
"model_id": "openai/clip-vit-base-patch32",
"device": "cuda",
}, # class kwargs
fn_kwargs={}, # __call__ kwargs
compute=ray.data.ActorPoolStrategy(size=4),
batch_size=64,
num_gpus=1,
accelerator_type="T4",
)
embeddings_ds = embeddings_ds.drop_columns(["image"]) # remove image column
Ray Data#
Ray Data not only makes it extremely easy to distribute workloads but also ensures that they with:
efficiency: minimize CPU/GPU idle time with heterogeneous resource scheduling.
scalability: streaming execution to petabyte-scale datasets, especially when working with LLMs
reliability by checkpointing processes, especially when running workloads on spot instances with on-demand fallback.
flexibility: connect to data from any source, apply transformations, and save to any format or location for your next workload.
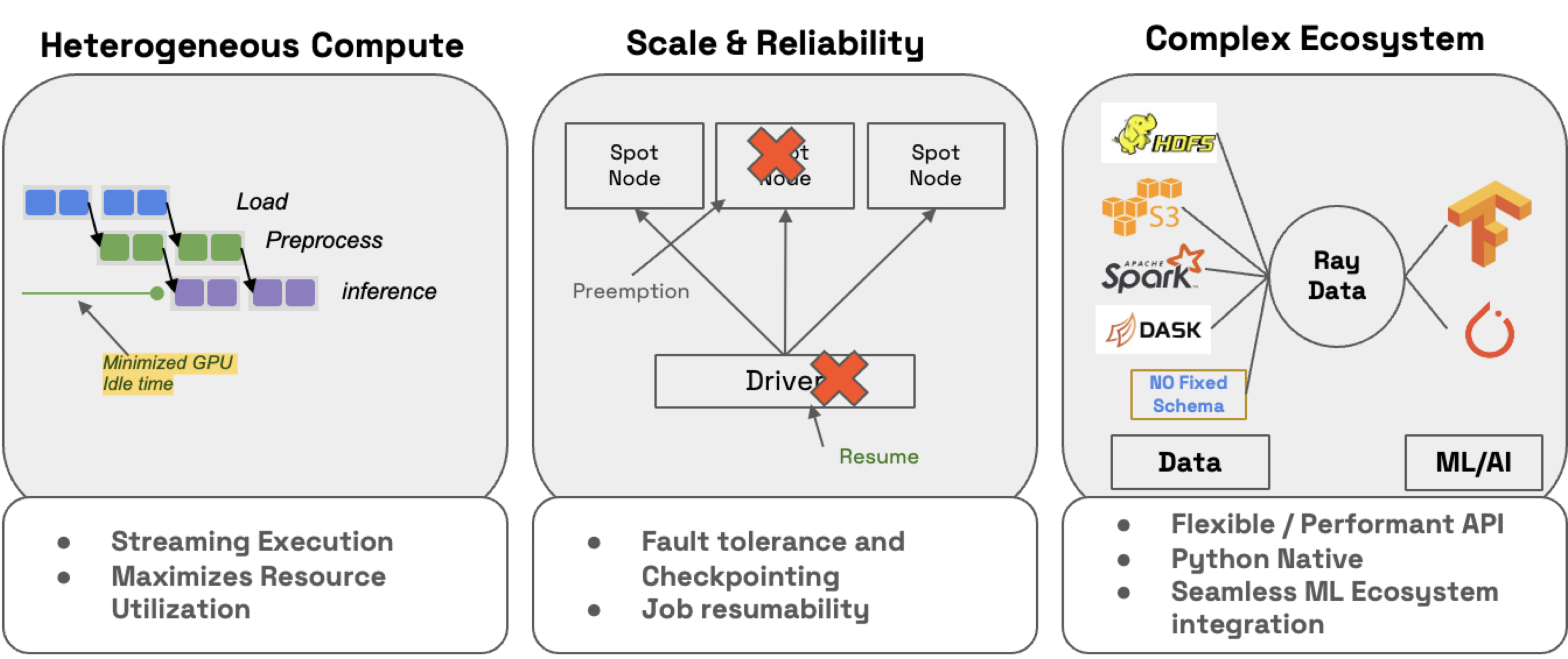
🔥 RayTurbo Data has more functionality on top of Ray Data:
accelerated metadata fetching to improve reading from large datasets (start processes earlier).
optimized autoscaling where actor pools are scaled up faster, start jobs before entire cluster is ready, etc.
high reliability where entire fails jobs (even on spot instances), like head node, cluster, uncaptured exceptions, etc., can resume from checkpoints. OSS Ray can only recover from worker node failures.
Data storage#
import shutil
# Save to artifact storage.
embeddings_path = os.path.join("/mnt/cluster_storage", "doggos/embeddings")
if os.path.exists(embeddings_path):
shutil.rmtree(embeddings_path) # clean up
embeddings_ds.write_parquet(embeddings_path)
2025-08-28 05:00:55,737 INFO logging.py:295 -- Registered dataset logger for dataset dataset_6_0
2025-08-28 05:00:55,756 INFO streaming_executor.py:159 -- Starting execution of Dataset dataset_6_0. Full logs are in /tmp/ray/session_2025-08-28_04-57-43_348032_12595/logs/ray-data
2025-08-28 05:00:55,757 INFO streaming_executor.py:160 -- Execution plan of Dataset dataset_6_0: InputDataBuffer[Input] -> TaskPoolMapOperator[ListFiles] -> TaskPoolMapOperator[ReadFiles] -> TaskPoolMapOperator[Map(add_class)] -> ActorPoolMapOperator[MapBatches(EmbedImages)] -> TaskPoolMapOperator[MapBatches(drop_columns)->Write]
{"asctime":"2025-08-28 05:00:55,808","levelname":"E","message":"Actor with class name: 'MapWorker(MapBatches(EmbedImages))' and ID: '1e923c76f6e2b92256b942a802000000' has constructor arguments in the object store and max_restarts > 0. If the arguments in the object store go out of scope or are lost, the actor restart will fail. See https://github.com/ray-project/ray/issues/53727 for more details.","filename":"core_worker.cc","lineno":2254}
(autoscaler +20s) Tip: use `ray status` to view detailed cluster status. To disable these messages, set RAY_SCHEDULER_EVENTS=0.
(autoscaler +20s) [autoscaler] [4xT4:48CPU-192GB] Attempting to add 1 node to the cluster (increasing from 0 to 1).
(autoscaler +25s) [autoscaler] [4xT4:48CPU-192GB|g4dn.12xlarge] [us-west-2a] [on-demand] Launched 1 instance.
2025-08-28 05:01:19,478 WARNING resource_manager.py:551 -- Cluster resources are not engough to run any task from ActorPoolMapOperator[MapBatches(EmbedImages)]. The job may hang forever unless the cluster scales up.
(autoscaler +1m10s) [autoscaler] Cluster upscaled to {56 CPU, 4 GPU}.
(MapWorker(MapBatches(EmbedImages)) pid=3337, ip=10.0.5.252) Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
2025-08-28 05:03:39,362 INFO streaming_executor.py:279 -- ✔️ Dataset dataset_6_0 execution finished in 163.60 seconds
2025-08-28 05:03:39,422 INFO dataset.py:4871 -- Data sink Parquet finished. 2880 rows and 5.8MB data written.
You can always store to the data inside any storage buckets but Anyscale offers a default storage bucket to make things easier. You also have plenty of other storage options as well, for example, shared at the cluster, user and cloud levels.
Note: ideally you would store these embeddings in a vector database like efficient search, filter, index, etc., but for this tutorial, just store to a shared file system.
Monitoring and Debugging#
While you’re developing out workloads, Ray offers logs and an observability dashboard that you can use to monitor and debug. The dashboard includes a lot of different components such as:
memory, utilization, etc., of the tasks running in the cluster
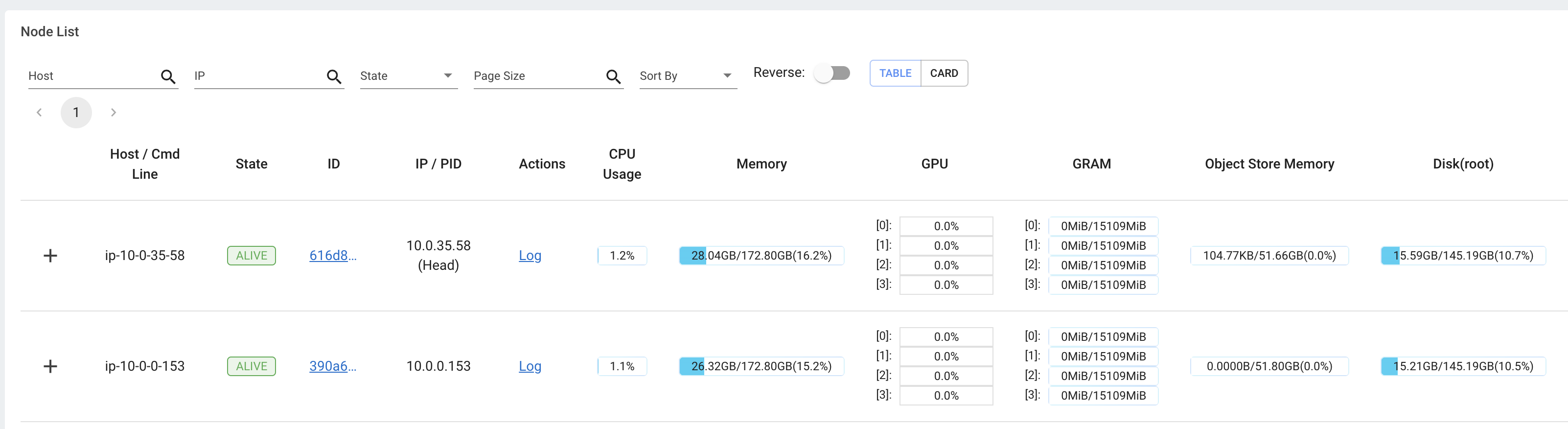
views to see all running tasks, utilization across instance types, autoscaling, etc.

🔥 While OSS Ray comes with an extensive observability suite, Anyscale takes it many steps further to make it easier and faster to monitor and debug workloads.
Ray workload specific dashboard, like Data, Train, etc., that can breakdown the tasks
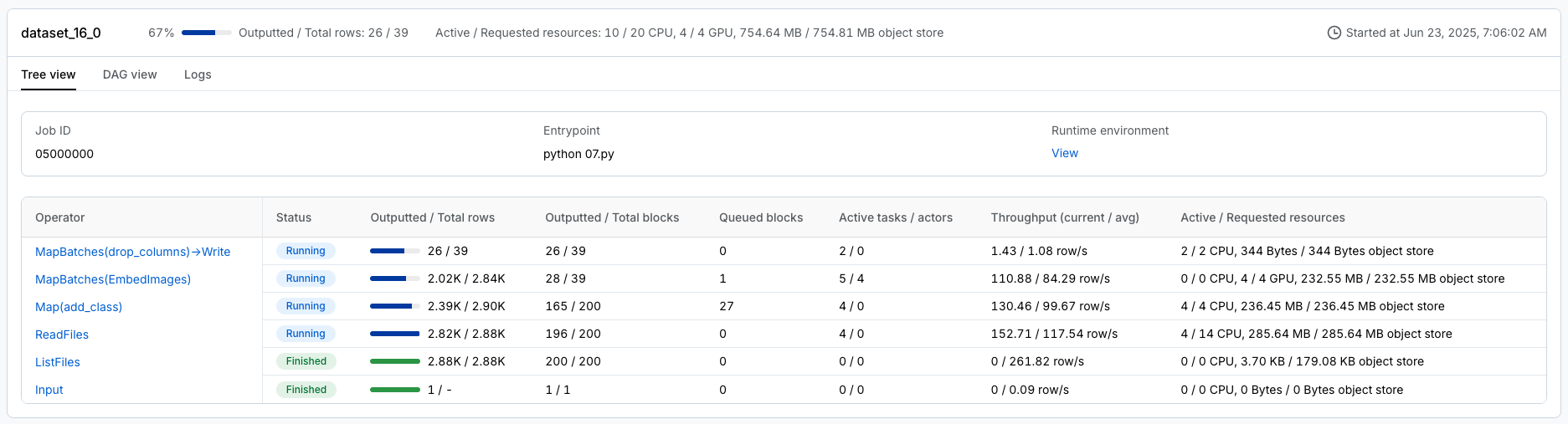
unified log viewer to see logs from all driver and worker processes
Production jobs#
Anyscale Jobs (API ref) allows you to execute discrete workloads in production such as batch inference, embeddings generation, or model fine-tuning.
define and manage Jobs in many different ways, including with a CLI or Python SDK.
set up all the observability, alerting, etc. around your Jobs.
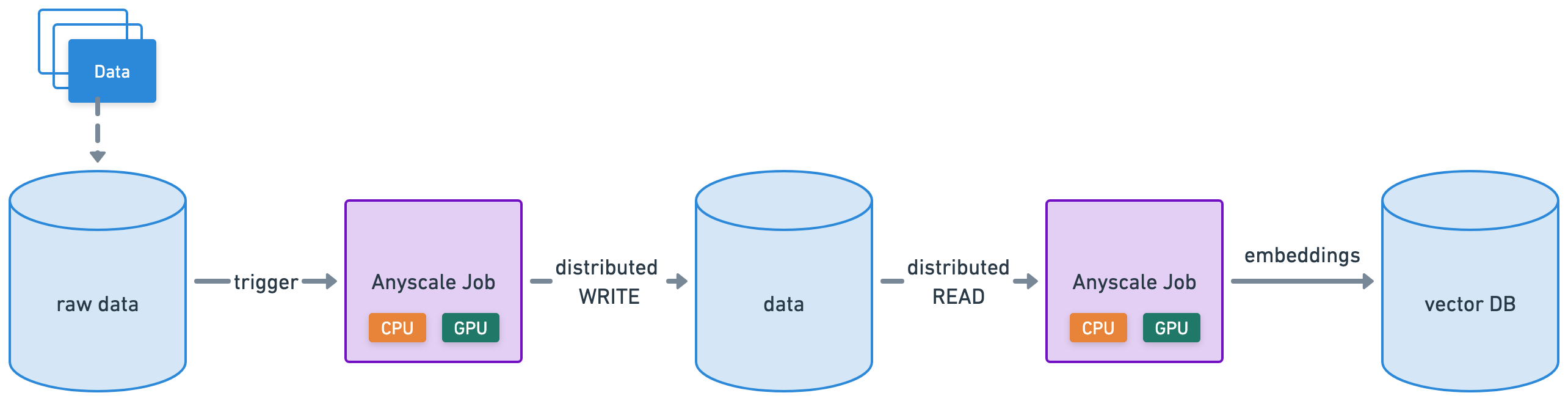
Wrap the batch embedding generation workload as an Anyscale Job by providing the main command to run, python doggos/embed.py, and the appropriate compute and dependencies required for it. Also set the working directory to the default directory so that the Job has access to all the files for the workload.
Note:
this step uses a
containerfileto define dependencies, but you could easily use a pre-built image as well.you can specify the compute as a compute config or inline in a job config file.
when you don’t specify compute while launching from a workspace, the configuration defaults to the compute configuration of the workspace.
and of course we can launch Jobs from anywhere (not just from within Workspaces) where we can specify the compute config and dependencies for the Job to use. Learn more on how to create and manage Jobs.
%%bash
# Production batch embedding generation job
anyscale job submit -f /home/ray/default/configs/generate_embeddings.yaml
Output
(anyscale +0.8s) Submitting job with config JobConfig(name='image-batch-embeddings', image_uri='anyscale/ray:2.48.0-slim-py312-cu128', compute_config=None, env_vars=None, py_modules=['/home/ray/default/doggos'], py_executable=None, cloud=None, project=None, ray_version=None, job_queue_config=None).
(anyscale +7.2s) Uploading local dir '/home/ray/default' to cloud storage.
(anyscale +7.9s) Uploading local dir '/home/ray/default/doggos' to cloud storage.
(anyscale +9.2s) Job 'image-batch-embeddings' submitted, ID: 'prodjob_7e1fsj9xzs2iryayj7hgbhifl8'.
(anyscale +9.2s) View the job in the UI: https://console.anyscale.com/jobs/prodjob_7e1fsj9xzs2iryayj7hgbhifl8
(anyscale +9.2s) Use `--wait` to wait for the job to run and stream logs.
Similar images#
Process a new image, embed it, and then retrieve the top similar images, based on embedding similarity (cosine), from the larger dataset of images you just computed batch embeddings for.
from io import BytesIO
from PIL import Image
import numpy as np
import requests
from doggos.embed import get_top_matches, display_top_matches
def url_to_array(url):
return np.array(Image.open(
BytesIO(requests.get(url).content)).convert("RGB"))
# Embed input image.
url = "https://doggos-dataset.s3.us-west-2.amazonaws.com/samara.png"
image = url_to_array(url=url)
embedding_generator = EmbedImages(model_id="openai/clip-vit-base-patch32", device="cpu")
embedding = embedding_generator({"image": [image]})["embedding"][0]
np.shape(embedding)
Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
(512,)
# Top matches by embedding similarity.
embeddings_ds = ray.data.read_parquet(embeddings_path)
top_matches = get_top_matches(embedding, embeddings_ds, n=5)
display_top_matches(url, top_matches)
/home/ray/anaconda3/lib/python3.12/site-packages/ray/data/_internal/datasource/parquet_datasource.py:750: FutureWarning: The default `file_extensions` for `read_parquet` will change from `None` to ['parquet'] after Ray 2.43, and your dataset contains files that don't match the new `file_extensions`. To maintain backwards compatibility, set `file_extensions=None` explicitly.
warnings.warn(
2025-08-28 05:03:56,303 INFO logging.py:295 -- Registered dataset logger for dataset dataset_8_0
2025-08-28 05:03:56,308 INFO streaming_executor.py:159 -- Starting execution of Dataset dataset_8_0. Full logs are in /tmp/ray/session_2025-08-28_04-57-43_348032_12595/logs/ray-data
2025-08-28 05:03:56,309 INFO streaming_executor.py:160 -- Execution plan of Dataset dataset_8_0: InputDataBuffer[Input] -> TaskPoolMapOperator[ListFiles] -> TaskPoolMapOperator[ReadFiles]
2025-08-28 05:03:57,382 INFO streaming_executor.py:279 -- ✔️ Dataset dataset_8_0 execution finished in 1.07 seconds

(autoscaler +7m14s) [autoscaler] [4xT4:48CPU-192GB] Attempting to add 1 node to the cluster (increasing from 1 to 2).
(autoscaler +7m14s) [autoscaler] [4xT4:48CPU-192GB|g4dn.12xlarge] [us-west-2a] [on-demand] Launched 1 instance.
(autoscaler +8m0s) [autoscaler] Cluster upscaled to {104 CPU, 8 GPU}.
🚨 Note: Reset this notebook using the “🔄 Restart” button location at the notebook’s menu bar. This way we can free up all the variables, utils, etc. used in this notebook.