Introduction to Ray Train workloads#

This notebook shows how to run distributed data-parallel training with PyTorch on an Anyscale cluster using Ray Train. You train a ResNet-18 model on MNIST across multiple GPUs, with built-in support for checkpointing, metrics reporting, and distributed orchestration.
Learning objectives#
Why and when to use Ray Train for distributed training instead of managing PyTorch DDP manually
How to wrap your PyTorch code with
prepare_model()andprepare_data_loader()for multi-GPU executionHow to configure scale with
ScalingConfig(num_workers=..., use_gpu=True)and track outputs withRunConfig(storage_path=...)How to report metrics and save checkpoints using
ray.train.report(...), with best practices for rank-0 checkpointingHow to use Anyscale storage: fast local NVMe vs. persistent cluster/cloud storage
How to inspect training results (metrics DataFrame, checkpoints) and load a checkpointed model for inference with Ray
The entire workflow runs fully distributed from the start: you define your training loop once, and Ray handles orchestration, sharding, and checkpointing across the cluster.
When to use Ray Train#
Use Ray Train when you face one of the following challenges:
Challenge |
Detail |
Solution |
|---|---|---|
Need to speed up or scale up training |
Training jobs might take a long time to complete, or require a lot of compute |
Ray Train provides a distributed training framework that scales training to multiple GPUs |
Minimize overhead of setting up distributed training |
You must manage the underlying infrastructure |
Ray Train handles the underlying infrastructure through Ray’s autoscaling |
Achieve observability |
You need to connect to different nodes and GPUs to find the root cause of failures, fetch logs, traces, etc |
Ray Train provides observability through Ray’s dashboard, metrics, and traces that let you monitor the training job |
Ensure reliable training |
Training jobs can fail due to hardware failures, network issues, or other unexpected events |
Ray Train provides fault tolerance through checkpointing, automatic retries, and the ability to resume training from the last checkpoint |
Avoid significant code rewrite |
You might need to fully rewrite your training loop to support distributed training |
Ray Train provides a suite of integrations with the PyTorch ecosystem, Tree-based methods (XGB, LGBM), and more to minimize the amount of code changes needed |
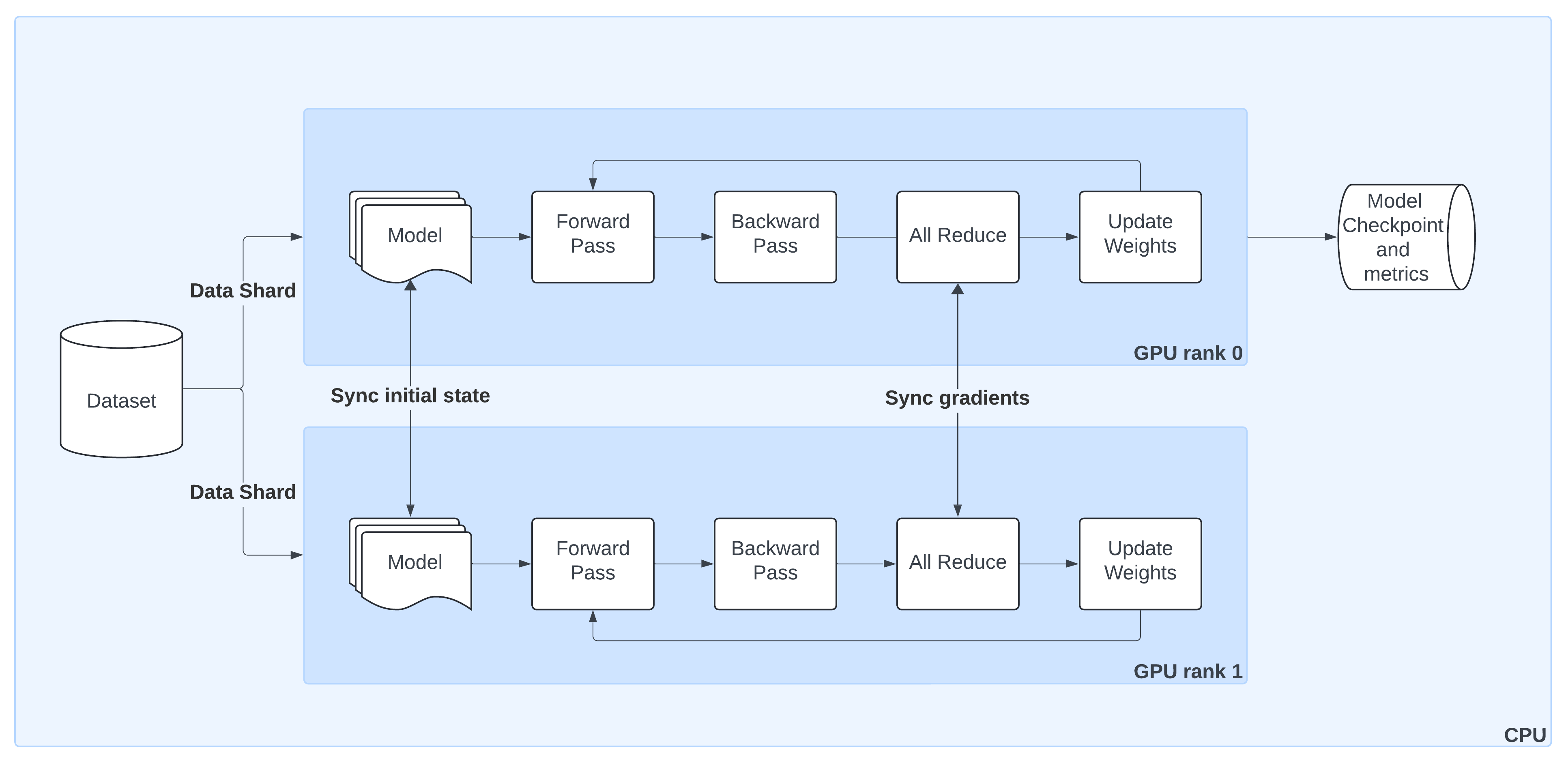
How distributed data parallel (DDP) works#
The preceding diagram shows the lifecycle of a single training step in PyTorch DistributedDataParallel (DDP) when orchestrated by Ray Train:
Model Replication
Ray Train initializes the model on GPU rank 0 and broadcasts it to all other workers so that each has an identical copy.Sharded Data Loading
Ray Train automatically splits the dataset into non-overlapping shards. Each worker processes only its shard, ensuring efficient parallelism without duplicate samples.Forward & Backward Passes
Each worker runs a forward pass and computes gradients locally during the backward pass.Gradient Synchronization
An AllReduce step aggregates gradients across workers, ensuring that model updates stay consistent across all GPUs.Weight Updates
Once Ray Train synchronizes gradients, each worker applies the update, keeping model replicas in sync.Checkpointing & Metrics
By convention, only the rank 0 worker saves checkpoints and logs metrics to persistent storage. This avoids duplication while preserving progress and results.
With Ray Train, you don’t need to manage process groups or samplers manually—utilities like prepare_model() and prepare_data_loader() wrap these details so your code works out of the box in a distributed setting.
|
|---|
Schematic overview of DistributedDataParallel (DDP) training: (1) Ray Train replicates the model from the |
01 · Imports#
Start by importing all the libraries you need for this tutorial.
Standard utilities:
os,datetime,tempfile,csv,shutil, andgchelp with file paths, checkpointing, cleanup, and general housekeeping.Data and visualization:
pandas,numpy,matplotlib, andPILhelp you inspect the dataset and plot sample images.PyTorch: core deep learning components (
torch,CrossEntropyLoss,Adam) plustorchvisionfor loading MNIST and building a ResNet-18 model.Ray Train: the key imports for distributed training—
ScalingConfig,RunConfig, andTorchTrainer. These components handle cluster scaling, experiment output storage, and execution of your training loop across GPUs.
This notebook assumes Ray is already running (for example, inside an Anyscale cluster), so you don’t need to call ray.init() manually.
# 00. Runtime setup — install same deps as build.sh and set env vars
import os
import sys
import subprocess
# Non-secret env var
os.environ["RAY_TRAIN_V2_ENABLED"] = "1"
# Install Python dependencies (
!pip install --no-cache-dir torch==2.8.0 torchvision==0.23.0 matplotlib==3.7.4 pandas==2.3.3
# 01. Imports
# --- Standard library: file IO, paths, timestamps, temp dirs, cleanup ---
import csv # Simple CSV logging for metrics in single-GPU section
import datetime # Timestamps for run directories / filenames
import os # Filesystem utilities (paths, env vars)
import tempfile # Ephemeral dirs for checkpoint staging with ray.train.report()
import shutil # Cleanup of artifacts (later cells)
import gc # Manual garbage collection to cleanup after inference
from pathlib import Path # Convenient, cross-platform path handling
# --- Visualization & data wrangling ---
import matplotlib.pyplot as plt # Plot sample digits and metrics curves
from PIL import Image # Image utilities for inspection/debug
import numpy as np # Numeric helpers (random sampling, arrays)
import pandas as pd # Read metrics.csv into a DataFrame
# --- PyTorch & TorchVision (model + dataset) ---
import torch
from torch.nn import CrossEntropyLoss # Classification loss for MNIST
from torch.optim import Adam # Optimizer
from torchvision.models import resnet18 # Baseline CNN (we’ll adapt for 1-channel input)
from torchvision.datasets import MNIST # Dataset
from torchvision.transforms import ToTensor, Normalize, Compose # Preprocessing pipeline
# --- Ray Train (distributed orchestration) ---
import ray
from ray.train import ScalingConfig, RunConfig # Configure scale and storage
from ray.train.torch import TorchTrainer # Multi-GPU PyTorch trainer (DDP/FSDP)
02 · Download MNIST dataset#
Next, download the MNIST dataset using torchvision.datasets.MNIST.
This automatically fetches the dataset (if not already present) into a local
./datadirectory.MNIST consists of 60,000 grayscale images of handwritten digits (0–9), each sized 28×28 pixels.
By setting
train=True, this loads the training split of the dataset.
After downloading, wrap this dataset in a DataLoader and apply normalization for use in model training.
# 02. Download MNIST Dataset
dataset = MNIST(root="/mnt/cluster_storage/data", train=True, download=True)
Note about Anyscale storage options
In this example, this tutorial stores the MNIST dataset under /mnt/cluster_storage/, which is Anyscale’s persistent cluster storage.
Unlike node-local NVMe volumes, cluster storage is shared across nodes in your cluster.
Data written here persists across cluster restarts, making it a safe place for datasets, checkpoints, and results.
This is the recommended location for training data and artifacts you want to reuse.
Anyscale also provides each node with its own volume and disk and doesn’t share them with other nodes.
Local storage is very fast - Anyscale supports the Non-Volatile Memory Express (NVMe) interface.
Local storage isn’t a persistent storage, Anyscale deletes data in the local storage after instance termination.
Read more about available storage options.
03 · Visualize sample digits#
Before training, take a quick look at the dataset.
Random sample of nine images from the MNIST training set.
Each image is a 28×28 grayscale digit, with its ground-truth label preceding the plot.
This visualization is a good sanity check to confirm that the dataset downloaded correctly and that labels align with the images.
# 03. Visualize Sample Digits
# Create a square figure for plotting 9 samples (3x3 grid)
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
# Loop through grid slots and plot a random digit each time
for i in range(1, cols * rows + 1):
# Randomly select an index from the dataset
sample_idx = np.random.randint(0, len(dataset.data))
img, label = dataset[sample_idx] # image (PIL) and its digit label
# Add subplot to the figure
figure.add_subplot(rows, cols, i)
plt.title(label) # show the digit label above each subplot
plt.axis("off") # remove axes for cleaner visualization
plt.imshow(img, cmap="gray") # display as grayscale image
04 · Define ResNet-18 model for MNIST#
Now define the ResNet-18 architecture to use for classification.
torchvision.models.resnet18is pre-configured for 3-channel RGB input and ImageNet classes.Since MNIST digits are 1-channel grayscale images with 10 output classes, you need two adjustments:
Override the first convolution layer (
conv1) to acceptin_channels=1.Set the final layer to output 10 logits, one per digit class (handled by
num_classes=10).
This gives a ResNet-18 tailored for MNIST while preserving the rest of the architecture.
# 04. Define ResNet-18 Model for MNIST
def build_resnet18():
# Start with a torchvision ResNet-18 backbone
# Set num_classes=10 since MNIST has digits 0–9
model = resnet18(num_classes=10)
# Override the first convolution layer:
# - Default expects 3 channels (RGB images)
# - MNIST is grayscale → only 1 channel
# - Keep kernel size/stride/padding consistent with original ResNet
model.conv1 = torch.nn.Conv2d(
in_channels=1, # input = grayscale
out_channels=64, # number of filters remains the same as original ResNet
kernel_size=(7, 7),
stride=(2, 2),
padding=(3, 3),
bias=False,
)
# Return the customized ResNet-18
return model
Migration roadmap: from standalone PyTorch to PyTorch with Ray Train
The following are the steps to take a regular PyTorch training loop and run it in a fully distributed setup with Ray Train.
- Configure scale and GPUs — decide how many workers and whether each should use a GPU.
- Wrap the model with Ray Train — use
prepare_model()to move the ResNet to the right device and wrap it in DDP automatically. - Wrap the dataset with Ray Train — use
prepare_data_loader()so each worker gets a distinct shard of MNIST, moved to the correct device. - Add metrics & checkpointing — report training loss and save checkpoints with
ray.train.report()from rank-0. - Configure persistent storage — store outputs under
/mnt/cluster_storage/so that results and checkpoints are available across the cluster.
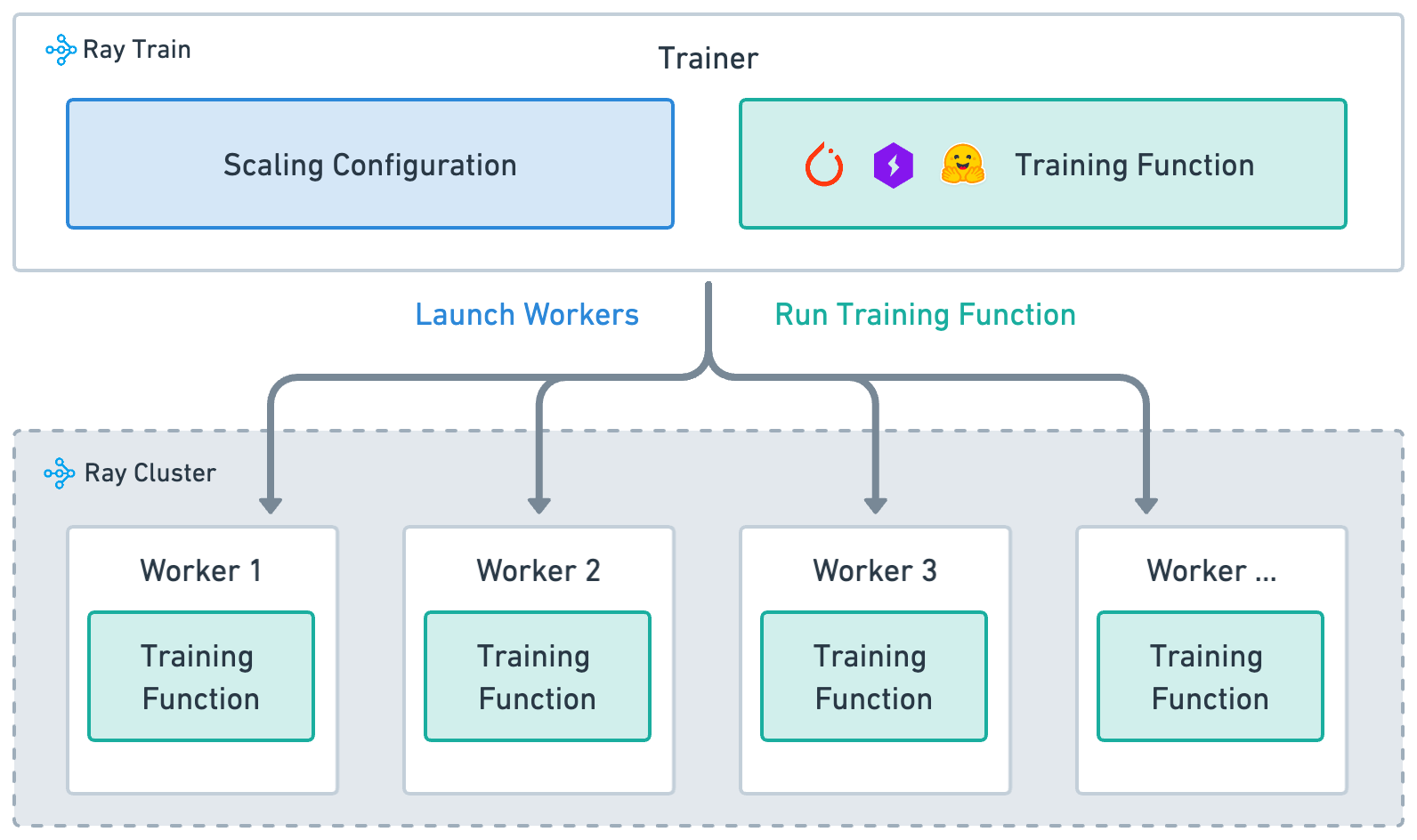
Ray Train is built around four key concepts:
Training function: (implemented in the preceding
train_loop_ray_train): A Python function that contains your model training logic.Worker: A process that runs the training function.
Scaling config: specifies number of workers and compute resources (CPUs or GPUs, TPUs).
Trainer: A Python class (Ray Actor) that ties together the training function, workers, and scaling configuration to execute a distributed training job.
|
|---|
High-level architecture of how Ray Train |
05 · Define the Ray Train loop (DDP per-worker)#
This is the per-worker training function that Ray executes on each process/GPU. It keeps your PyTorch code intact while Ray handles process launch, device placement, and data sharding.
Key points:
Inputs with
config: pass hyperparameters likenum_epochsand aglobal_batch_size.Model & optimizer:
load_model_ray_train()returns a model already wrapped by Ray Train (DDP + correct device). UseAdamandCrossEntropyLossfor MNIST.Batch sizing: Split the global batch across workers:
per_worker_batch = global_batch_size // world_size.Data sharding:
build_data_loader_ray_train(...)returns a DataLoader wrapped with a DistributedSampler; each worker sees a disjoint shard.Epoch control:
data_loader.sampler.set_epoch(epoch)ensures proper shuffling across epochs in distributed mode.Training step: standard PyTorch loop—forward → loss →
zero_grad→ backward → step.Metrics & checkpointing:
print_metrics_ray_train(...)logs loss;save_checkpoint_and_metrics_ray_train(...)callsray.train.report(...)(rank-0 saves the checkpoint).
Pass this function to TorchTrainer, which runs it concurrently on all workers.
See how this data-parallel training loop looks like with Ray Train and PyTorch.
# 05. Define the Ray Train per-worker training loop
def train_loop_ray_train(config: dict): # pass in hyperparameters in config
# config holds hyperparameters passed from TorchTrainer (e.g. num_epochs, global_batch_size)
# Define loss function for MNIST classification
criterion = CrossEntropyLoss()
# Build and prepare the model for distributed training.
# load_model_ray_train() calls ray.train.torch.prepare_model()
# → moves model to GPU and wraps it in DistributedDataParallel (DDP).
model = load_model_ray_train()
# Standard optimizer (learning rate fixed for demo)
optimizer = Adam(model.parameters(), lr=1e-5)
# Calculate the batch size for each worker
global_batch_size = config["global_batch_size"]
world_size = ray.train.get_context().get_world_size() # total # of workers in the job
batch_size = global_batch_size // world_size # split global batch evenly
print(f"{world_size=}\n{batch_size=}")
# Wrap DataLoader with prepare_data_loader()
# → applies DistributedSampler (shards data across workers)
# → ensures batches are automatically moved to correct device
data_loader = build_data_loader_ray_train(batch_size=batch_size)
# ----------------------- Training loop ----------------------- #
for epoch in range(config["num_epochs"]):
# Ensure each worker shuffles its shard differently every epoch
data_loader.sampler.set_epoch(epoch)
# Iterate over batches (sharded across workers)
for images, labels in data_loader:
outputs = model(images) # forward pass
loss = criterion(outputs, labels) # compute loss
optimizer.zero_grad() # reset gradients
loss.backward() # backward pass (grads averaged across workers through DDP)
optimizer.step() # update model weights
# After each epoch: report loss and log metrics
metrics = print_metrics_ray_train(loss, epoch)
# Save checkpoint (only rank-0 worker persists the model)
save_checkpoint_and_metrics_ray_train(model, metrics)
Main training loop
- `global_batch_size`: the total number of samples processed in a single training step of the entire training job.
- It's estimated like this:
batch size * DDP workers * gradient accumulation steps.
- It's estimated like this:
- Notice that images and labels are no longer manually moved to device (
images.to("cuda")). This is done by prepare_data_loader() . - Configuration passed here is defined below. Passed to the Ray Train's TorchTrainer.
- TrainContext lets you get useful information about the training such as node rank, world size, world rank, experiment name.
load_model_ray_trainandbuild_data_loader_ray_trainare implemented below.
06 · Define train_loop_config#
The train_loop_config is a simple dictionary of hyperparameters that Ray passes into your training loop (train_loop_ray_train).
It acts as the bridge between the
TorchTrainerand your per-worker training code.Anything defined here becomes available inside the
configargument oftrain_loop_ray_train.
In this example:
num_epochs→ how many full passes through the dataset to run.global_batch_size→ the total batch size across all workers (Ray splits this evenly across GPUs).
You can add other parameters here (like learning_rate, embedding_dim, etc.) and they can automatically be accessible in your training loop through config["param_name"].
# 06. Define the configuration dictionary passed into the training loop
# train_loop_config is provided to TorchTrainer and injected into
# train_loop_ray_train(config) as the "config" argument.
# → Any values defined here are accessible inside the training loop.
train_loop_config = {
"num_epochs": 2, # Number of full passes through the dataset
"global_batch_size": 128 # Effective batch size across ALL workers
# (Ray will split this evenly per worker, e.g.
# with 8 workers → 16 samples/worker/step)
}
07 · Configure scaling with ScalingConfig#
The ScalingConfig tells Ray Train how many workers to launch and what resources each worker should use.
num_workers=8→ Run the training loop on 8 parallel workers. Each worker runs the same code on a different shard of the data.use_gpu=True→ Assign one GPU per worker. If you set this toFalse, each worker would train on CPU instead.
This declarative config is what allows Ray to handle cluster orchestration for you—you don’t need to manually start processes or set CUDA devices.
Later, you can pass this scaling_config into the TorchTrainer to launch distributed training.
# 07. Configure the scaling of the training job
# ScalingConfig defines how many parallel training workers Ray should launch
# and whether each worker should be assigned a GPU or CPU.Z
# → Each worker runs train_loop_ray_train(config) independently,
# with Ray handling synchronization through DDP under the hood.
scaling_config = ScalingConfig(
num_workers=8, # Launch 8 training workers (1 process per worker)
use_gpu=True # Allocate 1 GPU to each worker
)
Docs on ScalingConfig can be found with the link in this sentence.
See docs on configuring scale and accelerators for more details.
08 · Wrap the model with prepare_model()#
Next, define a helper function to build and prepare the model for Ray Train.
Start by constructing the ResNet-18 model adapted for MNIST using
build_resnet18().Instead of manually calling
model.to("cuda")and wrapping it in DistributedDataParallel (DDP), useray.train.torch.prepare_model().This automatically:
Moves the model to the correct device (GPU or CPU).
Wraps it in DDP or FSDP.
Ensures gradients are synchronized across workers.
This means the same code works whether you’re training on 1 GPU or 100 GPUs—no manual device placement or DDP boilerplate required.
# 08. Build and prepare the model for Ray Train
def load_model_ray_train() -> torch.nn.Module:
model = build_resnet18()
# prepare_model() → move to correct device + wrap in DDP automatically
model = ray.train.torch.prepare_model(model)
return model
parallel_strategy: "DDP", "FSDP" – wrap models inDistributedDataParallelorFullyShardedDataParallelparallel_strategy_kwargs: pass additional arguments to "DDP" or "FSDP"
09 · Build the DataLoader with prepare_data_loader()#
Now define a helper that builds the MNIST DataLoader and makes it Ray Train–ready.
Apply standard preprocessing:
ToTensor()→ convert PIL images to PyTorch tensorsNormalize((0.5,), (0.5,))→ center and scale pixel values
Construct a PyTorch
DataLoaderwith batching and shuffling.Finally, wrap it with
prepare_data_loader(), which automatically:Moves each batch to the correct device (GPU or CPU).
Copies data from host memory to device memory as needed.
Injects a PyTorch
DistributedSamplerwhen running with multiple workers, so that each worker processes a unique shard of the dataset.
This utility lets you use the same DataLoader code whether you’re training on one GPU or many—Ray handles the distributed sharding and device placement for you.
# 09. Build a Ray Train–ready DataLoader for MNIST
def build_data_loader_ray_train(batch_size: int) -> torch.utils.data.DataLoader:
# Define preprocessing: convert to tensor + normalize pixel values
transform = Compose([ToTensor(), Normalize((0.5,), (0.5,))])
# Load the MNIST training set from persistent cluster storage
train_data = MNIST(
root="/mnt/cluster_storage/data",
train=True,
download=True,
transform=transform,
)
# Standard PyTorch DataLoader (batching, shuffling, drop last incomplete batch)
train_loader = torch.utils.data.DataLoader(train_data, batch_size=batch_size, shuffle=True, drop_last=True)
# prepare_data_loader():
# - Adds a DistributedSampler when using multiple workers
# - Moves batches to the correct device automatically
train_loader = ray.train.torch.prepare_data_loader(train_loader)
return train_loader
Ray Data integration
This step isn’t necessary if you are integrating your Ray Train workload with Ray Data. It’s especially useful if preprocessing is CPU-heavly and user wants to run preprocessing and training of separate instances.
10 · Report training metrics#
During training, it’s important to log metrics like loss values so you can monitor progress.
This helper function prints metrics from every worker:
Collects the current loss and epoch into a dictionary.
Uses
ray.train.get_context().get_world_rank()to identify which worker is reporting.Prints the metrics along with the worker’s rank for debugging and visibility.
# 10. Report training metrics from each worker
def print_metrics_ray_train(loss: torch.Tensor, epoch: int) -> None:
metrics = {"loss": loss.item(), "epoch": epoch}
world_rank = ray.train.get_context().get_world_rank() # report from all workers
print(f"{metrics=} {world_rank=}")
return metrics
If you want to log only from the rank 0 worker, use this code:
def print_metrics_ray_train(loss: torch.Tensor, epoch: int) -> None:
metrics = {"loss": loss.item(), "epoch": epoch}
if ray.train.get_context().get_world_rank() == 0: # report only from the rank 0 worker
print(f"{metrics=} {world_rank=}")
return metrics
11 · Save checkpoints and report metrics#
Report intermediate metrics and checkpoints using the ray.train.report utility function.
This helper function:
Creates a temporary directory to stage the checkpoint.
Saves the model weights with
torch.save().Since the model is wrapped in DistributedDataParallel (DDP), call
model.module.state_dict()to unwrap it.
Calls
ray.train.report()to:Log the current metrics (for example, loss, epoch).
Attach a
Checkpointobject created from the staged directory.
This way, each epoch produces both metrics for monitoring and a checkpoint for recovery or inference.
# 11. Save checkpoint and report metrics with Ray Train
def save_checkpoint_and_metrics_ray_train(model: torch.nn.Module, metrics: dict[str, float]) -> None:
# Create a temporary directory to stage checkpoint files
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
# Save the model weights.
# Note: under DDP the model is wrapped in DistributedDataParallel,
# so we unwrap it with `.module` before calling state_dict().
torch.save(
model.module.state_dict(), # note the `.module` to unwrap the DistributedDataParallel
os.path.join(temp_checkpoint_dir, "model.pt"),
)
# Report metrics and attach a checkpoint to Ray Train.
# → metrics are logged centrally
# → checkpoint allows resuming training or running inference later
ray.train.report(
metrics,
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
Quick notes:
- Use ray.train.report to save the metrics and checkpoint.
- Only metrics from the rank 0 worker are reported.
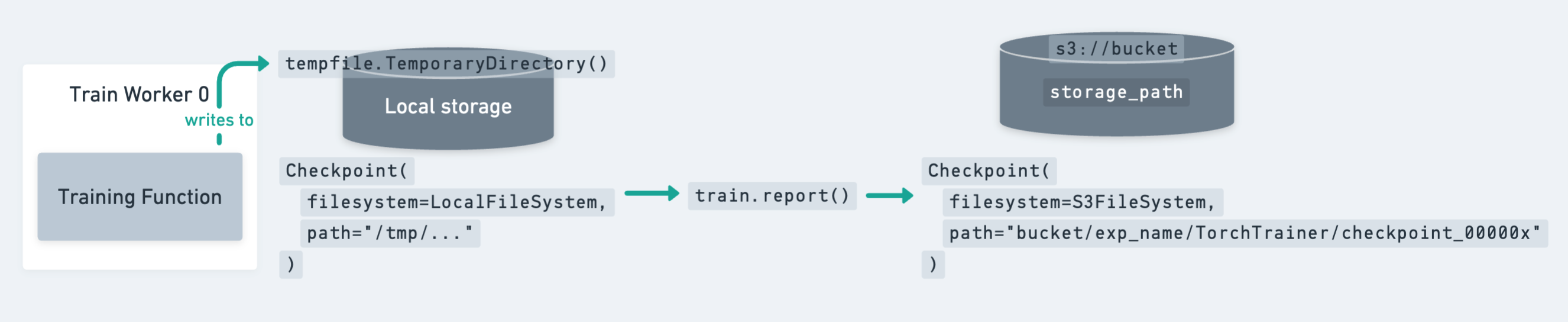
Note on the checkpoint lifecycle#
The preceding diagram shows how a checkpoint moves from local storage (temporary directory on a worker) to persistent cluster or cloud storage.
Key points to remember:
Since the model is identical across all workers, it’s enough to write the checkpoint only on the rank-0 worker.
However, you still need to call
ray.train.reporton all workers to keep the training loop synchronized.
Ray Train expects every worker to have access to the same persistent storage location for writing files.
For production jobs, cloud storage (for example, S3, GCS, Azure Blob) is the recommended target for checkpoints.
12 · Save checkpoints on rank-0 only#
To avoid redundant writes, update the checkpointing function so that only the rank-0 worker saves the model weights.
Temporary directory → Each worker still creates a temp directory, but only rank-0 writes the model file.
Rank check →
ray.train.get_context().get_world_rank()ensures that only worker 0 performs the checkpointing.All workers report → Every worker still calls
ray.train.report, but only rank-0 attaches the actual checkpoint. This keeps the training loop synchronized.
This pattern is the recommended best practice:
Avoids unnecessary duplicate checkpoints from multiple workers.
Still guarantees that metrics are reported from every worker.
Ensures checkpoints are cleanly written once per epoch to persistent storage.
# 12. Save checkpoint only from the rank-0 worker
def save_checkpoint_and_metrics_ray_train(model: torch.nn.Module, metrics: dict[str, float]) -> None:
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
# Only the rank-0 worker writes the checkpoint file
if ray.train.get_context().get_world_rank() == 0:
torch.save(
model.module.state_dict(), # unwrap DDP before saving
os.path.join(temp_checkpoint_dir, "model.pt"),
)
checkpoint = ray.train.Checkpoint.from_directory(temp_checkpoint_dir)
# All workers still call ray.train.report()
# → keeps training loop synchronized
# → metrics are logged from each worker
# → only rank-0 attaches a checkpoint
ray.train.report(
metrics,
checkpoint=checkpoint,
)
Check the guide on saving and loading checkpoints for more details and best practices.
13 · Configure persistent storage with RunConfig#
To tell Ray Train where to store results, checkpoints, and logs, use a RunConfig.
storage_path→ Base directory for all outputs of this training run.This example uses
/mnt/cluster_storage/training/, which is persistent shared storage across all nodes.This ensures checkpoints and metrics remain available even after the cluster shuts down.
name→ A human-readable name for the run (for example,"distributed-mnist-resnet18"). This is used to namespace output files.
Together, the RunConfig defines how Ray organizes and persists all artifacts from your training job.
# 13. Configure persistent storage and run name
storage_path = "/mnt/cluster_storage/training/"
run_config = RunConfig(
storage_path=storage_path, # where to store checkpoints/logs
name="distributed-mnist-resnet18" # identifier for this run
)
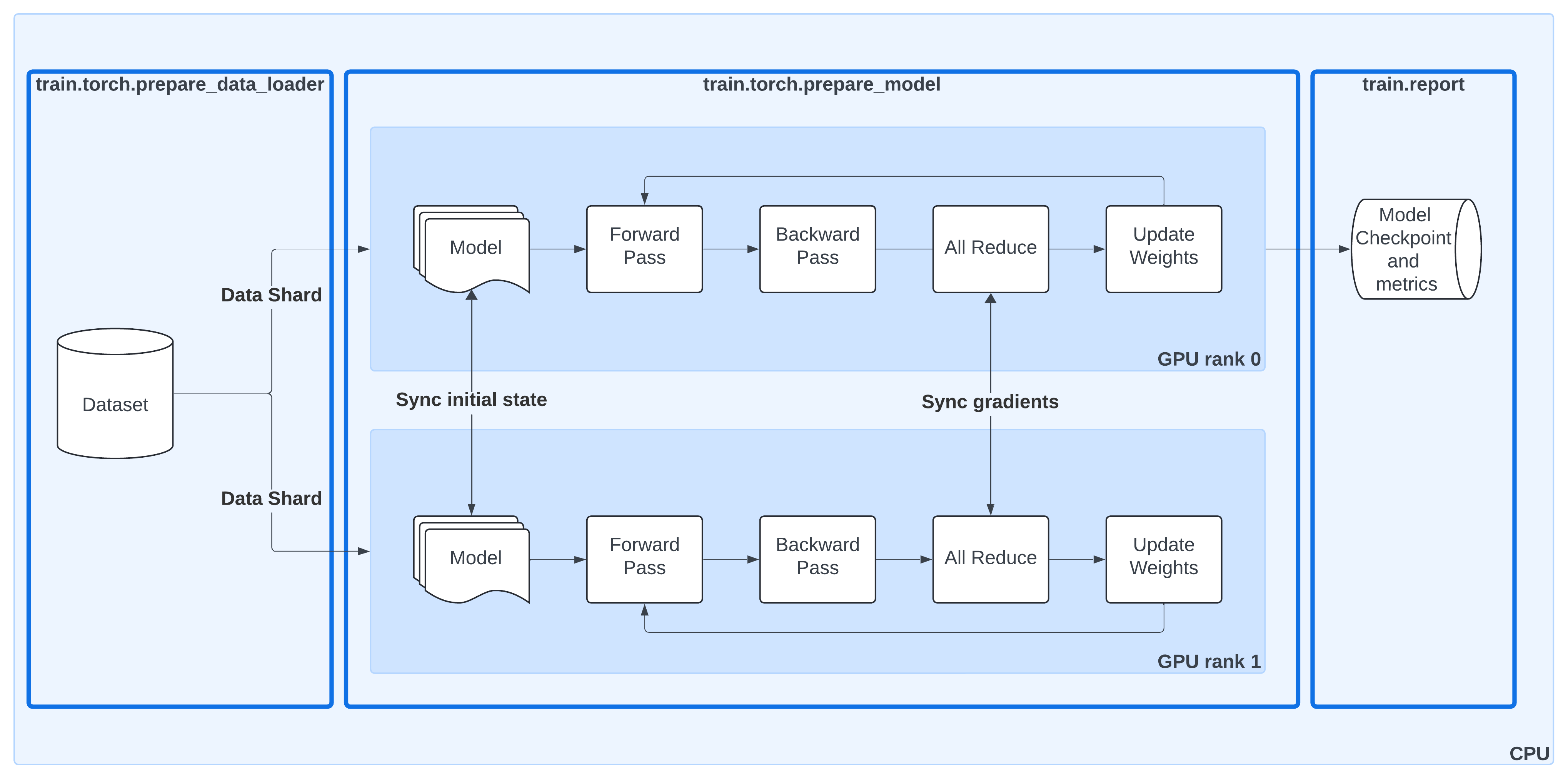
Distributed data-parallel training with Ray Train#
This diagram shows the same DDP workflow as before, but now with Ray Train utilities highlighted:
ray.train.torch.prepare_data_loader()Automatically wraps your PyTorch DataLoader with a
DistributedSampler.Ensures each worker processes a unique shard of the dataset.
Moves batches to the correct device (GPU or CPU).
ray.train.torch.prepare_model()Moves your model to the right device.
Wraps it in
DistributedDataParallel (DDP)so gradients are synchronized across workers.Removes the need for manual
.to("cuda")calls or DDP boilerplate.
ray.train.report()Centralized way to report metrics and attach checkpoints.
Keeps the training loop synchronized across all workers, even if only rank-0 saves the actual checkpoint.
By combining these helpers, Ray Train takes care of the data sharding, model replication, gradient synchronization, and checkpoint lifecycle—letting you keep your training loop clean and close to standard PyTorch.
|
|---|
14 · Create the TorchTrainer#
Now bring everything together with a TorchTrainer.
The TorchTrainer is the high-level Ray Train class that:
Launches the per-worker training loop (
train_loop_ray_train) across the cluster.Applies the scaling setup from
scaling_config(number of workers, GPUs/CPUs).Uses
run_configto decide where results and checkpoints are stored.Passes
train_loop_config(hyperparameters likenum_epochsandglobal_batch_size) into the training loop.
This object encapsulates the distributed orchestration, so you can start training with a call to trainer.fit().
# 14. Set up the TorchTrainer
trainer = TorchTrainer(
train_loop_ray_train, # training loop to run on each worker
scaling_config=scaling_config, # number of workers and resource config
run_config=run_config, # storage path + run name for artifacts
train_loop_config=train_loop_config, # hyperparameters passed to the loop
)
15 · Launch training with trainer.fit()#
Calling trainer.fit() starts the distributed training job and blocks until it completes.
When the job launches, you can see logs that confirm:
Process group setup → Ray initializes a distributed worker group and assigns ranks (for example,
world_rank=0andworld_rank=1).Worker placement → Each worker is launched on a specific node and device. The logs show IP addresses, process IDs, and rank assignments.
Model preparation → Each worker moves the model to its GPU (
cuda:0) and wraps it in DistributedDataParallel (DDP).
These logs are a quick sanity check that Ray Train is correctly orchestrating multi-GPU training across your cluster.
|
|---|

# 15. Launch distributed training
# trainer.fit() starts the training job:
# - Spawns workers according to scaling_config
# - Runs train_loop_ray_train() on each worker
# - Collects metrics and checkpoints into result
result = trainer.fit()
16 · Inspect the training results#
When trainer.fit() finishes, it returns a Result object.
This object contains:
Final metrics → the most recent values reported from the training loop (for example, loss at the last epoch).
Checkpoint → a reference to the latest saved checkpoint, including its path in cluster storage.
Metrics dataframe → a history of all reported metrics across epochs (accessible with
result.metrics_dataframe).Best checkpoints → Ray automatically tracks checkpoints associated with their reported metrics.
In the preceding output, you can see:
The final reported loss at epoch 1.
The location where checkpoints are stored (
/mnt/cluster_storage/training/distributed-mnist-resnet18/...).A list of best checkpoints with their corresponding metrics.
This makes it easy to both analyze training performance and restore the trained model later for inference.
# 16. Show the training results
result # contains metrics, checkpoints, and run history
17 · View metrics as a DataFrame#
The Result object also includes a metrics_dataframe, which stores the full history of metrics reported during training.
Each row corresponds to one reporting step (here, each epoch).
The columns show the metrics you logged in the training loop (for example,
loss,epoch).This makes it easy to plot learning curves or further analyze training progress.
In the example below, you can see the training loss steadily decreasing across two epochs.
# 17. Display the full metrics history as a pandas DataFrame
result.metrics_dataframe
To learn more about the training results, see this docs on inspecting the training results.
18 · Load a checkpoint for inference#
After training, you can reload the model and use it for predictions.
Define a Ray actor (ModelWorker) that loads the checkpointed ResNet-18 onto a GPU and serves inference requests.
Initialization (
__init__):Reads the checkpoint directory using
checkpoint.as_directory().Loads the model weights into a fresh ResNet-18.
Moves the model to GPU and sets it to evaluation mode.
Prediction (
predict):Accepts either a single image (
[C,H,W]) or a batch ([B,C,H,W]).Ensures the tensor is correctly shaped and moved to GPU.
Runs inference in
torch.inference_mode()for efficiency.Returns the predicted class indices as a Python list.
Finally, launch the actor with ModelWorker.remote(result.checkpoint).
This spawns a dedicated process with 1 GPU attached that can serve predictions using the trained model.
# 18. Define a Ray actor to load the trained model and run inference
@ray.remote(num_gpus=1) # allocate 1 GPU to this actor
class ModelWorker:
def __init__(self, checkpoint):
# Load model weights from the Ray checkpoint (on CPU first)
with checkpoint.as_directory() as ckpt_dir:
model_path = os.path.join(ckpt_dir, "model.pt")
state_dict = torch.load(
model_path,
map_location=torch.device("cpu"),
weights_only=True,
)
# Rebuild the model, load weights, move to GPU, and set to eval mode
self.model = build_resnet18()
self.model.load_state_dict(state_dict)
self.model.to("cuda")
self.model.eval()
@torch.inference_mode() # disable autograd for faster inference
def predict(self, batch):
"""
batch: torch.Tensor or numpy array with shape [B,C,H,W] or [C,H,W]
returns: list[int] predicted class indices
"""
x = torch.as_tensor(batch)
if x.ndim == 3: # single image → add batch dimension
x = x.unsqueeze(0) # shape becomes [1,C,H,W]
x = x.to("cuda", non_blocking=True)
logits = self.model(x)
preds = torch.argmax(logits, dim=1)
return preds.detach().cpu().tolist()
# Create a fresh actor instance (avoid naming conflicts)
worker = ModelWorker.remote(result.checkpoint)
19 · Run inference and visualize predictions#
With the ModelWorker actor running on GPU, you can now generate predictions on random samples from the MNIST dataset and plot them.
Steps in this cell:
Normalization on CPU
Convert each image to a tensor with
ToTensor().Apply channel-specific normalization (
0.5mean / std).Keep this preprocessing on CPU for efficiency.
Prediction on GPU with Actor
Each normalized image is expanded to shape
[1, C, H, W].The tensor is sent to the remote
ModelWorkerfor inference.ray.get(worker.predict.remote(x))retrieves the predicted class index.
Plot Results
Display a 3×3 grid of random MNIST samples.
Each subplot shows the true label and the predicted label from the trained ResNet-18.
This demonstrates a practical workflow: CPU-based preprocessing + GPU-based inference in a Ray actor.
# 19. CPU preprocessing + GPU inference using a Ray actor
to_tensor = ToTensor()
def normalize_cpu(img):
# Convert image (PIL) to tensor on CPU → shape [C,H,W]
t = to_tensor(img) # [C,H,W] on CPU
C = t.shape[0]
# Apply channel-wise normalization (grayscale vs RGB)
if C == 3:
norm = Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
else:
norm = Normalize((0.5,), (0.5,))
return norm(t)
figure = plt.figure(figsize=(8, 8))
cols, rows = 3, 3
# Plot a 3x3 grid of random MNIST samples with predictions
for i in range(1, cols * rows + 1):
idx = np.random.randint(0, len(dataset))
img, label = dataset[idx]
# Preprocess on CPU, add batch dim → [1,C,H,W]
x = normalize_cpu(img).unsqueeze(0)
# Run inference on GPU using the Ray actor, fetch result
pred = ray.get(worker.predict.remote(x))[0] # int
# Plot image with true label and predicted label
figure.add_subplot(rows, cols, i)
plt.title(f"label: {label}; pred: {int(pred)}")
plt.axis("off")
arr = np.array(img)
plt.imshow(arr, cmap="gray" if arr.ndim == 2 else None)
plt.tight_layout()
plt.show()
20 · Clean up the Ray actor#
Once you’re done running inference, it’s a good practice to free up resources:
ray.kill(worker, no_restart=True)→ stops theModelWorkeractor and releases its GPU.del worker+gc.collect()→ drop local references so Python’s garbage collector can clean up.
This ensures the GPU is no longer pinned by the actor and becomes available for other jobs.
# 20.
# stop the actor process and free its GPU
ray.kill(worker, no_restart=True)
# drop local references so nothing pins it
del worker
# Forcing garbage collection is optional:
# - Cluster resources are already freed by ray.kill()
# - Python will clean up the local handle eventually
# - gc.collect() is usually unnecessary unless debugging memory issues
gc.collect()
End of introduction to Ray Train#
02 · Integrating Ray Train with Ray Data#
In this module you extend distributed training with Ray Train by adding Ray Data to the pipeline. Instead of relying on a local PyTorch DataLoader, you stream batches directly from a distributed Ray Dataset, enabling scalable preprocessing and just-in-time data loading across the cluster.
What you learn and take away#
When to integrate Ray Data with Ray Train—for example, for CPU-heavy preprocessing, online augmentations, or multi-format data ingestion.
How to replace
DataLoaderwithiter_torch_batches()to stream batches into your training loop.How to shard, shuffle, and preprocess data in parallel across the cluster before feeding it into GPUs.
How to define a training loop that consumes Ray Dataset shards instead of DataLoader tuples.
How to prepare datasets (for example, Parquet format) so they can be efficiently read and transformed with Ray Data.
How to pass Ray Datasets into the
TorchTrainerwith thedatasetsparameter.
With Ray Data, you can scale preprocessing and training independently—CPUs handle input pipelines, GPUs focus on training—ensuring higher utilization and throughput in your distributed workloads.
Note that the code blocks for this module depends on the previous module, Introduction to Ray Train.
Integrating Ray Train with Ray Data#
Use both Ray Train and Ray Data when you face one of the following challenges:
Challenge |
Detail |
Solution |
|---|---|---|
Need to perform online or just-in-time data processing |
The training pipeline requires processing data on the fly, such as data augmentation, normalization, or other transformations that may differ for each training epoch. |
Ray Train’s integration with Ray Data makes it easy to implement just-in-time data processing. |
Need to improve hardware utilization |
Training and data processing need to be scaled independently to keep GPUs fully utilized, especially when preprocessing is CPU-intensive. |
Ray Data can distribute data processing across multiple CPU nodes, while Ray Train runs the training loop on GPUs. |
Need a consistent interface for loading data |
The training process may need to load data from various sources, such as Parquet, CSV, or lakehouses. |
Ray Data provides a consistent interface for loading, shuffling, sharding, and batching data for training loops. |
01 · Define training loop with Ray Data#
Reimplement the training loop, but this time using Ray Data instead of a PyTorch DataLoader.
Key differences from the previous version:
Data loader → Built with
build_data_loader_ray_train_ray_data(), which streams batches from a Ray Dataset shard (details in the following block).Batching → Still split by
global_batch_size // world_size, but batches are now dictionaries with keys"image"and"label".No device management needed → Ray Data automatically moves batches to the correct device, so you no longer have to call
sampler.set_epoch()orto("cuda").
The rest of the loop (forward pass, loss computation, backward pass, optimizer step, metric logging, and checkpointing) stays the same.
This pattern shows how seamlessly Ray Data integrates with Ray Train, replacing DataLoader while keeping the training logic identical.
# 01. Training loop using Ray Data
def train_loop_ray_train_ray_data(config: dict):
# Same as before: define loss, model, optimizer
criterion = CrossEntropyLoss()
model = load_model_ray_train()
optimizer = Adam(model.parameters(), lr=1e-3)
# Different: build data loader from Ray Data instead of PyTorch DataLoader
global_batch_size = config["global_batch_size"]
batch_size = global_batch_size // ray.train.get_context().get_world_size()
data_loader = build_data_loader_ray_train_ray_data(batch_size=batch_size)
# Same: loop over epochs
for epoch in range(config["num_epochs"]):
# Different: no sampler.set_epoch(), Ray Data handles shuffling internally
# Different: batches are dicts {"image": ..., "label": ...} not tuples
for batch in data_loader:
outputs = model(batch["image"])
loss = criterion(outputs, batch["label"])
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Same: report metrics and save checkpoint each epoch
metrics = print_metrics_ray_train(loss, epoch)
save_checkpoint_and_metrics_ray_train(model, metrics)
02 · Build DataLoader from Ray Data#
Instead of using PyTorch’s DataLoader, you can build a loader from a Ray Dataset shard.
ray.train.get_dataset_shard("train")→ retrieves the shard of the training dataset assigned to the current worker..iter_torch_batches()→ streams the shard as PyTorch-compatible batches.Each batch is a dictionary (for example,
{"image": tensor, "label": tensor}).Supports options like
batch_sizeandprefetch_batchesfor performance tuning.
This integration ensures that data is sharded, shuffled, and moved to the right device automatically, while still looking and feeling like a familiar PyTorch data loader.
Note: Use iter_torch_batches to build a PyTorch-compatible data loader from a Ray Dataset.
# 02. Build a Ray Data–backed data loader
def build_data_loader_ray_train_ray_data(batch_size: int, prefetch_batches: int = 2):
# Different: instead of creating a PyTorch DataLoader,
# fetch the training dataset shard for this worker
dataset_iterator = ray.train.get_dataset_shard("train")
# Convert the shard into a PyTorch-style iterator
# - Returns dict batches: {"image": ..., "label": ...}
# - prefetch_batches controls pipeline buffering
data_loader = dataset_iterator.iter_torch_batches(
batch_size=batch_size, prefetch_batches=prefetch_batches
)
return data_loader
03 · Prepare dataset for Ray Data#
Ray Data works best with data in tabular formats such as Parquet.
In this step:
Convert the MNIST dataset into a pandas DataFrame with two columns:
"image"→ raw image arrays"label"→ digit class (0–9)
Write the DataFrame to disk in Parquet format under
/mnt/cluster_storage/.
Parquet is efficient for both reading and distributed processing, making it a good fit for Ray Data pipelines.
# 03. Convert MNIST dataset into Parquet for Ray Data
# Build a DataFrame with image arrays and labels
df = pd.DataFrame({
"image": dataset.data.tolist(), # raw image pixels (as lists)
"label": dataset.targets # digit labels 0–9
})
# Persist the dataset in Parquet format (columnar, efficient for Ray Data)
df.to_parquet("/mnt/cluster_storage/MNIST.parquet")
04 · Load dataset into Ray Data#
Now that the training data is stored as Parquet, you can load it back into a Ray Dataset:
Use
ray.data.read_parquet()to create a distributed Ray Dataset from the Parquet file.Each row has two columns:
"image"(raw pixel array) and"label"(digit class).The dataset is automatically sharded across the Ray cluster, so multiple workers can read and process it in parallel.
This Ray Dataset can be passed to the TorchTrainer for distributed training.
# 04. Load the Parquet dataset into a Ray Dataset
# Read the Parquet file → creates a distributed Ray Dataset
train_ds = ray.data.read_parquet("/mnt/cluster_storage/MNIST.parquet")
05 · Define image transformation#
To make the dataset usable by PyTorch, preprocess the raw image arrays with the same steps that PyTorch data loader does.
Define a function
transform_images(row)that:Converts the
"image"array fromnumpyinto a PIL image.Applies the standard PyTorch transforms:
ToTensor()→ converts the image to a tensor.Normalize((0.5,), (0.5,))→ scales pixel values to the range [-1, 1].
Replaces the
"image"entry in the row with the transformed tensor.
This function is applied in parallel across the Ray Dataset.
# 05. Define preprocessing transform for Ray Data
def transform_images(row: dict):
# Convert numpy array to a PIL image, then apply TorchVision transforms
transform = Compose([
ToTensor(), # convert to tensor
Normalize((0.5,), (0.5,)) # normalize to [-1, 1]
])
# Ensure image is in uint8 before conversion
image_arr = np.array(row["image"], dtype=np.uint8)
# Apply transforms and replace the "image" field with tensor
row["image"] = transform(Image.fromarray(image_arr))
return row
Note: Unlike the PyTorch DataLoader, the preprocessing can now occur on any node in the cluster.
The data is passed to training workers through the ray object store (a distributed in-memory object store).
06 · Apply transformations with Ray Data#
Apply the preprocessing function to the dataset using map():
train_ds.map(transform_images)→ runs thetransform_imagesfunction on every row of the dataset.Transformations are executed in parallel across the cluster, so preprocessing can scale independently of training.
The transformed dataset now has:
"image"→ normalized PyTorch tensors"label"→ unchanged integer labels
This makes the dataset ready to be streamed into the training loop.
# 06. Apply the preprocessing transform across the Ray Dataset
# Run transform_images() on each row (parallelized across cluster workers)
train_ds = train_ds.map(transform_images)
07 · Configure TorchTrainer with Ray Data#
Now, connect the Ray Dataset to the training loop using the datasets parameter in TorchTrainer:
datasets={"train": train_ds}→ makes the transformed dataset available to the training loop as the"train"shard.train_loop_ray_train_ray_data→ the per-worker training loop that consumes Ray Data batches.train_loop_config→ passes hyperparameters (num_epochs,global_batch_size).scaling_config→ specifies the number of workers and GPUs to use (same as before).run_config→ defines storage for checkpoints and metrics.
This setup allows Ray Train to automatically shard and stream the Ray Dataset into each worker during training.
# 07. Configure TorchTrainer with Ray Data integration
# Wrap Ray Dataset in a dict → accessible as "train" inside the training loop
datasets = {"train": train_ds}
trainer = TorchTrainer(
train_loop_ray_train_ray_data, # training loop consuming Ray Data
train_loop_config={ # hyperparameters
"num_epochs": 1,
"global_batch_size": 512,
},
scaling_config=scaling_config, # number of workers + GPU/CPU resources
run_config=RunConfig(
storage_path=storage_path,
name="dist-MNIST-res18-ray-data"
), # where to store checkpoints/logs
datasets=datasets, # provide Ray Dataset shards to workers
)
08 · Launch training with Ray Data#
Finally, call trainer.fit() to start the distributed training job.
Ray automatically:
Launch workers according to the
scaling_config.Stream sharded, preprocessed batches from the Ray Dataset into each worker.
Run the training loop (
train_loop_ray_train_ray_data) on every worker in parallel.Report metrics and save checkpoints to the configured storage path.
With this call, you now have a fully end-to-end distributed pipeline where Ray Data handles ingestion + preprocessing and Ray Train handles multi-GPU training.
# 08. Start the distributed training job with Ray Data integration
# Launches the training loop across all workers
# - Streams preprocessed Ray Dataset batches into each worker
# - Reports metrics and checkpoints to cluster storage
trainer.fit()
End of module 02 · Integrating Ray Train with Ray Data#
03 · Fault tolerance in Ray Train#
In this module you learn how Ray Train handles failures and how to make your training jobs resilient with checkpointing and recovery. You see both automatic retries and manual restoration, and how to modify the training loop so it can safely resume from the latest checkpoint.
What you learn and take away#
How Ray Train uses automatic retries to restart failed workers without losing progress.
How to modify the training loop with
get_checkpoint()to enable checkpoint loading.How to save additional state (for example, optimizer and epoch) alongside the model for full recovery.
How to configure
FailureConfigto set retry behavior.How to perform a manual restoration if retries are exhausted, resuming training from the last checkpoint.
Why checkpointing to persistent storage is essential for reliable recovery.
With fault tolerance enabled, you can run long, large-scale training jobs confidently—knowing they can recover from failures without starting over.
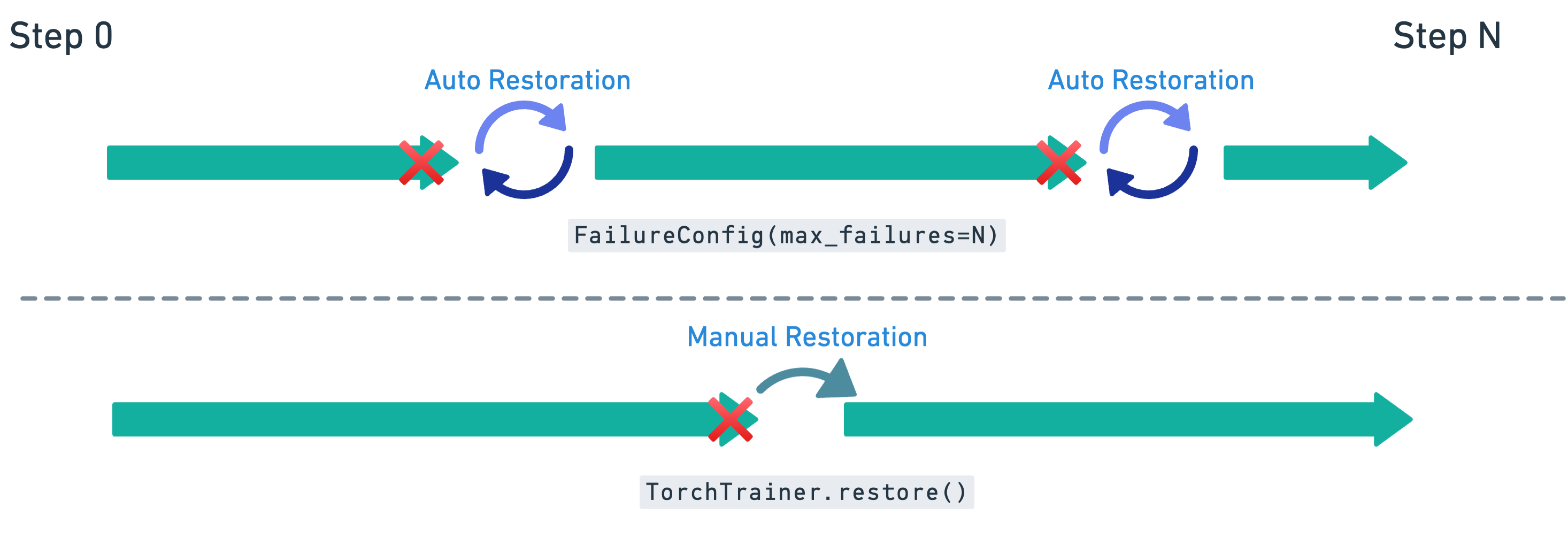
01 · Modify training loop to enable checkpoint loading#
To support fault tolerance, extend the training loop so it can resume from a previously saved checkpoint.
Key additions:
Call
ray.train.get_checkpoint()to check if a checkpoint is available.If found, restore:
The model state (
model.pt)The optimizer state (
optimizer.pt)The last completed epoch (
extra_state.pt)
Update
start_epochso training resumes from the correct place.
The rest of the loop (forward pass, backward pass, optimizer step, and metrics reporting) is the same, except it now starts from start_epoch instead of 0.
# 01. Training loop with checkpoint loading for fault tolerance
def train_loop_ray_train_with_checkpoint_loading(config: dict):
# Same setup as before: loss, model, optimizer
criterion = CrossEntropyLoss()
model = load_model_ray_train()
optimizer = Adam(model.parameters(), lr=1e-3)
# Same data loader logic as before
global_batch_size = config["global_batch_size"]
batch_size = global_batch_size // ray.train.get_context().get_world_size()
data_loader = build_data_loader_ray_train_ray_data(batch_size=batch_size)
# Default: start at epoch 0 unless a checkpoint is available
start_epoch = 0
# Attempt to load from latest checkpoint
checkpoint = ray.train.get_checkpoint()
if checkpoint:
# Continue training from a previous checkpoint
with checkpoint.as_directory() as ckpt_dir:
# Restore model + optimizer state
model_state_dict = torch.load(
os.path.join(ckpt_dir, "model.pt"),
)
# Load the model and optimizer state
model.module.load_state_dict(model_state_dict)
optimizer.load_state_dict(
torch.load(os.path.join(ckpt_dir, "optimizer.pt"))
)
# Resume from last epoch + 1
start_epoch = (
torch.load(os.path.join(ckpt_dir, "extra_state.pt"))["epoch"] + 1
)
# Same training loop as before except it starts at a parameterized start_epoch
for epoch in range(start_epoch, config["num_epochs"]):
for batch in data_loader:
outputs = model(batch["image"])
loss = criterion(outputs, batch["label"])
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Report metrics and save model + optimizer + epoch state
metrics = print_metrics_ray_train(loss, epoch)
# We now save the optimizer and epoch state in addition to the model
save_checkpoint_and_metrics_ray_train_with_extra_state(
model, metrics, optimizer, epoch
)
02 · Save full checkpoint with extra state#
To support fault-tolerant recovery, extend checkpoint saving to include not just the model, but also the optimizer state and the current epoch.
model.pt→ model weights (unwrap DDP with.module).optimizer.pt→ optimizer state for resuming training seamlessly.extra_state.pt→ stores metadata (here, the current epoch).
Only the rank-0 worker writes the checkpoint to avoid duplication, but all workers still call ray.train.report() to keep the loop synchronized.
This ensures that if training is interrupted, Ray Train can restore model weights, optimizer progress, and the correct epoch before continuing.
# 02. Save checkpoint with model, optimizer, and epoch state
def save_checkpoint_and_metrics_ray_train_with_extra_state(
model: torch.nn.Module,
metrics: dict[str, float],
optimizer: torch.optim.Optimizer,
epoch: int,
) -> None:
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
checkpoint = None
# Only rank-0 worker saves files to disk
if ray.train.get_context().get_world_rank() == 0:
# Save all state required for full recovery
torch.save(
model.module.state_dict(), # unwrap DDP before saving
os.path.join(temp_checkpoint_dir, "model.pt"),
)
torch.save(
optimizer.state_dict(), # include optimizer state
os.path.join(temp_checkpoint_dir, "optimizer.pt"),
)
torch.save(
{"epoch": epoch}, # store last completed epoch
os.path.join(temp_checkpoint_dir, "extra_state.pt"),
)
# Package into a Ray checkpoint
checkpoint = ray.train.Checkpoint.from_directory(temp_checkpoint_dir)
# Report metrics and attach checkpoint (only rank-0 attaches checkpoint)
ray.train.report(
metrics,
checkpoint=checkpoint,
)
03 · Configure automatic retries with FailureConfig#
Now that the training loop can load from checkpoints, enable automatic retries in case of worker or node failures.
FailureConfig(max_failures=3)→ allows the job to retry up to three times before giving up.Pass this
failure_configintoRunConfigso Ray Train knows how to handle failures.When a failure happens, Ray automatically:
Restart the failed workers.
Reload the latest checkpoint.
Resume training from the last saved epoch.
This setup makes training jobs resilient to transient hardware or cluster issues without requiring manual intervention.
# 03. Configure TorchTrainer with fault-tolerance enabled
# Allow up to 3 automatic retries if workers fail
failure_config = ray.train.FailureConfig(max_failures=3)
experiment_name = "fault-tolerant-MNIST-vit"
trainer = TorchTrainer(
train_loop_per_worker=train_loop_ray_train_with_checkpoint_loading, # fault-tolerant loop
train_loop_config={ # hyperparameters
"num_epochs": 1,
"global_batch_size": 512,
},
scaling_config=scaling_config, # resource scaling as before
run_config=ray.train.RunConfig(
name="fault-tolerant-MNIST-vit",
storage_path=storage_path, # persistent checkpoint storage
failure_config=failure_config, # enable automatic retries
),
datasets=datasets, # Ray Dataset shard for each worker
)
04 · Launch fault-tolerant training#
Finally, call trainer.fit() to start the training job.
With the fault-tolerant loop and FailureConfig in place, Ray Train can:
Run the training loop on all workers.
If a failure occurs (for example, worker crash, node preemption), automatically restart workers.
Reload the latest checkpoint and continue training without losing progress.
This makes your training job robust against transient infrastructure failures.
# 04. Start the fault-tolerant training job
# Launches training with checkpointing + automatic retries enabled
# If workers fail, Ray will reload the latest checkpoint and resume
trainer.fit()
05 · Manual restoration from checkpoints#
If the maximum number of retries is reached, you can still manually restore training by creating a new TorchTrainer with the same configuration:
Use the same
train_loop_ray_train_with_checkpoint_loadingso the loop can resume from a checkpoint.Provide the same
run_config(name, storage path, and failure config).Pass in the same dataset and scaling configuration.
Ray Train detects the latest checkpoint in the specified storage_path and resume training from that point.
# 05. Manually restore a trainer from the last checkpoint
restored_trainer = TorchTrainer(
train_loop_per_worker=train_loop_ray_train_with_checkpoint_loading, # loop supports checkpoint loading
train_loop_config={ # hyperparameters must match
"num_epochs": 1,
"global_batch_size": 512,
},
scaling_config=scaling_config, # same resource setup as before
run_config=ray.train.RunConfig(
name="fault-tolerant-MNIST-vit", # must match previous run name
storage_path=storage_path, # path where checkpoints are saved
failure_config=failure_config, # still allow retries
),
datasets=datasets, # same dataset as before
)
06 · Resume training from the last checkpoint#
Calling restored_trainer.fit() continues training from the most recent checkpoint found in the specified storage path.
If all epochs are already completed in the previous run, the trainer terminates immediately.
If training is interrupted mid-run, it resumes from the saved epoch, restoring both the model and optimizer state.
The returned
Resultobject confirms that training picked up correctly and contains metrics, checkpoints, and logs.
# 06. Resume training from the last checkpoint
# Fit the restored trainer → continues from last saved epoch
# If all epochs are already complete, training ends immediately
result = restored_trainer.fit()
# Display final training results (metrics, checkpoints, etc.)
result
07 · Clean up cluster storage#
Finally, remove any tutorial artifacts from persistent cluster storage:
Deletes the downloaded MNIST dataset (
/mnt/cluster_storage/MNIST).Deletes the training outputs (
/mnt/cluster_storage/training).Deletes the Parquet dataset used for Ray Data (
/mnt/cluster_storage/MNIST.parquet).
This keeps your shared storage clean and avoids leftover data or files from occupying space.
Run this only when you’re sure you no longer need the data, checkpoints, or Parquet files.
# 07. Cleanup Cluster Storage
# Paths to remove → include MNIST data, training outputs, and MNIST.parquet
paths_to_delete = [
"/mnt/cluster_storage/MNIST",
"/mnt/cluster_storage/training",
"/mnt/cluster_storage/MNIST.parquet",
]
for path in paths_to_delete:
if os.path.exists(path):
# Handle directories vs. files
if os.path.isdir(path):
shutil.rmtree(path) # recursively delete directory
else:
os.remove(path) # delete single file
print(f"Deleted: {path}")
else:
print(f"Not found: {path}")
Wrapping up and next steps#
You completed a full, production-style workflow with Ray Train on Anyscale, then extended it with Ray Data, and finally added fault tolerance. Here’s what you accomplished across the three modules:
Introduction to Ray Train#
Scaled PyTorch DDP with
TorchTrainerusingScalingConfigandRunConfig.Wrapped code for multi-GPU with
prepare_model()andprepare_data_loader().Reported metrics and saved checkpoints with
ray.train.report(...)(rank-0 checkpointing best practice).Inspected results from the
Resultobject and served GPU inference with a Ray actor.
Module 02 · Integrating Ray Train with Ray Data#
Prepared MNIST as Parquet and loaded it as a Ray Dataset.
Streamed batches with
iter_torch_batches()and consumed dict batches in the training loop.Passed datasets to the trainer with
datasets={"train": ...}.Decoupled CPU preprocessing from GPU training for better utilization and throughput.
Module 03 · Fault tolerance in Ray Train#
Enabled resume-from-checkpoint using
ray.train.get_checkpoint().Saved full state (model, optimizer, epoch) for robust restoration.
Configured
FailureConfig(max_failures=...)for automatic retries.Performed manual restoration by re-creating a trainer with the same
RunConfig.
Where to go next#
Scale up: Increase
num_workers, try multi-node clusters, or switch to FSDP withprepare_model(parallel_strategy="fsdp").Input pipelines: Add augmentations, caching, and windowed shuffles in Ray Data; try multi-file Parquet or lakehouse sources.
Experiment tracking: Log metrics to external systems (Weights & Biases, MLflow) alongside
ray.train.report().Larger models: Integrate DeepSpeed or parameter-efficient fine-tuning templates.
Production-ready: Store checkpoints in cloud storage (S3/GCS/Azure), wire up alerts/dashboards, and add CI for smoke tests.
Next tutorials in the course#
In the next tutorials, you can find end-to-end workload examples for using Ray Train on Anyscale (for example, recommendation systems, vision, NLP, generative models).
You only need to pick one of these workloads to work through in the course—but feel free to explore more.
With these patterns—distributed training, scalable data ingestion, and resilient recovery—you’re ready to run larger, longer, and more reliable training jobs on Anyscale.