Architecture overview#
Ray Serve LLM is a framework that specializes Ray Serve primitives for distributed LLM serving workloads. This guide explains the core components, serving patterns, and routing policies that enable scalable and efficient LLM inference.
What Ray Serve LLM provides#
Ray Serve LLM takes the performance of a single inference engine (such as vLLM) and extends it to support:
Horizontal scaling: Replicate inference across multiple GPUs on the same node or across nodes.
Advanced distributed strategies: Coordinate multiple engine instances for prefill-decode disaggregation, data parallel attention, and expert parallelism.
Modular deployment: Separate infrastructure logic from application logic for clean, maintainable deployments.
Ray Serve LLM excels at highly distributed multi-node inference workloads where the unit of scale spans multiple nodes:
Pipeline parallelism across nodes: Serve large models that don’t fit on a single node.
Disaggregated prefill and decode: Scale prefill and decode phases independently for better resource utilization.
Cluster-wide parallelism: Combine data parallel attention with expert parallelism for serving large-scale sparse MoE architectures such as Deepseek-v3, GPT OSS, etc.
Ray Serve primitives#
Before diving into the architecture, you should understand these Ray Serve primitives:
Deployment: A class that defines the unit of scale.
Replica: An instance of a deployment which corresponds to a Ray actor. Multiple replicas can be distributed across a cluster.
Deployment handle: An object that allows one replica to call into replicas of other deployments.
For more details, see the Ray Serve core concepts.
Core components#
Ray Serve LLM provides two primary components that work together to serve LLM workloads:
LLMServer#
LLMServer is a Ray Serve deployment that manages a single inference engine instance. Replicas of this deployment can operate in three modes:
Isolated: Each replica handles requests independently (horizontal scaling).
Coordinated within deployment: Multiple replicas work together (data parallel attention).
Coordinated across deployments: Replicas coordinate with different deployments (prefill-decode disaggregation).
The following example demonstrates the sketch of how to use LLMServer standalone:
from ray import serve
from ray.serve.llm import LLMConfig
from ray.serve.llm.deployment import LLMServer
llm_config = LLMConfig(...)
# Get deployment options (placement groups, etc.)
serve_options = LLMServer.get_deployment_options(llm_config)
# Decorate with serve options
server_cls = serve.deployment(LLMServer).options(
stream=True, **serve_options)
# Bind the decorated class to its constructor parameters
server_app = server_cls.bind(llm_config)
# Run the application
serve_handle = serve.run(server_app)
# Use the deployment handle
result = serve_handle.chat.remote(request=...).result()
Physical placement#
LLMServer controls physical placement of its constituent actors through placement groups. By default, it uses:
{CPU: 1}for the replica actor itself (no GPU resources).world_sizenumber of{GPU: 1}bundles for the GPU workers.
The world_size is computed as tensor_parallel_size × pipeline_parallel_size. The vLLM engine allocates TP and PP ranks based on bundle proximity, prioritizing TP ranks on the same node.
The PACK strategy tries to place all resources on a single node, but provisions different nodes when necessary. This works well for most deployments, though heterogeneous model deployments might occasionally run TP across nodes.
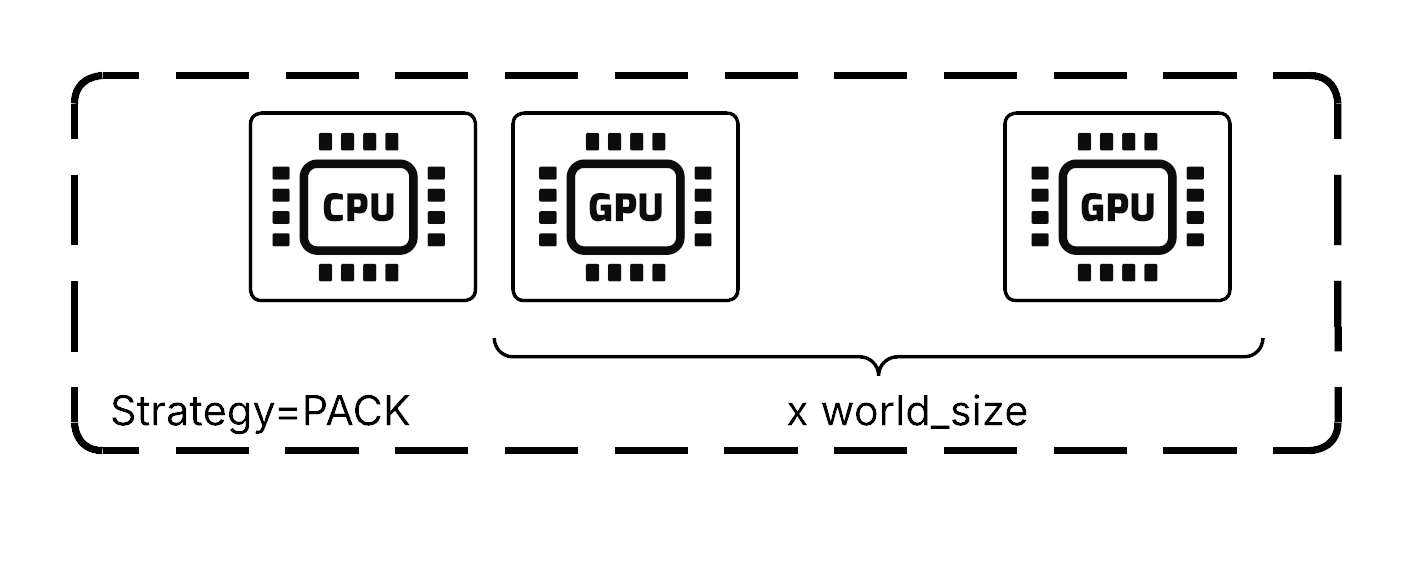
Physical placement strategy for GPU workers#
Engine management#
When LLMServer starts, it:
Creates a vLLM engine client.
Spawns a background process that uses Ray’s distributed executor backend.
Uses the parent actor’s placement group to instantiate child GPU worker actors.
Executes the model’s forward pass on these GPU workers.
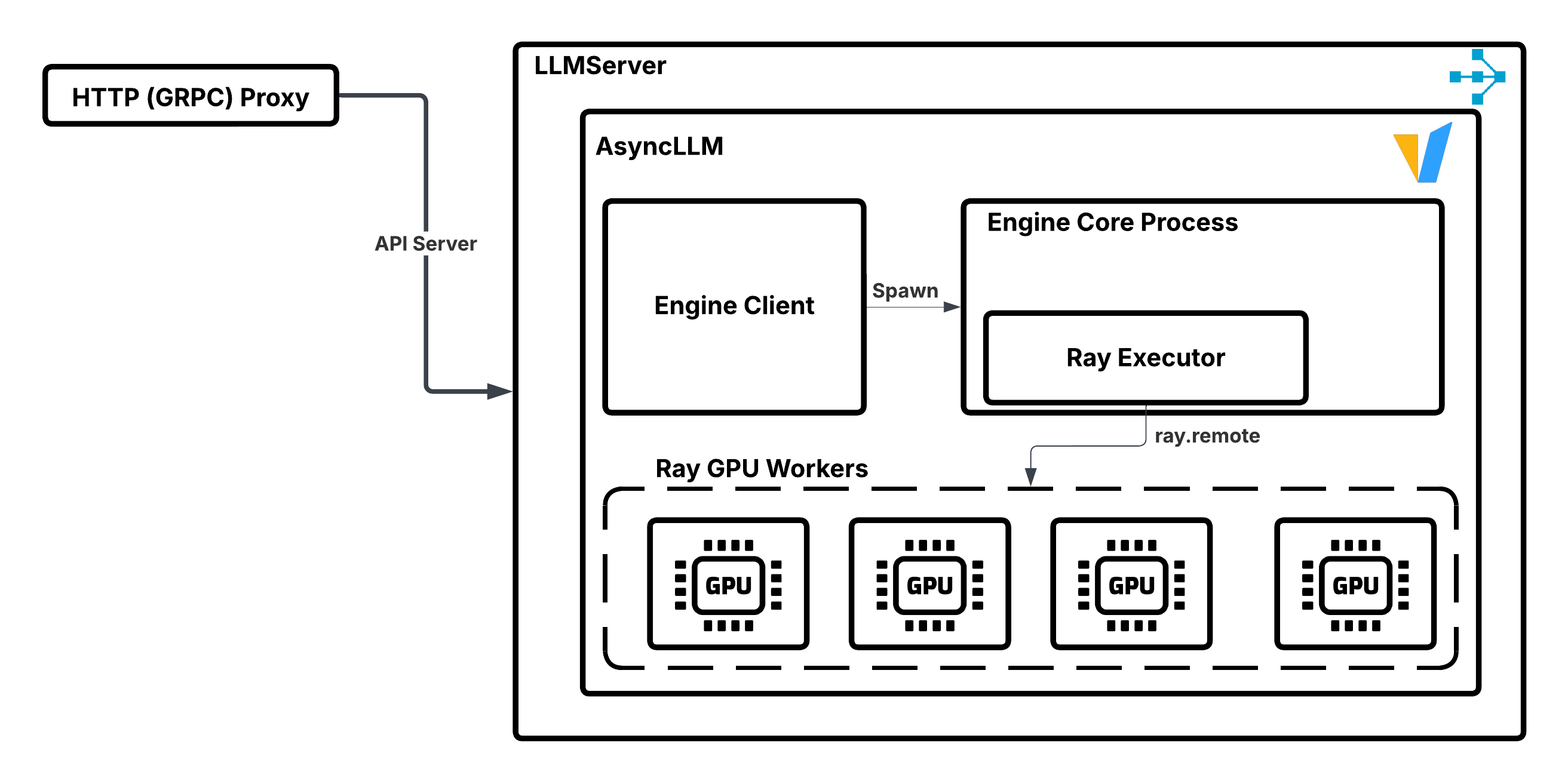
Illustration of LLMServer managing vLLM engine instance.#
OpenAiIngress#
OpenAiIngress provides an OpenAI-compatible FastAPI ingress that routes traffic to the appropriate model. It handles:
Standard endpoint definitions:
/v1/chat/completions,/v1/completions,/v1/embeddings, etc.Request routing logic: The execution of custom router logic (for example, prefix-aware or session-aware routing).
Model multiplexing: LoRA adapter management and routing.
The following example shows a complete deployment with OpenAiIngress:
from ray import serve
from ray.serve.llm import LLMConfig
from ray.serve.llm.deployment import LLMServer
from ray.serve.llm.ingress import OpenAiIngress, make_fastapi_ingress
llm_config = LLMConfig(...)
# Construct the LLMServer deployment
serve_options = LLMServer.get_deployment_options(llm_config)
server_cls = serve.deployment(LLMServer).options(**serve_options)
llm_server = server_cls.bind(llm_config)
# Get ingress default options
ingress_options = OpenAiIngress.get_deployment_options([llm_config])
# Decorate with FastAPI app
ingress_cls = make_fastapi_ingress(OpenAiIngress)
# Make it a serve deployment with the right options
ingress_cls = serve.deployment(ingress_cls, **ingress_options)
# Bind with llm_server deployment handle
ingress_app = ingress_cls.bind([llm_server])
# Run the application
serve.run(ingress_app)
Note
You can create your own ingress deployments and connect them to existing LLMServer deployments. This is useful when you want to customize request tracing, authentication layers, etc.
Network topology and RPC patterns#
When the ingress makes an RPC call to LLMServer through the deployment handle, it can reach any replica across any node. However, the default request router prioritizes replicas on the same node to minimize cross-node RPC overhead, which is insignificant in LLM serving applications (only a few milliseconds impact on TTFT at high concurrency).
The following figure illustrates the data flow:
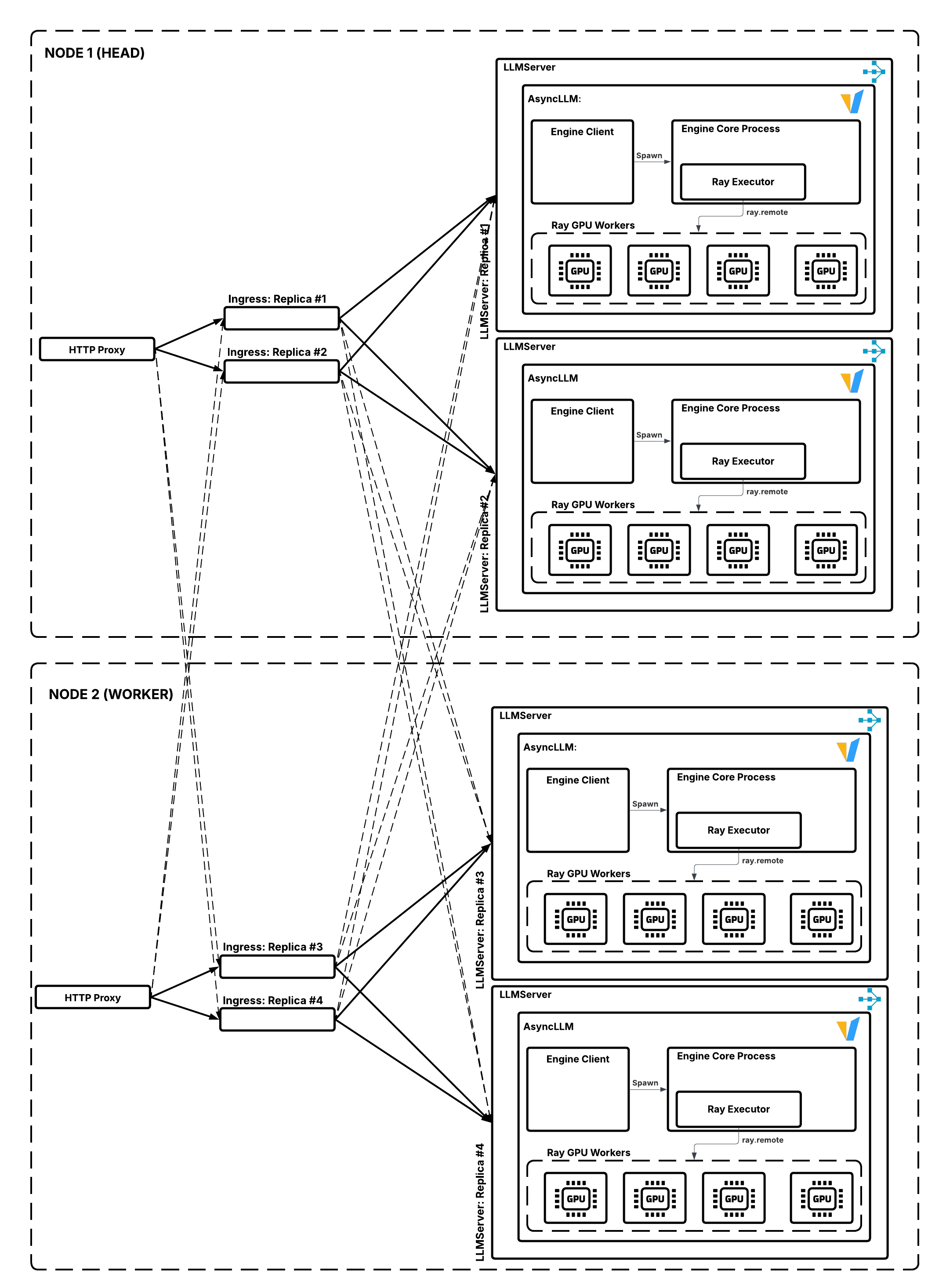
Request routing from ingress to LLMServer replicas. Solid lines represent preferred local RPC calls; dashed lines represent potential cross-node RPC calls when local replicas are busy.#
Scaling considerations#
Ingress-to-LLMServer ratio: The ingress event loop can become the bottleneck at high concurrency. In such situations, upscaling the number of ingress replicas can mitigate CPU contention. We recommend keeping at least a 2:1 ratio between the number of ingress replicas and LLMServer replicas. This architecture allows the system to dynamically scale the component that is the bottleneck.
Autoscaling coordination: To maintain proper ratios during autoscaling, configure target_ongoing_requests proportionally:
Profile your vLLM configuration to find the maximum concurrent requests (for example, 64 requests).
Choose an ingress-to-LLMServer ratio (for example, 2:1).
Set LLMServer’s
target_ongoing_requeststo say 75% of max capacity (for example, 48).Set ingress’s
target_ongoing_requeststo maintain the ratio (for example, 24).
Architecture patterns#
Ray Serve LLM supports several deployment patterns for different scaling scenarios:
Data parallel attention pattern#
Create multiple inference engine instances that process requests in parallel while coordinating across expert layers and sharding requests across attention layers. Useful for serving sparse MoE models for high-throughput workloads.
When to use: High request volume, kv-cache limited, need to maximize throughput.
Prefill-decode disaggregation#
Separate prefill and decode phases to optimize resource utilization and scale each phase independently.
When to use: Prefill-heavy workloads where there’s tension between prefill and decode, cost optimization with different GPU types.
Custom request routing#
Implement custom routing logic for specific optimization goals such as cache locality or session affinity.
When to use: Workloads with repeated prompts, session-based interactions, or specific routing requirements.
See: Request routing
Design principles#
Ray Serve LLM follows these key design principles:
Engine-agnostic: Support multiple inference engines (vLLM, SGLang, etc.) through the
LLMEngineprotocol.Composable patterns: Combine serving patterns (data parallel attention, prefill-decode, custom routing) for complex deployments.
Builder pattern: Use builders to construct complex deployment graphs declaratively.
Separation of concerns: Keep infrastructure logic (placement, scaling) separate from application logic (routing, processing).
Protocol-based extensibility: Define clear protocols for engines, servers, and ingress to enable custom implementations.
See also#
Core components - Technical implementation details and extension points
Serving patterns - Detailed serving pattern documentation
Request routing - Request routing architecture and patterns
User guides - Practical deployment guides