KubeRay memory and scalability benchmark#
Architecture#
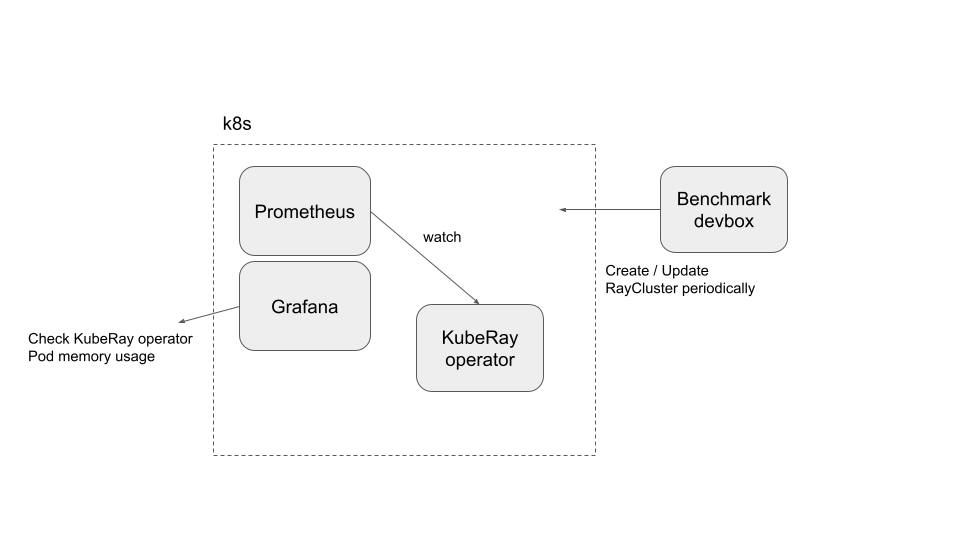
This architecture is not a good practice, but it can fulfill the current requirements.
Preparation#
Clone the KubeRay repository and checkout the master branch. This tutorial requires several files in the repository.
Step 1: Create a new Kubernetes cluster#
Create a GKE cluster with autoscaling enabled. The following command creates a Kubernetes cluster named kuberay-benchmark-cluster on Google GKE. The cluster can scale up to 16 nodes, and each node of type e2-highcpu-16 has 16 CPUs and 16 GB of memory. The following experiments may create up to ~150 Pods in the Kubernetes cluster, and each Ray Pod requires 1 CPU and 1 GB of memory.
gcloud container clusters create kuberay-benchmark-cluster \
--num-nodes=1 --min-nodes 0 --max-nodes 16 --enable-autoscaling \
--zone=us-west1-b --machine-type e2-highcpu-16
Step 2: Install Prometheus and Grafana#
# Path: kuberay/
./install/prometheus/install.sh
Follow “Step 2: Install Kubernetes Prometheus Stack via Helm chart” in prometheus-grafana.md to install the kube-prometheus-stack v48.2.1 chart and related custom resources.
Step 3: Install a KubeRay operator#
Follow this document to install the latest stable KubeRay operator via Helm repository.
Step 4: Run experiments#
Step 4.1: Make sure the
kubectlCLI can connect to your GKE cluster. If not, rungcloud auth login.Step 4.2: Run an experiment.
# You can modify `memory_benchmark_utils` to run the experiment you want to run. # (path: benchmark/memory_benchmark/scripts) python3 memory_benchmark_utils.py | tee benchmark_log
Step 4.3: Follow prometheus-grafana.md to access Grafana’s dashboard.
Sign into the Grafana dashboard.
Click on “Dashboards”.
Select “Kubernetes / Compute Resources / Pod”.
Locate the “Memory Usage” panel for the KubeRay operator Pod.
Select the time range, then click on “Inspect” followed by “Data” to download the memory usage data of the KubeRay operator Pod.
Step 4.4: Delete all RayCluster custom resources.
kubectl delete --all rayclusters.ray.io --namespace=default
Step 4.5: Repeat Step 4.2 to Step 4.4 for other experiments.
Experiments#
This benchmark is based on three benchmark experiments:
Experiment 1: Launch a RayCluster with 1 head and no workers. A new cluster is initiated every 20 seconds until there are a total of 150 RayCluster custom resources.
Experiment 2: Create a Kubernetes cluster, with only 1 RayCluster. Add 5 new worker Pods to this RayCluster every 60 seconds until the total reaches 150 Pods.
Experiment 3: Create a 5-node (1 head + 4 workers) RayCluster every 60 seconds up to 30 RayCluster custom resources.
Based on the survey for KubeRay users, the benchmark target is set at 150 Ray Pods to cover most use cases.
Experiment results (KubeRay v0.6.0)#
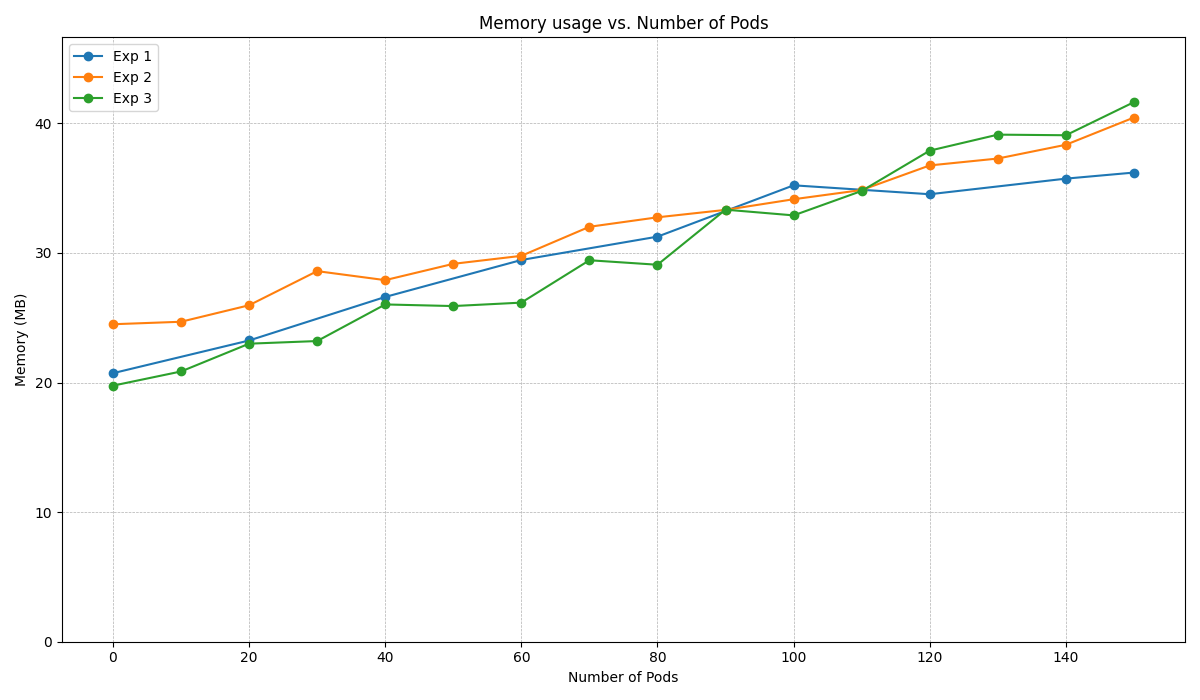
You can generate the above figure by running:
# (path: benchmark/memory_benchmark/scripts) python3 experiment_figures.py # The output image `benchmark_result.png` will be stored in `scripts/`.
As shown in the figure, the memory usage of the KubeRay operator Pod is highly and positively correlated to the number of Pods in the Kubernetes cluster. In addition, the number of custom resources in the Kubernetes cluster does not have a significant impact on the memory usage.
Note that the x-axis “Number of Pods” is the number of Pods that are created rather than running. If the Kubernetes cluster does not have enough computing resources, the GKE Autopilot adds a new Kubernetes node into the cluster. This process may take a few minutes, so some Pods may be pending in the process. This lag may can explain why the memory usage is somewhat throttled.