Data Loading and Preprocessing#
Ray Train integrates with Ray Data to offer a performant and scalable streaming solution for loading and preprocessing large datasets. Key advantages include:
Streaming data loading and preprocessing, scalable to petabyte-scale data.
Scaling out heavy data preprocessing to CPU nodes, to avoid bottlenecking GPU training.
Automatic and fast failure recovery.
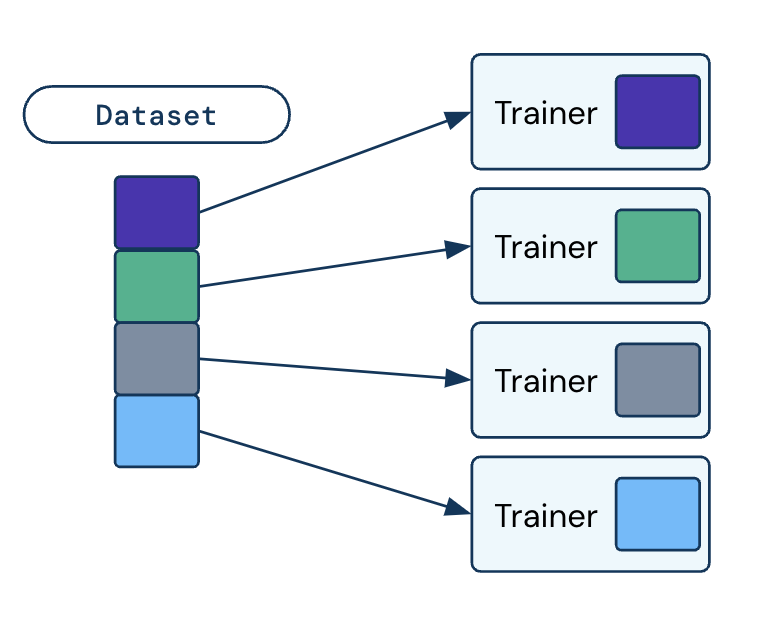
Automatic on-the-fly data splitting across distributed training workers.
For more details about Ray Data, check out the Ray Data documentation.
Note
In addition to Ray Data, you can continue to use framework-native data utilities with Ray Train, such as PyTorch Dataset, Hugging Face Dataset, and Lightning DataModule.
In this guide, we will cover how to incorporate Ray Data into your Ray Train script, and different ways to customize your data ingestion pipeline.
Quickstart#
Install Ray Data and Ray Train:
pip install -U "ray[data,train]"
Data ingestion can be set up with four basic steps:
Create a Ray Dataset from your input data.
Apply preprocessing operations to your Ray Dataset.
Input the preprocessed Dataset into the Ray Train Trainer, which internally splits the dataset equally in a streaming way across the distributed training workers.
Consume the Ray Dataset in your training function.
import torch
import ray
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
# Set this to True to use GPU.
# If False, do CPU training instead of GPU training.
use_gpu = False
# Step 1: Create a Ray Dataset from in-memory Python lists.
# You can also create a Ray Dataset from many other sources and file
# formats.
train_dataset = ray.data.from_items([{"x": [x], "y": [2 * x]} for x in range(200)])
# Step 2: Preprocess your Ray Dataset.
def increment(batch):
batch["y"] = batch["y"] + 1
return batch
train_dataset = train_dataset.map_batches(increment, batch_size="auto")
def train_func():
batch_size = 16
# Step 4: Access the dataset shard for the training worker via
# ``get_dataset_shard``.
train_data_shard = train.get_dataset_shard("train")
# `iter_torch_batches` returns an iterable object that
# yield tensor batches. Ray Data automatically moves the Tensor batches
# to GPU if you enable GPU training.
train_dataloader = train_data_shard.iter_torch_batches(
batch_size=batch_size, dtypes=torch.float32
)
for epoch_idx in range(1):
for batch in train_dataloader:
inputs, labels = batch["x"], batch["y"]
assert type(inputs) == torch.Tensor
assert type(labels) == torch.Tensor
assert inputs.shape[0] == batch_size
assert labels.shape[0] == batch_size
# Only check one batch for demo purposes.
# Replace the above with your actual model training code.
break
# Step 3: Create a TorchTrainer. Specify the number of training workers and
# pass in your Ray Dataset.
# The Ray Dataset is automatically split across all training workers.
trainer = TorchTrainer(
train_func,
datasets={"train": train_dataset},
scaling_config=ScalingConfig(num_workers=2, use_gpu=use_gpu)
)
result = trainer.fit()
from ray import train
# Create the train and validation datasets.
train_data = ray.data.read_csv("./train.csv")
val_data = ray.data.read_csv("./validation.csv")
def train_func_per_worker():
# Access Ray datsets in your train_func via ``get_dataset_shard``.
# Ray Data shards all datasets across workers by default.
train_ds = train.get_dataset_shard("train")
val_ds = train.get_dataset_shard("validation")
# Create Ray dataset iterables via ``iter_torch_batches``.
train_dataloader = train_ds.iter_torch_batches(batch_size=16)
val_dataloader = val_ds.iter_torch_batches(batch_size=16)
...
trainer = pl.Trainer(
# ...
)
# Feed the Ray dataset iterables to ``pl.Trainer.fit``.
trainer.fit(
model,
train_dataloaders=train_dataloader,
val_dataloaders=val_dataloader
)
trainer = TorchTrainer(
train_func,
# You can pass in multiple datasets to the Trainer.
datasets={"train": train_data, "validation": val_data},
scaling_config=ScalingConfig(num_workers=4),
)
trainer.fit()
import ray
import ray.train
from huggingface_hub import HfFileSystem
...
# Create the train and evaluation datasets using HfFileSystem.
fs = HfFileSystem()
train_data = ray.data.read_parquet("hf://datasets/your-dataset/train/", filesystem=fs)
eval_data = ray.data.read_parquet("hf://datasets/your-dataset/validation/", filesystem=fs)
def train_func():
# Access Ray datsets in your train_func via ``get_dataset_shard``.
# Ray Data shards all datasets across workers by default.
train_ds = ray.train.get_dataset_shard("train")
eval_ds = ray.train.get_dataset_shard("evaluation")
# Create Ray dataset iterables via ``iter_torch_batches``.
train_iterable_ds = train_ds.iter_torch_batches(batch_size=16)
eval_iterable_ds = eval_ds.iter_torch_batches(batch_size=16)
...
args = transformers.TrainingArguments(
...,
max_steps=max_steps # Required for iterable datasets
)
trainer = transformers.Trainer(
...,
model=model,
train_dataset=train_iterable_ds,
eval_dataset=eval_iterable_ds,
)
# Prepare your Transformers Trainer
trainer = ray.train.huggingface.transformers.prepare_trainer(trainer)
trainer.train()
trainer = TorchTrainer(
train_func,
# You can pass in multiple datasets to the Trainer.
datasets={"train": train_data, "evaluation": val_data},
scaling_config=ScalingConfig(num_workers=4, use_gpu=True),
)
trainer.fit()
Loading data#
Ray Datasets can be created from many different data sources and formats. For more details, see Loading Data.
Preprocessing data#
Ray Data supports a wide range of preprocessing operations that you can use to transform data prior to training.
For general preprocessing, see Transforming Data.
For tabular data, see Preprocessing Structured Data.
For PyTorch tensors, see Transformations with torch tensors.
For optimizing expensive preprocessing operations, see Caching the preprocessed dataset.
Inputting and splitting data#
Your preprocessed datasets can be passed into a Ray Train Trainer (e.g. TorchTrainer) through the datasets argument.
The datasets passed into the Trainer’s datasets can be accessed inside of the train_loop_per_worker run on each distributed training worker by calling ray.train.get_dataset_shard().
Ray Data splits all datasets across the training workers by default. get_dataset_shard() returns 1/n of the dataset, where n is the number of training workers.
Ray Data does data splitting in a streaming fashion on the fly.
Note
Be aware that because Ray Data splits the evaluation dataset, you have to aggregate the evaluation results across workers. You might consider using TorchMetrics (example) or utilities available in other frameworks that you can explore.
This behavior can be overwritten by passing in the dataset_config argument. For more information on configuring splitting logic, see Splitting datasets.
Consuming data#
Inside the train_loop_per_worker, each worker can access its shard of the dataset via ray.train.get_dataset_shard().
This data can be consumed in a variety of ways:
To create a generic Iterable of batches, you can call
iter_batches().To create a replacement for a PyTorch DataLoader, you can call
iter_torch_batches().
For more details on how to iterate over your data, see Iterating over data.
Starting with PyTorch data#
Some frameworks provide their own dataset and data loading utilities. For example:
PyTorch: Dataset & DataLoader
Hugging Face: Dataset
PyTorch Lightning: LightningDataModule
You can still use these framework data utilities directly with Ray Train.
At a high level, you can compare these concepts as follows:
PyTorch API |
HuggingFace API |
Ray Data API |
|---|---|---|
n/a |
For more details, see the following sections for each framework:
Option 1 (with Ray Data):
Convert your PyTorch Dataset to a Ray Dataset.
Pass the Ray Dataset into the TorchTrainer via
datasetsargument.Inside your
train_loop_per_worker, you can access the dataset viaray.train.get_dataset_shard().Create a dataset iterable via
ray.data.DataIterator.iter_torch_batches().
For more details, see the Migrating from PyTorch Datasets and DataLoaders.
Option 2 (without Ray Data):
Instantiate the Torch Dataset and DataLoader directly in the
train_loop_per_worker.Use the
ray.train.torch.prepare_data_loader()utility to set up the DataLoader for distributed training.
The LightningDataModule is created with PyTorch Datasets and DataLoaders. You can apply the same logic here.
Option 1 (with Ray Data):
Convert your Hugging Face Dataset to a Ray Dataset. For instructions, see Ray Data for Hugging Face.
Pass the Ray Dataset into the TorchTrainer via the
datasetsargument.Inside your
train_loop_per_worker, access the sharded dataset viaray.train.get_dataset_shard().Create a iterable dataset via
ray.data.DataIterator.iter_torch_batches().Pass the iterable dataset while initializing
transformers.Trainer.Wrap your transformers trainer with the
ray.train.huggingface.transformers.prepare_trainer()utility.
Option 2 (without Ray Data):
Instantiate the Hugging Face Dataset directly in the
train_loop_per_worker.Pass the Hugging Face Dataset into
transformers.Trainerduring initialization.
Tip
When using Torch or Hugging Face Datasets directly without Ray Data, make sure to instantiate your Dataset inside the train_loop_per_worker.
Instantiating the Dataset outside of the train_loop_per_worker and passing it in via global scope
can cause errors due to the Dataset not being serializable.
Note
When using PyTorch DataLoader with more than 1 worker, you should set the
process start method to be forkserver or spawn.
Forking Ray Actors and Tasks is an anti-pattern that
can lead to unexpected issues such as deadlocks.
data_loader = DataLoader(
dataset,
num_workers=2,
multiprocessing_context=multiprocessing.get_context("forkserver"),
...
)
Splitting datasets#
By default, Ray Train splits all datasets across workers using Dataset.streaming_split. Each worker sees a disjoint subset of the data, instead of iterating over the entire dataset.
If want to customize which datasets are split, pass in a DataConfig to the Trainer constructor.
For example, to split only the training dataset, do the following:
import ray
from ray import train
from ray.train import ScalingConfig
from ray.train.torch import TorchTrainer
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
train_ds, val_ds = ds.train_test_split(0.3)
def train_loop_per_worker():
# Get the sharded training dataset
train_ds = train.get_dataset_shard("train")
for _ in range(2):
for batch in train_ds.iter_batches(batch_size=128):
print("Do some training on batch", batch)
# Get the unsharded full validation dataset
val_ds = train.get_dataset_shard("val")
for _ in range(2):
for batch in val_ds.iter_batches(batch_size=128):
print("Do some evaluation on batch", batch)
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": train_ds, "val": val_ds},
dataset_config=ray.train.DataConfig(
datasets_to_split=["train"],
),
)
my_trainer.fit()
Full customization (advanced)#
For use cases not covered by the default config class, you can also fully customize exactly how your input datasets are split. Define a custom DataConfig class (DeveloperAPI). The DataConfig class is responsible for that shared setup and splitting of data across nodes.
# Note that this example class is doing the same thing as the basic DataConfig
# implementation included with Ray Train.
from typing import Optional, Dict, List
import ray
from ray import train
from ray.train.torch import TorchTrainer
from ray.train import DataConfig, ScalingConfig
from ray.data import Dataset, DataIterator, NodeIdStr
from ray.actor import ActorHandle
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
def train_loop_per_worker():
# Get an iterator to the dataset we passed in below.
it = train.get_dataset_shard("train")
for _ in range(2):
for batch in it.iter_batches(batch_size=128):
print("Do some training on batch", batch)
class MyCustomDataConfig(DataConfig):
def configure(
self,
datasets: Dict[str, Dataset],
world_size: int,
worker_handles: Optional[List[ActorHandle]],
worker_node_ids: Optional[List[NodeIdStr]],
**kwargs,
) -> List[Dict[str, DataIterator]]:
assert len(datasets) == 1, "This example only handles the simple case"
# Configure Ray Data for ingest.
ctx = ray.data.DataContext.get_current()
ctx.execution_options = DataConfig.default_ingest_options()
# Split the stream into shards.
iterator_shards = datasets["train"].streaming_split(
world_size, equal=True, locality_hints=worker_node_ids
)
# Return the assigned iterators for each worker.
return [{"train": it} for it in iterator_shards]
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": ds},
dataset_config=MyCustomDataConfig(),
)
my_trainer.fit()
The subclass must be serializable, since Ray Train copies it from the driver script to the driving actor of the Trainer. Ray Train calls its configure method on the main actor of the Trainer group to create the data iterators for each worker.
In general, you can use DataConfig for any shared setup that has to occur ahead of time before the workers start iterating over data. The setup runs at the start of each Trainer run.
Random shuffling#
Randomly shuffling data for each epoch can be important for model quality depending on what model you are training.
Ray Data provides multiple options for random shuffling, see Shuffling Data for more details.
Enabling reproducibility#
When developing or hyperparameter tuning models, reproducibility is important during data ingest so that data ingest does not affect model quality. Follow these three steps to enable reproducibility:
Step 1: Enable deterministic execution in Ray Datasets by setting the preserve_order flag in the DataContext.
import ray
# Preserve ordering in Ray Datasets for reproducibility.
ctx = ray.data.DataContext.get_current()
ctx.execution_options.preserve_order = True
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
Step 2: Set a seed for any shuffling operations:
seedargument torandom_shuffleseedargument torandomize_block_orderlocal_shuffle_seedargument toiter_batches
Step 3: Follow the best practices for enabling reproducibility for your training framework of choice. For example, see the Pytorch reproducibility guide.
Preprocessing structured data#
Note
This section is for tabular/structured data. The recommended way for preprocessing unstructured data is to use
Ray Data operations such as map_batches. See the Ray Data Working with Pytorch guide for more details.
For tabular data, use Ray Data preprocessors, which implement common data preprocessing operations. You can use this with Ray Train Trainers by applying them on the dataset before passing the dataset into a Trainer. For example:
import base64
import numpy as np
from tempfile import TemporaryDirectory
import ray
from ray import train
from ray.train import Checkpoint, ScalingConfig
from ray.train.torch import TorchTrainer
from ray.data.preprocessors import Concatenator, StandardScaler
dataset = ray.data.read_csv("s3://anonymous@air-example-data/breast_cancer.csv")
# Create preprocessors to scale some columns and concatenate the results.
scaler = StandardScaler(columns=["mean radius", "mean texture"])
columns_to_concatenate = dataset.columns()
columns_to_concatenate.remove("target")
concatenator = Concatenator(columns=columns_to_concatenate, dtype=np.float32)
# Compute dataset statistics and get transformed datasets. Note that the
# fit call is executed immediately, but the transformation is lazy.
dataset = scaler.fit_transform(dataset)
dataset = concatenator.fit_transform(dataset)
def train_loop_per_worker():
context = train.get_context()
print(context.get_metadata()) # prints {"preprocessor_pkl": ...}
# Get an iterator to the dataset we passed in below.
it = train.get_dataset_shard("train")
for _ in range(2):
# Prefetch 10 batches at a time.
for batch in it.iter_batches(batch_size=128, prefetch_batches=10):
print("Do some training on batch", batch)
# Save a checkpoint.
with TemporaryDirectory() as temp_dir:
train.report(
{"score": 2.0},
checkpoint=Checkpoint.from_directory(temp_dir),
)
# Serialize the preprocessor. Since serialize() returns bytes,
# convert to base64 string for JSON compatibility.
serialized_preprocessor = base64.b64encode(scaler.serialize()).decode("ascii")
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": dataset},
metadata={"preprocessor_pkl": serialized_preprocessor},
)
# Get the fitted preprocessor back from the result metadata.
metadata = my_trainer.fit().checkpoint.get_metadata()
# Decode from base64 before deserializing
serialized_data = base64.b64decode(metadata["preprocessor_pkl"])
print(StandardScaler.deserialize(serialized_data))
This example persists the fitted preprocessor using the Trainer(metadata={...}) constructor argument. This arg specifies a dict that is available from TrainContext.get_metadata() and checkpoint.get_metadata() for checkpoints that the Trainer saves. This design enables the recreation of the fitted preprocessor for inference.
Performance tips#
Prefetching batches#
While iterating over a dataset for training, you can increase prefetch_batches in iter_batches or iter_torch_batches to further increase performance. While training on the current batch, this approach launches background threads to fetch and process the next N batches.
This approach can help if training is bottlenecked on cross-node data transfer or on last-mile preprocessing such as converting batches to tensors or executing collate_fn. However, increasing prefetch_batches leads to more data that needs to be held in heap memory. By default, prefetch_batches is set to 1.
For example, the following code prefetches 10 batches at a time for each training worker:
import ray
from ray import train
from ray.train import ScalingConfig
from ray.train.torch import TorchTrainer
ds = ray.data.read_text(
"s3://anonymous@ray-example-data/sms_spam_collection_subset.txt"
)
def train_loop_per_worker():
# Get an iterator to the dataset we passed in below.
it = train.get_dataset_shard("train")
for _ in range(2):
# Prefetch 10 batches at a time.
for batch in it.iter_batches(batch_size=128, prefetch_batches=10):
print("Do some training on batch", batch)
my_trainer = TorchTrainer(
train_loop_per_worker,
scaling_config=ScalingConfig(num_workers=2),
datasets={"train": ds},
)
my_trainer.fit()
Avoid heavy transformation in collate_fn#
The collate_fn parameter in iter_batches or iter_torch_batches allows you to transform data before feeding it to the model. This operation happens locally in the training workers. Avoid adding a heavy transformation in this function as it may become the bottleneck. Instead, apply the transformation with map or map_batches before passing the dataset to the Trainer. When your expensive transformation requires batch_size as input, such as text tokenization, you can scale it out to Ray Data for better performance.
Caching the preprocessed dataset#
If your preprocessed Dataset is small enough to fit in Ray object store memory (by default this is 30% of total cluster RAM), materialize the preprocessed dataset in Ray’s built-in object store, by calling materialize() on the preprocessed dataset. This method tells Ray Data to compute the entire preprocessed and pin it in the Ray object store memory. As a result, when iterating over the dataset repeatedly, the preprocessing operations do not need to be re-run. However, if the preprocessed data is too large to fit into Ray object store memory, this approach will greatly decreases performance as data needs to be spilled to and read back from disk.
Transformations that you want to run per-epoch, such as randomization, should go after the materialize call.
from typing import Dict
import numpy as np
import ray
# Load the data.
train_ds = ray.data.read_parquet("s3://anonymous@ray-example-data/iris.parquet")
# Define a preprocessing function.
def normalize_length(batch: Dict[str, np.ndarray]) -> Dict[str, np.ndarray]:
new_col = batch["sepal.length"] / np.max(batch["sepal.length"])
batch["normalized.sepal.length"] = new_col
del batch["sepal.length"]
return batch
# Preprocess the data. Transformations that are made before the materialize call
# below are only run once.
train_ds = train_ds.map_batches(normalize_length, batch_size="auto")
# Materialize the dataset in object store memory.
# Only do this if train_ds is small enough to fit in object store memory.
train_ds = train_ds.materialize()
# Dummy augmentation transform.
def augment_data(batch):
return batch
# Add per-epoch preprocessing. Transformations that you want to run per-epoch, such
# as data augmentation or randomization, should go after the materialize call.
train_ds = train_ds.map_batches(augment_data, batch_size="auto")
# Pass train_ds to the Trainer
Adding CPU-only nodes to your cluster#
If the GPU training is bottlenecked on expensive CPU preprocessing and the preprocessed Dataset is too large to fit in object store memory, then materializing the dataset doesn’t work. In this case, Ray’s native support for heterogeneous resources enables you to simply add more CPU-only nodes to your cluster, and Ray Data automatically scales out CPU-only preprocessing tasks to CPU-only nodes, making GPUs more saturated.
In general, adding CPU-only nodes can help in two ways: * Adding more CPU cores helps further parallelize preprocessing. This approach is helpful when CPU compute time is the bottleneck. * Increasing object store memory, which 1) allows Ray Data to buffer more data in between preprocessing and training stages, and 2) provides more memory to make it possible to cache the preprocessed dataset. This approach is helpful when memory is the bottleneck.
Isolating Ray Data worker processes from training nodes#
You may sometimes want to prevent Ray Data CPU tasks from running on training worker nodes when training workers themselves run CPU or RAM-heavy operations such as storing large local shuffle buffers or running expensive collate functions. Launching more Ray Data processes would oversubscribe the training worker nodes. Instead, the Ray Data tasks should run on a separate set of CPU nodes in your heterogeneous cluster (for example, 4 GPU training nodes and 4 CPU-only nodes).
One workaround is to force full-node exclusion by reserving all CPUs per training worker via
resources_per_worker={"CPU": node_cpus // num_gpus_per_node, "GPU": 1} in ScalingConfig.
This method is fragile since it’s tied to node shapes, and Ray Data also doesn’t exclude other
resources such as object store memory properly, since the typical configuration is to only take up logical
CPUs and GPUs.
The recommended approach is to use subclusters to pin the
training Dataset to CPU-only nodes. This correctly scopes the memory budget to only the nodes
where data tasks can actually run. It requires adding labels to your worker node configurations and setting the
label_selector in two places:
import ray
from ray.data import ExecutionOptions
from ray.train import DataConfig
from ray.train.torch import TorchTrainer
# (1) Pin construction-time tasks (schema inference, file listing).
ctx = ray.data.DataContext.get_current().copy()
ctx.execution_options.label_selector = {"ray-subcluster": "data"}
with ray.data.DataContext.current(ctx):
train_dataset = ray.data.read_parquet(...)
# (2) Pin per-worker ingest — Train replaces ds.context options
# wholesale, so the selector must be restated here.
trainer = TorchTrainer(
...,
datasets={"train": train_dataset},
dataset_config=DataConfig(
datasets_to_split=["train"],
execution_options={
"train": ExecutionOptions(
label_selector={"ray-subcluster": "data"}
),
},
),
)
Tip
Before resorting to isolating Ray Data tasks from training nodes, consider offloading that heavy work from training workers to the data pipeline instead: scale out expensive collation and use map_batches-based shuffling in place of large local shuffle buffers. These reduce CPU pressure on training workers and often eliminate the need for node isolation entirely.
Balancing data production and consumption#
Ideally, data production (dataset processing) and data consumption (training ingestion) happen at the same rate. When production outpaces consumption, excess data is written to the object store, which can spill to disk, which in turn decreases Ray Data throughput and leads to out of disk errors. Ray Data’s backpressure system automatically balances production and consumption, but if you are still running into issues, you can try tuning the following:
Use fewer CPUs for data production: If you are using
map_batches(), you can set the number of workers withcomputeand the number of CPUs per worker withnum_cpus.Limit object store usage per dataset: Set a per-dataset object store memory limit using each dataset’s execution options. Ray Data’s backpressure system will slow down production once the object store memory limit is reached.
train_ds = ray.data.read_parquet("s3://bucket/train") val_ds = ray.data.read_parquet("s3://bucket/val") train_ds.context.execution_options.resource_limits = ray.data.ExecutionResources( object_store_memory=50 * 1024**3, ) val_ds.context.execution_options.resource_limits = ray.data.ExecutionResources( object_store_memory=50 * 1024**3, )
See Advanced: Performance Tips and Tuning for more info on how to tune Ray Data.
More data ingest guides#
Weighted Dataset Mixing — combine multiple datasets with target row ratios for training.
Scaling Collation Functions — scale out expensive collation functions to Ray Data.