Distributed training of an XGBoost model#

This tutorial executes a distributed training workload that connects the following steps with heterogeneous compute requirements:
Preprocessing the dataset with Ray Data
Distributed training of an XGBoost model with Ray Train
Saving model artifacts to a model registry with MLflow
Note: This tutorial doesn’t including tuning of the model. See Ray Tune for experiment execution and hyperparameter tuning.

Dependencies#
To install the dependencies, run the following:
pip install -r requirements.txt
Setup#
Import the necessary modules:
%load_ext autoreload
%autoreload all
# Enable importing from dist_xgboost module.
import os
import sys
sys.path.append(os.path.abspath(".."))
# Enable Ray Train v2. This is the default in an upcoming release.
os.environ["RAY_TRAIN_V2_ENABLED"] = "1"
# Now it's safe to import from ray.train
import ray
from dist_xgboost.constants import storage_path, preprocessor_path
# Make Ray data less verbose.
ray.data.DataContext.get_current().enable_progress_bars = False
ray.data.DataContext.get_current().print_on_execution_start = False
Dataset preparation#
This example uses the Breast Cancer Wisconsin (Diagnostic) dataset, which contains features computed from digitized images of breast mass cell nuclei.
Split the data into:
70% for training
15% for validation
15% for testing
from ray.data import Dataset
def prepare_data() -> tuple[Dataset, Dataset, Dataset]:
"""Load and split the dataset into train, validation, and test sets."""
# Load the dataset from S3.
dataset = ray.data.read_csv("s3://anonymous@air-example-data/breast_cancer.csv")
seed = 42
# Split 70% for training.
train_dataset, rest = dataset.train_test_split(test_size=0.3, shuffle=True, seed=seed)
# Split the remaining 30% into 15% validation and 15% testing.
valid_dataset, test_dataset = rest.train_test_split(test_size=0.5, shuffle=True, seed=seed)
return train_dataset, valid_dataset, test_dataset
# Load and split the dataset.
train_dataset, valid_dataset, _test_dataset = prepare_data()
train_dataset.take(1)
2025-04-16 21:01:53,956 INFO worker.py:1660 -- Connecting to existing Ray cluster at address: 10.0.23.200:6379...
2025-04-16 21:01:53,966 INFO worker.py:1843 -- Connected to Ray cluster. View the dashboard at https://session-1kebpylz8tcjd34p4sv2h1f9tg.i.anyscaleuserdata.com
2025-04-16 21:01:53,972 INFO packaging.py:575 -- Creating a file package for local module '/home/ray/default/e2e-xgboost/dist_xgboost'.
2025-04-16 21:01:53,975 INFO packaging.py:367 -- Pushing file package 'gcs://_ray_pkg_aa0e5fd0ec6b8edc.zip' (0.02MiB) to Ray cluster...
2025-04-16 21:01:53,976 INFO packaging.py:380 -- Successfully pushed file package 'gcs://_ray_pkg_aa0e5fd0ec6b8edc.zip'.
2025-04-16 21:01:53,977 INFO packaging.py:367 -- Pushing file package 'gcs://_ray_pkg_38ec1ca756a7ccf23a0c590d356f26fc87860d8a.zip' (0.07MiB) to Ray cluster...
2025-04-16 21:01:53,978 INFO packaging.py:380 -- Successfully pushed file package 'gcs://_ray_pkg_38ec1ca756a7ccf23a0c590d356f26fc87860d8a.zip'.
(autoscaler +11s) Tip: use `ray status` to view detailed cluster status. To disable these messages, set RAY_SCHEDULER_EVENTS=0.
(autoscaler +11s) [autoscaler] [8CPU-32GB] Attempting to add 1 node(s) to the cluster (increasing from 0 to 1).
(autoscaler +11s) [autoscaler] [8CPU-32GB] Launched 1 instances.
2025-04-16 21:03:12,957 INFO dataset.py:2809 -- Tip: Use `take_batch()` instead of `take() / show()` to return records in pandas or numpy batch format.
[{'mean radius': 19.16,
'mean texture': 26.6,
'mean perimeter': 126.2,
'mean area': 1138.0,
'mean smoothness': 0.102,
'mean compactness': 0.1453,
'mean concavity': 0.1921,
'mean concave points': 0.09664,
'mean symmetry': 0.1902,
'mean fractal dimension': 0.0622,
'radius error': 0.6361,
'texture error': 1.001,
'perimeter error': 4.321,
'area error': 69.65,
'smoothness error': 0.007392,
'compactness error': 0.02449,
'concavity error': 0.03988,
'concave points error': 0.01293,
'symmetry error': 0.01435,
'fractal dimension error': 0.003446,
'worst radius': 23.72,
'worst texture': 35.9,
'worst perimeter': 159.8,
'worst area': 1724.0,
'worst smoothness': 0.1782,
'worst compactness': 0.3841,
'worst concavity': 0.5754,
'worst concave points': 0.1872,
'worst symmetry': 0.3258,
'worst fractal dimension': 0.0972,
'target': 0}]
Look at the output to see that the dataset contains features characterizing cell nuclei in breast mass, such as radius, texture, perimeter, area, smoothness, compactness, concavity, symmetry, and more.
Data preprocessing#
Notice that the features have different magnitudes and ranges. While tree-based models like XGBoost aren’t as sensitive to these differences, feature scaling can still improve numerical stability in some cases.
Ray Data has built-in preprocessors that simplify common feature preprocessing tasks, especially for tabular data. You can integrate these preprocessors with Ray Datasets, to preprocess data in a fault-tolerant and distributed way.
This example uses Ray’s built-in StandardScaler to zero-center and normalize the features:
from ray.data.preprocessors import StandardScaler
def train_preprocessor(train_dataset: ray.data.Dataset) -> StandardScaler:
# Pick some dataset columns to scale.
columns_to_scale = [c for c in train_dataset.columns() if c != "target"]
# Initialize the preprocessor.
preprocessor = StandardScaler(columns=columns_to_scale)
# Train the preprocessor on the training set.
preprocessor.fit(train_dataset)
return preprocessor
preprocessor = train_preprocessor(train_dataset)
Now that you’ve fit the preprocessor, save it to a file. Register this artifact later in MLflow so you can reuse it in downstream pipelines.
import pickle
with open(preprocessor_path, "wb") as f:
pickle.dump(preprocessor, f)
Next, transform the datasets using the fitted preprocessor. Note that the transform() operation is lazy. Ray Data won’t apply it to the data until the Ray Train workers require the data:
train_dataset = preprocessor.transform(train_dataset)
valid_dataset = preprocessor.transform(valid_dataset)
train_dataset.take(1)
[{'mean radius': 1.3883915483364895,
'mean texture': 1.6582900738074817,
'mean perimeter': 1.3686612092802328,
'mean area': 1.3271629358408426,
'mean smoothness': 0.3726369329455741,
'mean compactness': 0.7709391453349583,
'mean concavity': 1.2156484038771678,
'mean concave points': 1.1909841981870102,
'mean symmetry': 0.33295997290846857,
'mean fractal dimension': -0.07207903519571106,
'radius error': 0.8074600624242092,
'texture error': -0.3842391069975234,
'perimeter error': 0.6925593054563496,
'area error': 0.5852832746827147,
'smoothness error': 0.13331319500721583,
'compactness error': -0.03934175265392654,
'concavity error': 0.22009334597724586,
'concave points error': 0.16570998568362863,
'symmetry error': -0.7220900323187186,
'fractal dimension error': -0.13670701917436776,
'worst radius': 1.5076654048043645,
'worst texture': 1.6169142713721316,
'worst perimeter': 1.5267353447826646,
'worst area': 1.4332237868207693,
'worst smoothness': 1.993402211865443,
'worst compactness': 0.8646836438651355,
'worst concavity': 1.3882655471454963,
'worst concave points': 1.0898377217385602,
'worst symmetry': 0.5707716568830431,
'worst fractal dimension': 0.7444861349012516,
'target': 0}]
Using take(), to see that Ray Data zero-centered and rescaled the values to be roughly between -1 and 1.
Data processing note:
For more advanced data loading and preprocessing techniques, see the comprehensive guide. Ray Data also supports performant joins, filters, aggregations, and other operations for more structured data processing, if required.
Model training with XGBoost#
Checkpointing configuration#
Checkpointing is a powerful feature that enables you to resume training from the last checkpoint in case of interruptions. Checkpointing is particularly useful for long-running training sessions.
XGBoostTrainer implements checkpointing out of the box. Configure CheckpointConfig to set the checkpointing frequency.
from ray.train import CheckpointConfig, Result, RunConfig, ScalingConfig
# Configure checkpointing to save progress during training.
run_config = RunConfig(
checkpoint_config=CheckpointConfig(
# Checkpoint every 10 iterations.
checkpoint_frequency=10,
# Only keep the latest checkpoint.
num_to_keep=1,
),
## For multi-node clusters, configure storage that's accessible
## across all worker nodes with `storage_path="s3://..."`.
storage_path=storage_path,
)
Note: Once you enable checkpointing, you can follow this guide to enable fault tolerance.
Training with XGBoost#
Pass training parameters as a dictionary, similar to the original xgboost.train() function:
import xgboost
from ray.train.xgboost import RayTrainReportCallback, XGBoostTrainer
NUM_WORKERS = 4
USE_GPU = True
def train_fn_per_worker(config: dict):
"""Training function that runs on each worker.
This function:
1. Gets the dataset shard for this worker
2. Converts to pandas for XGBoost
3. Separates features and labels
4. Creates DMatrix objects
5. Trains the model using distributed communication
"""
# Get this worker's dataset shard.
train_ds, val_ds = (
ray.train.get_dataset_shard("train"),
ray.train.get_dataset_shard("validation"),
)
# Materialize the data and convert to pandas.
train_ds = train_ds.materialize().to_pandas()
val_ds = val_ds.materialize().to_pandas()
# Separate the labels from the features.
train_X, train_y = train_ds.drop("target", axis=1), train_ds["target"]
eval_X, eval_y = val_ds.drop("target", axis=1), val_ds["target"]
# Convert the data into DMatrix format for XGBoost.
dtrain = xgboost.DMatrix(train_X, label=train_y)
deval = xgboost.DMatrix(eval_X, label=eval_y)
# Do distributed data-parallel training.
# Ray Train sets up the necessary coordinator processes and
# environment variables for workers to communicate with each other.
_booster = xgboost.train(
config["xgboost_params"],
dtrain=dtrain,
evals=[(dtrain, "train"), (deval, "validation")],
num_boost_round=10,
# Handles metric logging and checkpointing.
callbacks=[RayTrainReportCallback()],
)
# Parameters for the XGBoost model.
model_config = {
"xgboost_params": {
"objective": "binary:logistic",
"eval_metric": ["logloss", "error"],
}
}
trainer = XGBoostTrainer(
train_fn_per_worker,
train_loop_config=model_config,
# Register the data subsets.
datasets={"train": train_dataset, "validation": valid_dataset},
# See "Scaling strategies" for more details.
scaling_config=ScalingConfig(
# Number of workers for data parallelism.
num_workers=NUM_WORKERS,
# Set to True to use GPU acceleration.
use_gpu=USE_GPU,
),
run_config=run_config,
)
Ray Train benefits:
Multi-node orchestration: Automatically handles multi-node, multi-GPU setup without manual SSH or hostfile configurations
Built-in fault tolerance: Supports automatic retry of failed workers and can continue from the last checkpoint
Flexible training strategies: Supports various parallelism strategies beyond just data parallel training
Heterogeneous cluster support: Define per-worker resource requirements and run on mixed hardware
Ray Train integrates with popular frameworks like PyTorch, TensorFlow, XGBoost, and more. For enterprise needs, RayTurbo Train offers additional features like elastic training, advanced monitoring, and performance optimization.

Next, train the model:
result: Result = trainer.fit()
result
(TrainController pid=19121) Attempting to start training worker group of size 5 with the following resources: [{'GPU': 1}] * 5
(autoscaler +1m31s) [autoscaler] [8xA10G:192CPU-768GB] Attempting to add 1 node(s) to the cluster (increasing from 0 to 1).
(autoscaler +1m31s) [autoscaler] Launching instances failed: NewInstances[g5.48xlarge;num:1;all:false]: could not launch any instances: api error Unsupported: Instance type g5.48xlarge is not supported in zone us-west-2d.
(autoscaler +1m31s) [autoscaler] [1xA10G:16CPU-64GB] Attempting to add 5 node(s) to the cluster (increasing from 0 to 5).
(autoscaler +1m31s) [autoscaler] Launching instances failed: NewInstances[g5.4xlarge;num:5;all:false]: could not launch any instances: api error Unsupported: Instance type g5.4xlarge is not supported in zone us-west-2d.
(autoscaler +1m31s) [autoscaler] [1xA10G:32CPU-128GB] Attempting to add 5 node(s) to the cluster (increasing from 0 to 5).
(autoscaler +1m36s) [autoscaler] Launching instances failed: NewInstances[g5.8xlarge;num:5;all:false]: could not launch any instances: api error Unsupported: Instance type g5.8xlarge is not supported in zone us-west-2d.
(autoscaler +1m36s) [autoscaler] [1xL4:4CPU-16GB] Attempting to add 1 node(s) to the cluster (increasing from 0 to 1).
(autoscaler +1m36s) [autoscaler] [4xL4:48CPU-192GB] Attempting to add 1 node(s) to the cluster (increasing from 0 to 1).
(autoscaler +1m36s) [autoscaler] [4xL4:48CPU-192GB] Launched 1 instances.
(autoscaler +1m36s) [autoscaler] [1xL4:4CPU-16GB] Launched 1 instances.
(TrainController pid=19121) Retrying the launch of the training worker group. The previous launch attempt encountered the following failure:
(TrainController pid=19121) The worker group startup timed out after 30.0 seconds waiting for 5 workers. Potential causes include: (1) temporary insufficient cluster resources while waiting for autoscaling (ignore this warning in this case), (2) infeasible resource request where the provided `ScalingConfig` cannot be satisfied), and (3) transient network issues. Set the RAY_TRAIN_WORKER_GROUP_START_TIMEOUT_S environment variable to increase the timeout.
(TrainController pid=19121) Attempting to start training worker group of size 5 with the following resources: [{'GPU': 1}] * 5
(autoscaler +2m21s) [autoscaler] Cluster upscaled to {12 CPU, 1 GPU}.
(TrainController pid=19121) Retrying the launch of the training worker group. The previous launch attempt encountered the following failure:
(TrainController pid=19121) The worker group startup timed out after 30.0 seconds waiting for 5 workers. Potential causes include: (1) temporary insufficient cluster resources while waiting for autoscaling (ignore this warning in this case), (2) infeasible resource request where the provided `ScalingConfig` cannot be satisfied), and (3) transient network issues. Set the RAY_TRAIN_WORKER_GROUP_START_TIMEOUT_S environment variable to increase the timeout.
(TrainController pid=19121) Attempting to start training worker group of size 5 with the following resources: [{'GPU': 1}] * 5
(autoscaler +2m31s) [autoscaler] Cluster upscaled to {60 CPU, 5 GPU}.
(raylet) WARNING: 4 PYTHON worker processes have been started on node: dc30e171b93f61245644ba4d0147f8b27f64e9e1eaf34d1bb63c9c99 with address: 10.0.23.200. This could be a result of using a large number of actors, or due to tasks blocked in ray.get() calls (see https://github.com/ray-project/ray/issues/3644 for some discussion of workarounds).
(RayTrainWorker pid=3285, ip=10.0.223.105) [21:04:38] Task [xgboost.ray-rank=00000002]:fa43387771ebd5738fd50b6303000000 got rank 2
(TrainController pid=19121) [21:04:42] [0] train-logloss:0.44514 train-error:0.04051 validation-logloss:0.43997 validation-error:0.04706
(TrainController pid=19121) [21:04:44] [1] train-logloss:0.31649 train-error:0.01772 validation-logloss:0.31594 validation-error:0.04706
(RayTrainWorker pid=2313, ip=10.0.223.33) [21:04:38] Task [xgboost.ray-rank=00000004]:a6ed8004330660f5a370531f03000000 got rank 4 [repeated 4x across cluster] (Ray deduplicates logs by default. Set RAY_DEDUP_LOGS=0 to disable log deduplication, or see https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#log-deduplication for more options.)
(TrainController pid=19121) [21:04:46] [2] train-logloss:0.23701 train-error:0.01266 validation-logloss:0.24072 validation-error:0.02353
(TrainController pid=19121) [21:04:48] [3] train-logloss:0.18165 train-error:0.00759 validation-logloss:0.19038 validation-error:0.01176
(TrainController pid=19121) [21:04:50] [4] train-logloss:0.14258 train-error:0.00759 validation-logloss:0.14917 validation-error:0.01176
(TrainController pid=19121) [21:04:52] [5] train-logloss:0.11360 train-error:0.00759 validation-logloss:0.12113 validation-error:0.01176
(TrainController pid=19121) [21:04:54] [6] train-logloss:0.09207 train-error:0.00759 validation-logloss:0.10018 validation-error:0.01176
(TrainController pid=19121) [21:04:56] [7] train-logloss:0.07616 train-error:0.00506 validation-logloss:0.08632 validation-error:0.01176
(TrainController pid=19121) [21:04:58] [8] train-logloss:0.06419 train-error:0.00506 validation-logloss:0.07705 validation-error:0.01176
(TrainController pid=19121) [21:05:00] [9] train-logloss:0.05463 train-error:0.00506 validation-logloss:0.06741 validation-error:0.01176
(RayTrainWorker pid=3284, ip=10.0.223.105) Checkpoint successfully created at: Checkpoint(filesystem=local, path=/mnt/user_storage/ray_train_run-2025-04-16_21-03-13/checkpoint_2025-04-16_21-05-00.160991)
Result(metrics=OrderedDict({'train-logloss': 0.05463397157248817, 'train-error': 0.00506329113924051, 'validation-logloss': 0.06741214815308066, 'validation-error': 0.01176470588235294}), checkpoint=Checkpoint(filesystem=local, path=/mnt/user_storage/ray_train_run-2025-04-16_21-03-13/checkpoint_2025-04-16_21-05-00.160991), error=None, path='/mnt/user_storage/ray_train_run-2025-04-16_21-03-13', metrics_dataframe= train-logloss train-error validation-logloss validation-error
0 0.054634 0.005063 0.067412 0.011765, best_checkpoints=[(Checkpoint(filesystem=local, path=/mnt/user_storage/ray_train_run-2025-04-16_21-03-13/checkpoint_2025-04-16_21-05-00.160991), OrderedDict({'train-logloss': 0.05463397157248817, 'train-error': 0.00506329113924051, 'validation-logloss': 0.06741214815308066, 'validation-error': 0.01176470588235294}))], _storage_filesystem=<pyarrow._fs.LocalFileSystem object at 0x7ea450adb130>)
At the beginning of the training job, Ray started requesting GPU nodes to satisfy the training job’s requirement of five GPU workers.
Ray Train returns a ray.train.Result object, which contains important properties such as metrics, checkpoint information, and error details:
metrics = result.metrics
metrics
OrderedDict([('train-logloss', 0.05463397157248817),
('train-error', 0.00506329113924051),
('validation-logloss', 0.06741214815308066),
('validation-error', 0.01176470588235294)])
The expected output are similar to the following:
OrderedDict([('train-logloss', 0.05463397157248817),
('train-error', 0.00506329113924051),
('validation-logloss', 0.06741214815308066),
('validation-error', 0.01176470588235294)])
See that the Ray Train logs metrics based on the values you configured in eval_metric and evals.
You can also reconstruct the trained model from the checkpoint directory:
booster = RayTrainReportCallback.get_model(result.checkpoint)
booster
<xgboost.core.Booster at 0x7ea4531beea0>
Model registry#
Now that you’ve trained the model, save it to a model registry for future use. As this is a distributed training workload, the model registry storage needs to be accessible from all workers in the cluster. This storage can be S3, NFS, or another network-attached solution. Anyscale simplifies this process by automatically creating and mounting shared storage options on every cluster node, ensuring that model artifacts are readable and writable across the distributed environment.
The MLflow tracking server stores experiment metadata and model artifacts in the shared storage location, making them available for future model serving, evaluation, or retraining workflows. Ray also integrates with other experiment trackers.
import shutil
from tempfile import TemporaryDirectory
import mlflow
from dist_xgboost.constants import (
experiment_name,
model_fname,
model_registry,
preprocessor_fname,
)
def clean_up_old_runs():
# Clean up old MLflow runs.
os.path.isdir(model_registry) and shutil.rmtree(model_registry)
# mlflow.delete_experiment(experiment_name)
os.makedirs(model_registry, exist_ok=True)
def log_run_to_mlflow(model_config, result, preprocessor_path):
# Create a model registry in user storage.
mlflow.set_tracking_uri(f"file:{model_registry}")
# Create a new experiment and log metrics and artifacts.
mlflow.set_experiment(experiment_name)
with mlflow.start_run(description="xgboost breast cancer classifier on all features"):
mlflow.log_params(model_config)
mlflow.log_metrics(result.metrics)
# Selectively log just the preprocessor and model weights.
with TemporaryDirectory() as tmp_dir:
shutil.copy(
os.path.join(result.checkpoint.path, model_fname),
os.path.join(tmp_dir, model_fname),
)
shutil.copy(
preprocessor_path,
os.path.join(tmp_dir, preprocessor_fname),
)
mlflow.log_artifacts(tmp_dir)
clean_up_old_runs()
log_run_to_mlflow(model_config, result, preprocessor_path)
2025/04/16 21:07:07 INFO mlflow.tracking.fluent: Experiment with name 'breast_cancer_all_features' does not exist. Creating a new experiment.
Start the MLflow server to view the experiments:
mlflow server -h 0.0.0.0 -p 8080 --backend-store-uri {model_registry}
To view the dashboard, go to the Overview tab > Open Ports > 8080.
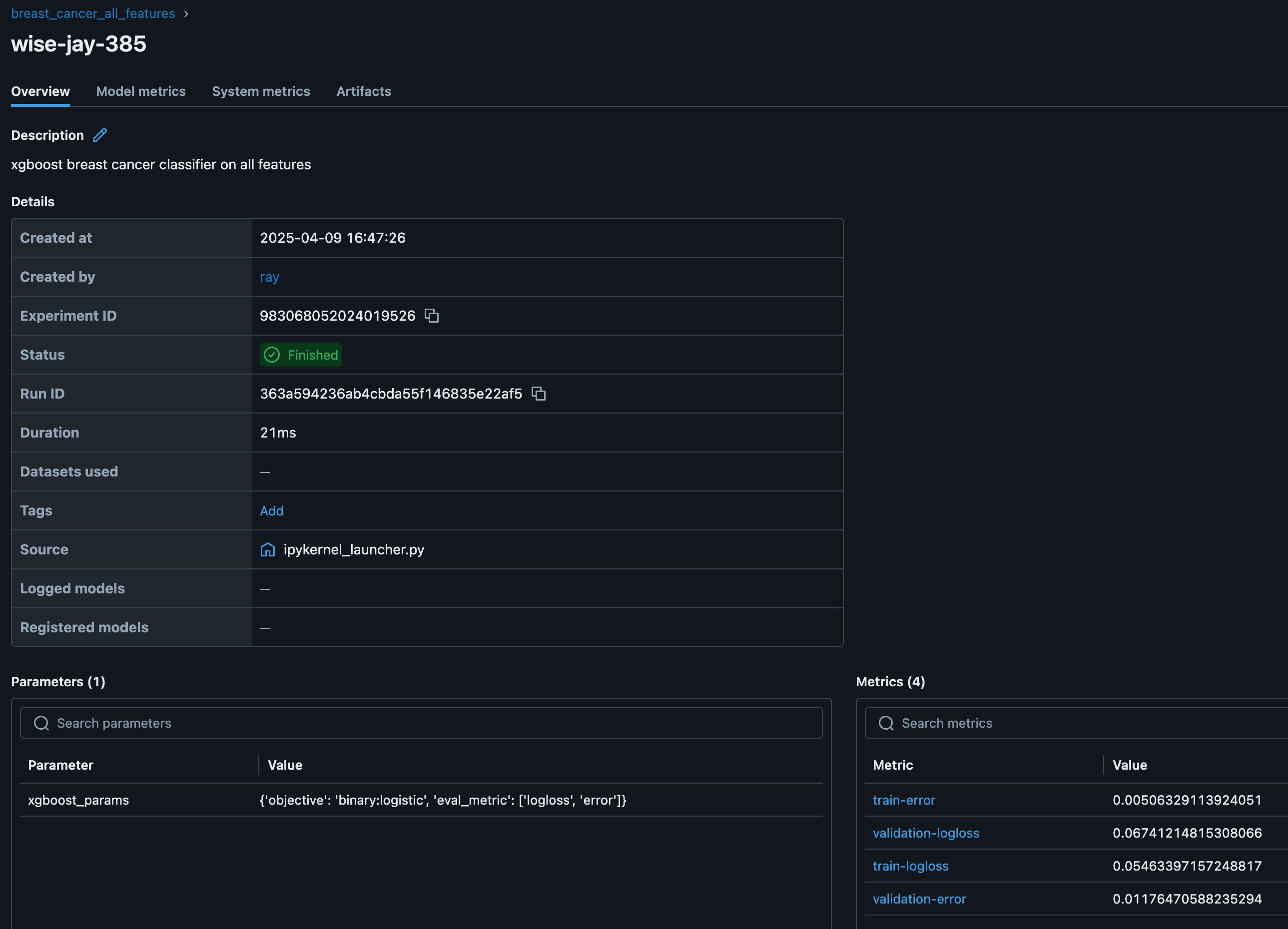
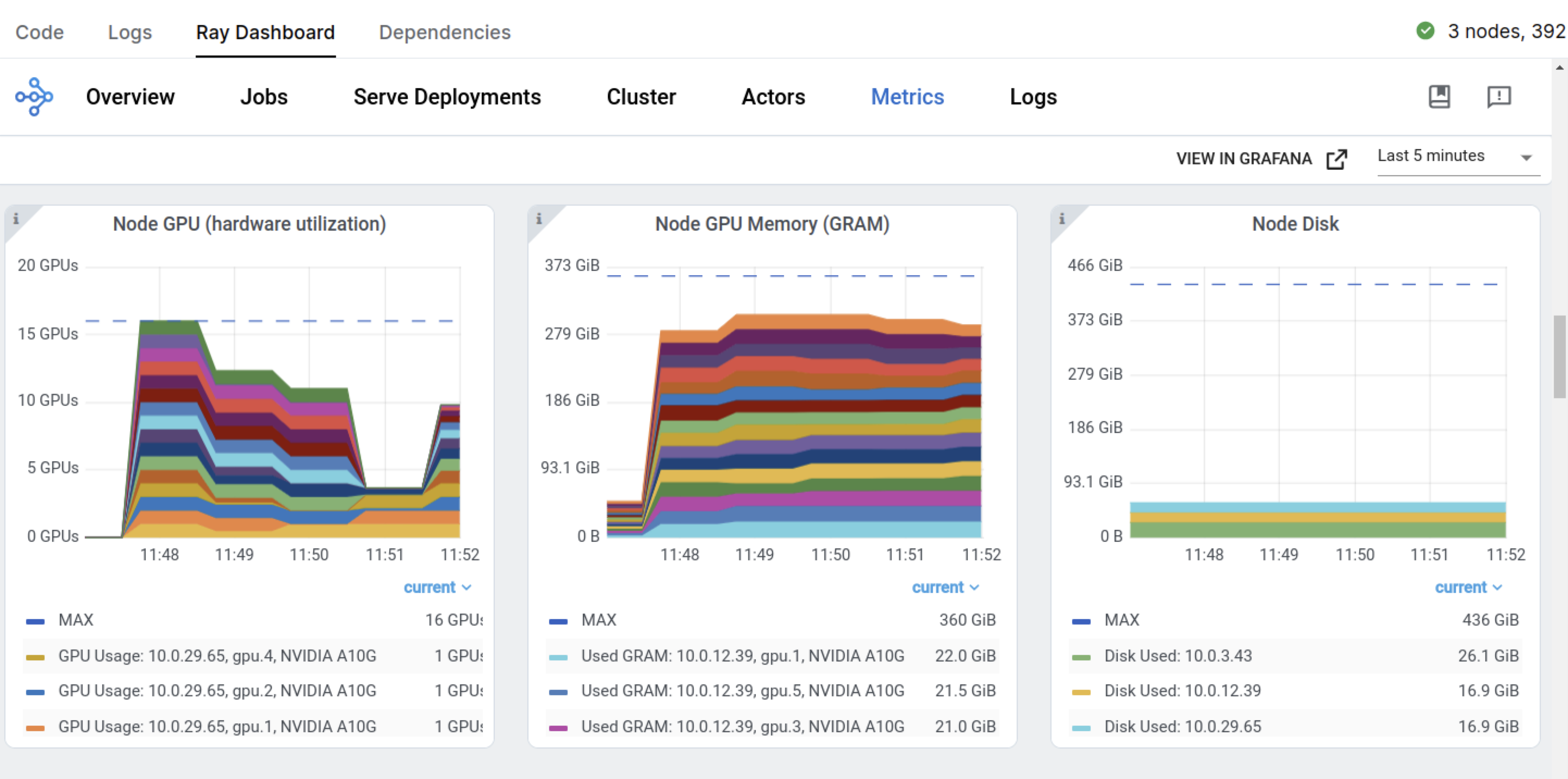
You can also view the Ray Dashboard and Train workload dashboards:
You can retrieve the best model from the registry:
from dist_xgboost.data import get_best_model_from_registry
best_model, artifacts_dir = get_best_model_from_registry()
artifacts_dir
'/mnt/user_storage/mlflow/290203875164933232/eb2666ca6cee4792bfda41a02b194d87/artifacts'
Production deployment#
You can wrap the training workload as a production-grade Anyscale Job. See the API ref for more details.
from dist_xgboost.constants import root_dir
os.environ["WORKING_DIR"] = root_dir
Then submit the job using the anyscale CLI command:
%%bash
# Production batch job -- note that this is a bash cell
! anyscale job submit --name=train-xboost-breast-cancer-model \
--containerfile="${WORKING_DIR}/containerfile" \
--working-dir="${WORKING_DIR}" \
--exclude="" \
--max-retries=0 \
--wait \
-- cd notebooks && jupyter nbconvert --to script 01-Distributed_Training.ipynb && ipython 01-Distributed_Training.py
Output
(anyscale +0.9s) Submitting job with config JobConfig(name='train-xboost-breast-cancer-model', image_uri=None, compute_config=None, env_vars=None, py_modules=None, py_executable=None, cloud=None, project=None, ray_version=None, job_queue_config=None).
(anyscale +2.6s) Uploading local dir '/home/ray/default/e2e-xgboost' to cloud storage.
(anyscale +3.8s) Including workspace-managed pip dependencies.
(anyscale +4.2s) Job 'train-xboost-breast-cancer-model' submitted, ID: 'prodjob_bkbpnmhytt3ljt8ftlnyumjxdj'.
(anyscale +4.2s) View the job in the UI: https://console.anyscale.com/jobs/prodjob_bkbpnmhytt3ljt8ftlnyumjxdj
(anyscale +4.2s) Use `--wait` to wait for the job to run and stream logs.
The
containerfiledefines the dependencies, but you can also use a pre-built imageYou can specify compute requirements as a compute config or inline in a job config
When launched from a workspace without specifying compute, it defaults to the compute configuration of the workspace
Scaling strategies#
One of the key advantages of Ray Train is its ability to effortlessly scale training workloads. By adjusting the ScalingConfig, you can optimize resource utilization and reduce training time.
Scaling examples#
Multi-node CPU example: 4 nodes with 8 CPUs each
scaling_config = ScalingConfig(
num_workers=4,
resources_per_worker={"CPU": 8},
)
Single-node multi-GPU example: 1 node with 8 CPUs and 4 GPUs
scaling_config = ScalingConfig(
num_workers=4,
use_gpu=True,
)
Multi-node multi-GPU example: 4 nodes with 8 CPUs and 4 GPUs each
scaling_config = ScalingConfig(
num_workers=16,
use_gpu=True,
)
Important: For multi-node clusters, you must specify a shared storage location, such as cloud storage or NFS, in the
run_config. Using a local path raises an error during checkpointing.trainer = XGBoostTrainer( ..., run_config=ray.train.RunConfig(storage_path="s3://...") )
Worker configuration guidelines#
The optimal number of workers depends on the workload and cluster setup:
For CPU-only training, generally use one worker per node. XGBoost can leverage multiple CPUs with threading.
For multi-GPU training, use one worker per GPU.
For heterogeneous clusters, consider the greatest common divisor of CPU counts.
GPU acceleration#
To use GPUs for training:
Start one actor per GPU with
use_gpu=TrueSet GPU-compatible parameters, for example,
tree_method="gpu_hist"for XGBoostDivide CPUs evenly across actors on each machine
Example:#
trainer = XGBoostTrainer(
scaling_config=ScalingConfig(
# Number of workers to use for data parallelism.
num_workers=2,
# Whether to use GPU acceleration.
use_gpu=True,
),
params={
# XGBoost specific params.
"tree_method": "gpu_hist", # GPU-specific parameter
"eval_metric": ["logloss", "error"],
},
...
)
For more advanced topics, see: