Validating checkpoints asynchronously#
During training, you may want to validate the model periodically to monitor training progress. The standard way to do this is to periodically switch between training and validation within the training loop. Instead, Ray Train allows you to asynchronously validate the model in a separate Ray task, which does the following:
Runs validation in parallel without blocking the training loop
Runs validation on different, potentially cheaper hardware than training, since validation doesn’t require optimizer states or gradients and can use 2-4x less GPU memory
Leverages autoscaling to launch user-specified machines only for the duration of the validation
Lets training continue immediately after saving a checkpoint with partial metrics (for example, loss) and then receives validation metrics (for example, accuracy) as soon as they are available. If the initial and validated metrics share the same key, the validated metrics overwrite the initial metrics.
When to use async validation#
Asynchronous validation is preferable to alternating between training and validation within the same training loop in the following scenarios:
Validation takes a large percentage of total training time. If validation is a significant fraction of your end-to-end training time, running it asynchronously can substantially reduce wall clock time by overlapping validation with training.
Cheaper GPUs are available for validation. Validation doesn’t require optimizer states or gradients, so it can use 2-4x less GPU memory than training. If you have a pool of cheaper GPUs or an autoscaling setup that can provision them, async validation lets you run validation on those cheaper machines instead of occupying your expensive training GPUs.
Training throughput stops scaling linearly with more workers. As worker count increases, allreduce overhead grows and limits training speed, so doubling workers no longer doubles throughput. Validation, however, scales more linearly since it requires no gradient synchronization. Asynchronous validation can therefore utilize otherwise idle cluster capacity without impacting training.
The best way to know if async validation helps your workload is to try it. Converting is straightforward (see the tutorial below), so you can run both approaches and compare.
Tutorial#
First, define a validation_fn that takes a ray.train.Checkpoint to validate
and any number of json-serializable keyword arguments. This function should return a dictionary
of metrics from that validation.
The following is a simple example for teaching purposes only. It is impractical
because the validation task always runs on cpu; for a more realistic example, see
Write a distributed validation function.
import os
import torch
import ray.train
import ray.data
# Define Ray Data validation dataset outside validation function because it is not json serializable
validation_dataset = ...
def validation_fn(checkpoint: ray.train.Checkpoint) -> dict:
# Load the checkpoint
model = ...
with checkpoint.as_directory() as checkpoint_dir:
model_state_dict = torch.load(os.path.join(checkpoint_dir, "model.pt"))
model.load_state_dict(model_state_dict)
model.eval()
# Perform validation on the data
total_accuracy = 0
with torch.no_grad():
for batch in validation_dataset.iter_torch_batches(batch_size=128):
images, labels = batch["image"], batch["label"]
outputs = model(images)
total_accuracy += (outputs.argmax(1) == labels).sum().item()
return {"score": total_accuracy / len(validation_dataset)}
Note
In this example, the validation dataset is a ray.data.Dataset object, which is not json-serializable. We therefore include it with the validation_fn closure instead of passing it as a keyword argument.
Warning
Don’t pass large objects to the validation_fn because Ray Train runs it as a Ray task and
serializes all captured variables. Instead, package large objects in the Checkpoint and
access them from shared storage later as explained in Saving and Loading Checkpoints.
Next, register your validation_fn with your trainer by settings its validation_config argument to a
ValidationConfig object that contains your validation_fn
and any default keyword arguments you want to pass to your validation_fn.
Next, within your rank 0 worker’s training loop, call ray.train.report() with validation
set to True, which will call your validation_fn with the default keyword arguments you passed to the trainer.
Alternatively, you can set validation to a ValidationTaskConfig object
that contains keyword arguments that will override matching keyword arguments you passed to the trainer. If
validation is False, Ray Train will not run validation.
import tempfile
from ray.data import ExecutionOptions
from ray.train import ValidationConfig, ValidationTaskConfig
def train_func(config: dict) -> None:
...
epochs = ...
model = ...
rank = ray.train.get_context().get_world_rank()
for epoch in epochs:
... # training step
if rank == 0:
training_metrics = {"loss": ..., "epoch": epoch}
local_checkpoint_dir = tempfile.mkdtemp()
torch.save(
model.module.state_dict(),
os.path.join(local_checkpoint_dir, "model.pt"),
)
ray.train.report(
training_metrics,
checkpoint=ray.train.Checkpoint.from_directory(local_checkpoint_dir),
checkpoint_upload_mode=ray.train.CheckpointUploadMode.ASYNC,
validation=ValidationTaskConfig(fn_kwargs={
"train_run_name": ray.train.get_context().get_experiment_name(),
"epoch": epoch,
}),
)
else:
ray.train.report({}, None)
def run_trainer() -> ray.train.Result:
# 1) Construction-time tasks (parquet schema inference, file listing)
# read the current DataContext. Pin them to "training" with a copy of
# the DataContext applied via the DataContext.current() context
# manager — scoped to the `with` block so it doesn't leak. See
# https://docs.ray.io/en/latest/data/concurrent-dataset-execution.html.
ctx = ray.data.DataContext.get_current().copy()
ctx.execution_options.label_selector = {"ray-subcluster": "training"}
with ray.data.DataContext.current(ctx):
train_dataset = ray.data.read_parquet(...)
trainer = ray.train.torch.TorchTrainer(
train_func,
validation_config=ValidationConfig(fn=validation_fn),
# Pass training dataset in datasets arg to split it across training workers
datasets={"train": train_dataset},
# 2) DataConfig.execution_options REPLACES ds.context.execution_options
# wholesale at training start, dropping anything not re-specified
# (including label_selector). Restate the selector here so per-worker
# ingest stays pinned to "training".
dataset_config=ray.train.DataConfig(
datasets_to_split=["train"],
execution_options={
"train": ExecutionOptions(
label_selector={"ray-subcluster": "training"}
),
},
),
scaling_config=ray.train.ScalingConfig(
num_workers=2,
use_gpu=True,
# Use powerful GPUs for training
accelerator_type="A100",
),
)
return trainer.fit()
Finally, after training is done, you can access your checkpoints and their associated metrics with the
ray.train.Result object. See Inspecting Training Results for more details.
Write a distributed validation function#
The validation_fn above runs in a single Ray task, but you can improve its performance by spawning
even more Ray tasks or actors. The Ray team recommends doing this with one of the following approaches:
Creating a
ray.train.torch.TorchTrainerthat only does validation, not training.Using
ray.data.Dataset.map_batches()to calculate metrics on a validation set.
Choose an approach#
You should use TorchTrainer if:
You want to keep your existing validation logic and avoid migrating to Ray Data. The training function API lets you fully customize the validation loop to match your current setup.
Your validation code depends on running within a Torch process group — for example, your metric aggregation logic uses collective communication calls, or your model parallelism setup requires cross-GPU communication during the forward pass.
You want a more consistent training and validation experience. The
map_batchesapproach involves running multiple Ray Data Datasets in a single ray cluster; we are currently working on better support for this.
You should use map_batches if:
You care about validation performance. Preliminary benchmarks show that
map_batchesis faster.You prefer Ray Data’s native metric aggregation APIs over PyTorch, where you must implement aggregation manually using low-level collective operations or rely on third-party libraries such as torchmetrics.
Example: validation with Ray Train TorchTrainer#
Here is a validation_fn that uses a TorchTrainer to calculate average cross entropy
loss on a validation set. Note the following about this example:
TorchTraineris typically used for training, but you can use it for validation like in this example allowing different resource requirements for training and validation, for example, A100 for training and A10G for validation.The validation train function returns its metrics directly from worker 0 rather than calling
ray.train.reportwhich is accessible viaresult.return_value. These values can’t be torch tensors and must be python based likeray.train.report.
import torchmetrics
from torch.nn import CrossEntropyLoss
import ray.train.torch
from ray.data import ExecutionOptions
def eval_only_train_fn(config_dict: dict) -> dict:
# Load the checkpoint
model = ...
with config_dict["checkpoint"].as_directory() as checkpoint_dir:
model_state_dict = torch.load(os.path.join(checkpoint_dir, "model.pt"))
model.load_state_dict(model_state_dict)
model.cuda().eval()
# Set up metrics and data loaders
criterion = CrossEntropyLoss()
mean_valid_loss = torchmetrics.MeanMetric().cuda()
test_data_shard = ray.train.get_dataset_shard("validation")
test_dataloader = test_data_shard.iter_torch_batches(batch_size=128)
# Compute metric and return it directly from the train function
with torch.no_grad():
for batch in test_dataloader:
images, labels = batch["image"], batch["label"]
outputs = model(images)
loss = criterion(outputs, labels)
mean_valid_loss(loss)
return {"score": mean_valid_loss.compute().item()}
def validation_fn(checkpoint: ray.train.Checkpoint, train_run_name: str, epoch: int) -> dict:
trainer = ray.train.torch.TorchTrainer(
eval_only_train_fn,
train_loop_config={"checkpoint": checkpoint},
scaling_config=ray.train.ScalingConfig(
num_workers=2, use_gpu=True, accelerator_type="A10G"
),
# Give unique name to validation run so it does not attempt to load placeholder checkpoint.
# Also allows you to better associate training runs with validation runs.
run_config=ray.train.RunConfig(
name=f"{train_run_name}_validation_epoch_{epoch}"
),
# Use weaker GPUs for validation
datasets={"validation": validation_dataset},
# Pin to the "validation" subcluster so it doesn't compete with
# training. See https://docs.ray.io/en/latest/data/concurrent-dataset-execution.html.
dataset_config=ray.train.DataConfig(
execution_options={
"validation": ExecutionOptions(
label_selector={"ray-subcluster": "validation"}
),
},
),
)
result = trainer.fit()
# return_value holds the value returned by train function of worker 0
return result.return_value
Example: validation with Ray Data map_batches#
The following is a validation_fn that uses ray.data.Dataset.map_batches() to
calculate average accuracy on a validation set. To learn more about how to use
map_batches for batch inference, see End-to-end: Offline Batch Inference.
import ray.data
class Predictor:
def __init__(self, checkpoint: ray.train.Checkpoint):
self.model = ...
with checkpoint.as_directory() as checkpoint_dir:
model_state_dict = torch.load(os.path.join(checkpoint_dir, "model.pt"))
self.model.load_state_dict(model_state_dict)
self.model.cuda().eval()
def __call__(self, batch: dict) -> dict:
image = torch.as_tensor(batch["image"], dtype=torch.float32, device="cuda")
label = torch.as_tensor(batch["label"], dtype=torch.float32, device="cuda")
pred = self.model(image)
return {"res": (pred.argmax(1) == label).cpu().numpy()}
# Construct ``validation_dataset`` under a DataContext copy pinned to the
# "validation" subcluster. ``Dataset.context`` is a deep copy of the
# current context taken at construction, so the selector is baked in and
# every downstream operator (including the ``map_batches`` below) inherits
# it — no in-function mutation needed. See
# https://docs.ray.io/en/latest/data/concurrent-dataset-execution.html.
ctx = ray.data.DataContext.get_current().copy()
ctx.execution_options.label_selector = {"ray-subcluster": "validation"}
with ray.data.DataContext.current(ctx):
validation_dataset = ray.data.read_parquet(...)
def validation_fn(checkpoint: ray.train.Checkpoint) -> dict:
# Set name to avoid confusion; default name is "Dataset"
validation_dataset.set_name("validation")
eval_res = validation_dataset.map_batches(
Predictor,
batch_size=128,
num_gpus=1,
fn_constructor_kwargs={"checkpoint": checkpoint},
concurrency=2,
)
mean = eval_res.mean(["res"])
return {
"score": mean,
}
Isolating training and validation with subclusters#
When training and validation run concurrently on the same Ray cluster,
they compete for the same nodes by default. To give each phase its own
slice of the cluster — for example, A100s for training and A10Gs for
validation — label your worker pools with a ray-subcluster value and
pin each Dataset to its subcluster. See Run multiple Datasets in one cluster
for the background and compute-config setup.
The pattern differs slightly between the TorchTrainer validation_fn
and the map_batches validation_fn, because only the former goes
through ray.train.DataConfig.
TorchTrainer validation_fn. Set the validation Dataset’s selector
through the sub-trainer’s dataset_config:
from ray.data import ExecutionOptions
def validation_fn(checkpoint, ...) -> dict:
trainer = ray.train.torch.TorchTrainer(
...,
datasets={"validation": validation_dataset},
dataset_config=ray.train.DataConfig(
execution_options={
"validation": ExecutionOptions(
label_selector={"ray-subcluster": "validation"}
),
},
),
)
...
map_batches validation_fn. The map_batches path doesn’t take a
DataConfig. Construct validation_dataset under a
DataContext.current() block so the selector is baked into the
Dataset at construction — every downstream operator inherits it:
ctx = ray.data.DataContext.get_current().copy()
ctx.execution_options.label_selector = {"ray-subcluster": "validation"}
with ray.data.DataContext.current(ctx):
validation_dataset = ray.data.read_parquet(...)
def validation_fn(checkpoint) -> dict:
eval_res = validation_dataset.map_batches(...)
...
Training-side configuration. A Train pipeline needs the selector specified in two places — they cover different phases and are not redundant:
At Dataset construction, via the
DataContext.current()context manager, so construction-time tasks (parquet schema inference, file listing) land on training nodes.In the trainer’s
dataset_config, because Train wholesale replacesds.context.execution_optionswithDataConfig’s per-dataset entry at training start. Anything not restated inDataConfig.execution_options—label_selectorincluded — is dropped, so per-worker ingest would lose its pinning.
from ray.data import ExecutionOptions
def run_trainer() -> ray.train.Result:
# (1) Pin construction-time tasks.
ctx = ray.data.DataContext.get_current().copy()
ctx.execution_options.label_selector = {"ray-subcluster": "training"}
with ray.data.DataContext.current(ctx):
train_dataset = ray.data.read_parquet(...)
# (2) Pin per-worker ingest — Train replaces ds.context options
# wholesale, so the selector must be restated here.
trainer = ray.train.torch.TorchTrainer(
...,
datasets={"train": train_dataset},
dataset_config=ray.train.DataConfig(
datasets_to_split=["train"],
execution_options={
"train": ExecutionOptions(
label_selector={"ray-subcluster": "training"}
),
},
),
)
...
Note
For interleaved validation — where you reuse the training workers
to validate on a separate “validation” Dataset inside the same
TorchTrainer — pass both Datasets to datasets={...} and give
both an entry in DataConfig.execution_options so they’re each
scoped to their own subcluster:
from ray.data import ExecutionOptions
dataset_config = ray.train.DataConfig(
datasets_to_split=["train", "validation"],
execution_options={
"train": ExecutionOptions(
label_selector={"ray-subcluster": "training"}
),
"validation": ExecutionOptions(
label_selector={"ray-subcluster": "validation"}
),
},
)
Tuning asynchronous validation#
Overlapping validation and training#
Asynchronous validation is most beneficial when training and validation fully overlap. If one finishes before the other, some workers sit idle. Autoscaling lets you spin up workers only for the duration of validation, which mitigates this but doesn’t fully eliminate the gap.
You can tune the following knobs to overlap validation and training as closely as possible:
Number of workers: Tune the number of validation workers relative to training workers so that the two phases overlap as closely as possible.
Batch size: A larger batch size typically improves throughput, but it can negatively impact training convergence and may lead to out-of-memory (OOM) errors.
Validation frequency: Choose a validation cadence and dataset size that balance overlap with training. Validating too frequently or over too many rows can create a long validation tail. Also note that breaking early from a Ray Data iterator may lead to resource leaks - this will be fixed in a future release.
Ray Data production vs consumption#
See Balancing data production and consumption for tips on balancing data production and consumption rates.
Checkpoint metrics lifecycle#
During the training loop the following happens to your checkpoints and metrics :
You report a checkpoint with some initial metrics, such as training loss, as well as a
ValidationTaskConfigobject that contains the keyword arguments to pass to thevalidation_fn.Ray Train asynchronously runs your
validation_fnwith that checkpoint and configuration.When that validation task completes, Ray Train associates the metrics returned by your
validation_fnwith that checkpoint.After training is done, you can access your checkpoints and their associated metrics with the
ray.train.Resultobject. See Inspecting Training Results for more details.
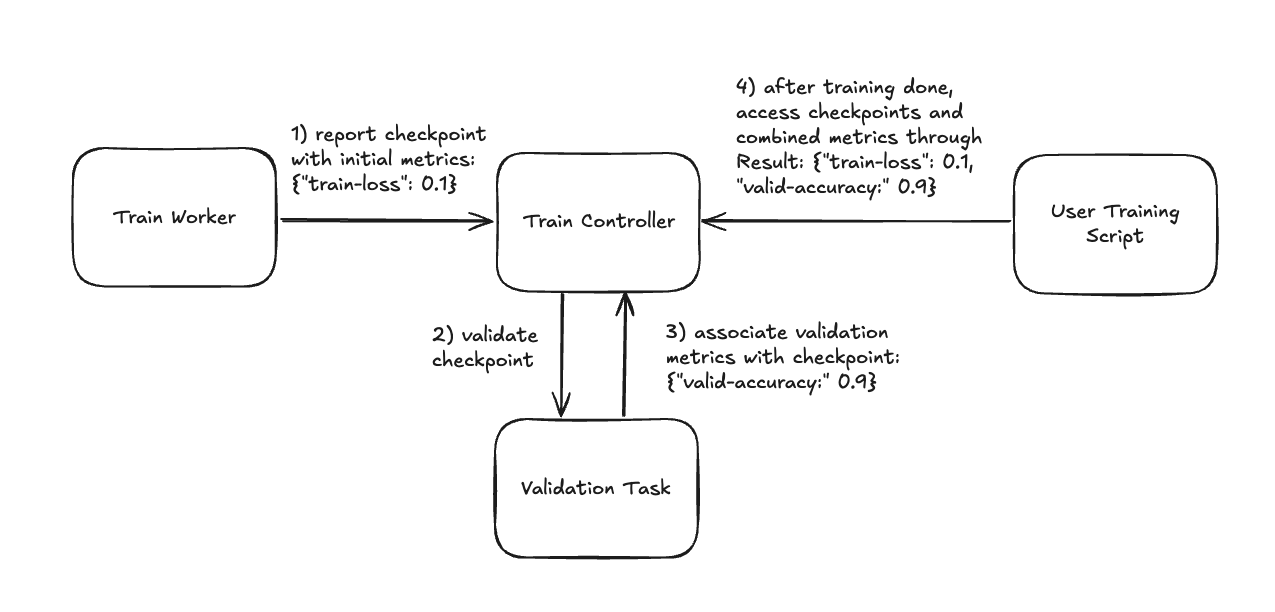
How Ray Train populates checkpoint metrics during training and how you access them after training.#
Experiment tracking#
In normal experiment tracking with Ray Train, you handle creating, logging to, and finishing the experiment tracking run from the rank 0 training worker. However, asynchronous validation complicates this because validation metrics are computed outside of the training worker, in a separate Ray task.
Most modern experiment tracking configurations (for example, W&B distributed training) support writing to the same run from different threads or processes. Other configurations, such as the MLflow fluent API, may not.
Writing to the same run#
If your experiment tracking library supports writing to the same run from different processes, the rank 0 training worker can start the run and the validation task can join it and log validation metrics directly.
import wandb
import ray.train
from ray.train import ValidationConfig, ValidationTaskConfig
entity = "my_entity"
project = "my_project"
num_epochs = ...
def validation_fn(checkpoint: ray.train.Checkpoint, wandb_run_id: str, val_step: int) -> dict:
wandb.init(
entity=entity,
project=project,
settings=wandb.Settings(mode="shared", x_primary=False),
id=wandb_run_id,
)
score = ...
wandb.log({"validation/loss": score, "val_step": val_step})
wandb.finish() # flush the metrics
return {"validation/loss": score}
def train_func():
if ray.train.get_context().get_world_rank() == 0:
run = wandb.init(
entity=entity,
project=project,
settings=wandb.Settings(mode="shared", x_primary=True,)
)
wandb.define_metric("val_step", hidden=True)
wandb.define_metric("train_step", hidden=True)
wandb.define_metric("validation/loss", step_metric="val_step")
wandb.define_metric("train/loss", step_metric="train_step")
for epoch in range(num_epochs):
loss = ...
if ray.train.get_context().get_world_rank() == 0:
wandb.log({"train/loss": loss, "train_step": epoch})
checkpoint = ...
ray.train.report(
{"train/loss": loss},
checkpoint=checkpoint,
validation=ValidationTaskConfig(
fn_kwargs={"wandb_run_id": run.id, "val_step": epoch}
),
)
else:
ray.train.report({}, None)
if ray.train.get_context().get_world_rank() == 0:
wandb.finish()
import mlflow
from mlflow.tracking import MlflowClient
import ray.train
from ray.train import ValidationConfig, ValidationTaskConfig
tracking_uri = "my_uri"
experiment_name = "my_experiment"
num_epochs = ...
def validation_fn(
checkpoint: ray.train.Checkpoint, mlflow_run_id: str, val_step: int
) -> dict:
client = MlflowClient(tracking_uri=tracking_uri)
score = ...
client.log_metric(mlflow_run_id, "val_score", score, step=val_step)
return {"val_score": score}
def train_func():
if ray.train.get_context().get_world_rank() == 0:
client = MlflowClient(tracking_uri=tracking_uri)
experiment = client.get_experiment_by_name(experiment_name)
run = client.create_run(experiment_id=experiment.experiment_id)
for epoch in range(num_epochs):
loss = ...
if ray.train.get_context().get_world_rank() == 0:
client.log_metric(run.info.run_id, "train_loss", loss, step=epoch)
checkpoint = ...
ray.train.report(
{"train_loss": loss},
checkpoint=checkpoint,
validation=ValidationTaskConfig(
fn_kwargs={"mlflow_run_id": run.info.run_id, "val_step": epoch}
),
)
else:
ray.train.report({}, None)
if ray.train.get_context().get_world_rank() == 0:
client.set_terminated(run.info.run_id)
Reliability#
If experiment tracking logging fails (for example, due to a transient network error), you have two options for retrying:
Wrap your logging calls in a try/except block within the
validation_fnand retry the logging manually with your experiment tracker’s API.Use
ray.train.get_all_reported_checkpoints()periodically during training to retrieve all reported checkpoints and their associated metrics, then re-log any missing entries to your experiment tracker.
Writing to different runs#
If your experiment tracking library does not support writing to the same run from different processes, the validation task must start a new run each time it logs validation metrics. Many tracking libraries provide ways to group related runs together so that training and validation runs are still associated.
Use W&B run grouping to group the training run and validation runs together.
Use MLflow parent and child runs to group the training run and validation runs together.