Hyperparameter Tuning with Ray Tune#
Important
This user guide shows how to integrate Ray Train and Ray Tune to tune over distributed hyperparameter runs
for the revamped Ray Train V2 available starting from Ray 2.43 by enabling the environment variable RAY_TRAIN_V2_ENABLED=1.
This user guide assumes that the environment variable has been enabled.
Please see here for information about the deprecation and migration.
Ray Train can be used together with Ray Tune to do hyperparameter sweeps of distributed training runs. This is often useful when you want to do a small sweep over critical hyperparameters, before launching a run with the best performing hyperparameters on all available cluster resources for a long duration.
Quickstart#
In the example below:
Tunerlaunches the tuning job, which runs trials oftrain_driver_fnwith different hyperparameter configurations.train_driver_fn, which (1) takes in a hyperparameter configuration, (2) instantiates aTorchTrainer(or some other framework trainer), and (3) launches the distributed training job.ScalingConfigdefines the number of training workers and resources per worker for a single Ray Train run.train_fn_per_workeris the Python code that executes on each distributed training worker for a trial.
import random
import tempfile
import uuid
import ray.train
import ray.train.torch
import ray.tune
from ray.tune.integration.ray_train import TuneReportCallback
# [1] Define your Ray Train worker code.
def train_fn_per_worker(train_loop_config: dict):
# Unpack train worker hyperparameters.
# Train feeds in the `train_loop_config` defined below.
lr = train_loop_config["lr"]
# training code here...
print(
ray.train.get_context().get_world_size(),
ray.train.get_context().get_world_rank(),
train_loop_config,
)
# model = ray.train.torch.prepare_model(...) # Wrap model in DDP.
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
ray.train.report(
{"loss": random.random()},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
# [2] Define a function that launches the Ray Train run.
def train_driver_fn(config: dict):
# Unpack run-level hyperparameters.
# Tune feeds in hyperparameters defined in the `param_space` below.
num_workers = config["num_workers"]
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
train_loop_config=config["train_loop_config"],
scaling_config=ray.train.ScalingConfig(
num_workers=num_workers,
# Uncomment to use GPUs.
# use_gpu=True,
),
run_config=ray.train.RunConfig(
# [3] Assign unique names to each run.
# Recommendation: use the trial id as part of the run name.
name=f"train-trial_id={ray.tune.get_context().get_trial_id()}",
# [4] (Optional) Pass in a `TuneReportCallback` to propagate
# reported results to the Tuner.
callbacks=[TuneReportCallback()],
# (If multi-node, configure S3 / NFS as the storage path.)
# storage_path="s3://...",
),
)
trainer.fit()
# Launch a single Train run.
# Note that you can only create a TuneReportCallback in a Ray Tune session.
# train_driver_fn({"num_workers": 4, "train_loop_config": {"lr": 1e-3}})
# Launch a sweep of hyperparameters with Ray Tune.
tuner = ray.tune.Tuner(
train_driver_fn,
param_space={
"num_workers": ray.tune.choice([2, 4]),
"train_loop_config": {
"lr": ray.tune.grid_search([1e-3, 3e-4]),
"batch_size": ray.tune.grid_search([32, 64]),
},
},
run_config=ray.tune.RunConfig(
name=f"tune_train_example-{uuid.uuid4().hex[:6]}",
# (If multi-node, configure S3 / NFS as the storage path.)
# storage_path="s3://...",
),
# [5] (Optional) Set the maximum number of concurrent trials
# in order to prevent too many Train driver processes from
# being launched at once.
tune_config=ray.tune.TuneConfig(max_concurrent_trials=2),
)
results = tuner.fit()
print(results.get_best_result(metric="loss", mode="min"))
What does Ray Tune provide?#
Ray Tune provides utilities for:
Defining hyperparameter search spaces and launching multiple trials concurrently on a Ray cluster
This user guide only focuses on the integration layer between Ray Train and Ray Tune. For more details on how to use Ray Tune, refer to the Ray Tune documentation.
Configuring resources for multiple trials#
Ray Tune launches multiple trials which run a user-defined function in a remote Ray actor, where each trial gets a different sampled hyperparameter configuration.
When using Ray Tune by itself, trials do computation directly inside the Ray actor. For example, each trial could request 1 GPU and do some single-process model training within the remote actor itself. When using Ray Train inside Ray Tune functions, the Tune trial is actually not doing extensive computation inside this actor – instead it just acts as a driver process to launch and monitor the Ray Train workers running elsewhere.
Ray Train requests its own resources via the ScalingConfig.
See Configuring Scale and Accelerators for more details.
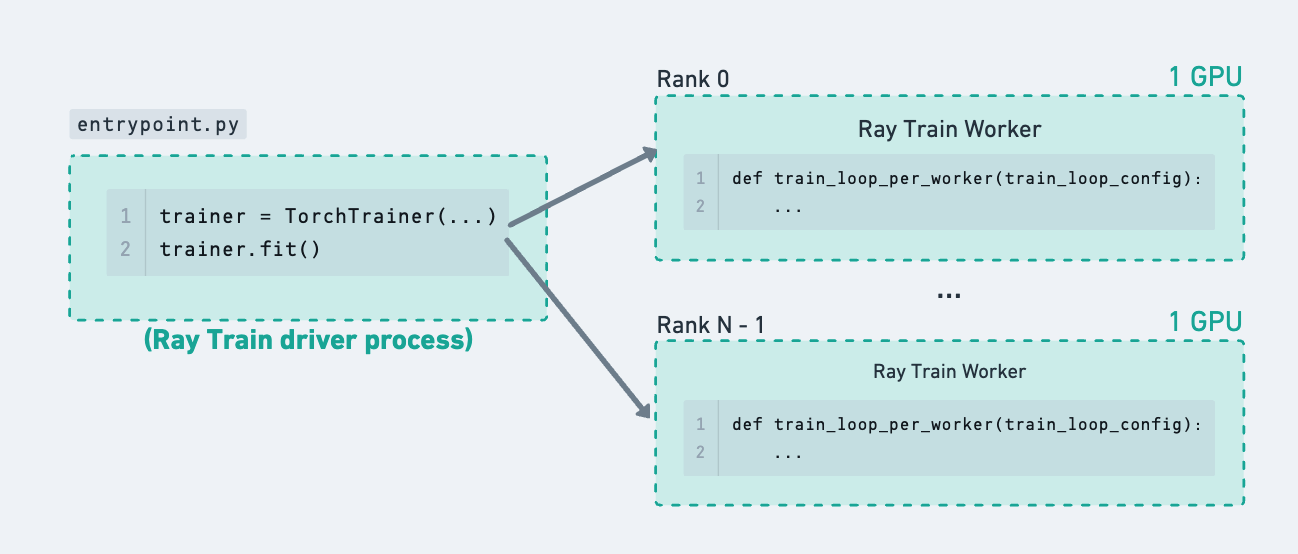
A single Ray Train run to showcase how using Ray Tune in the next figure just adds a layer of hierarchy to this tree of processes.#
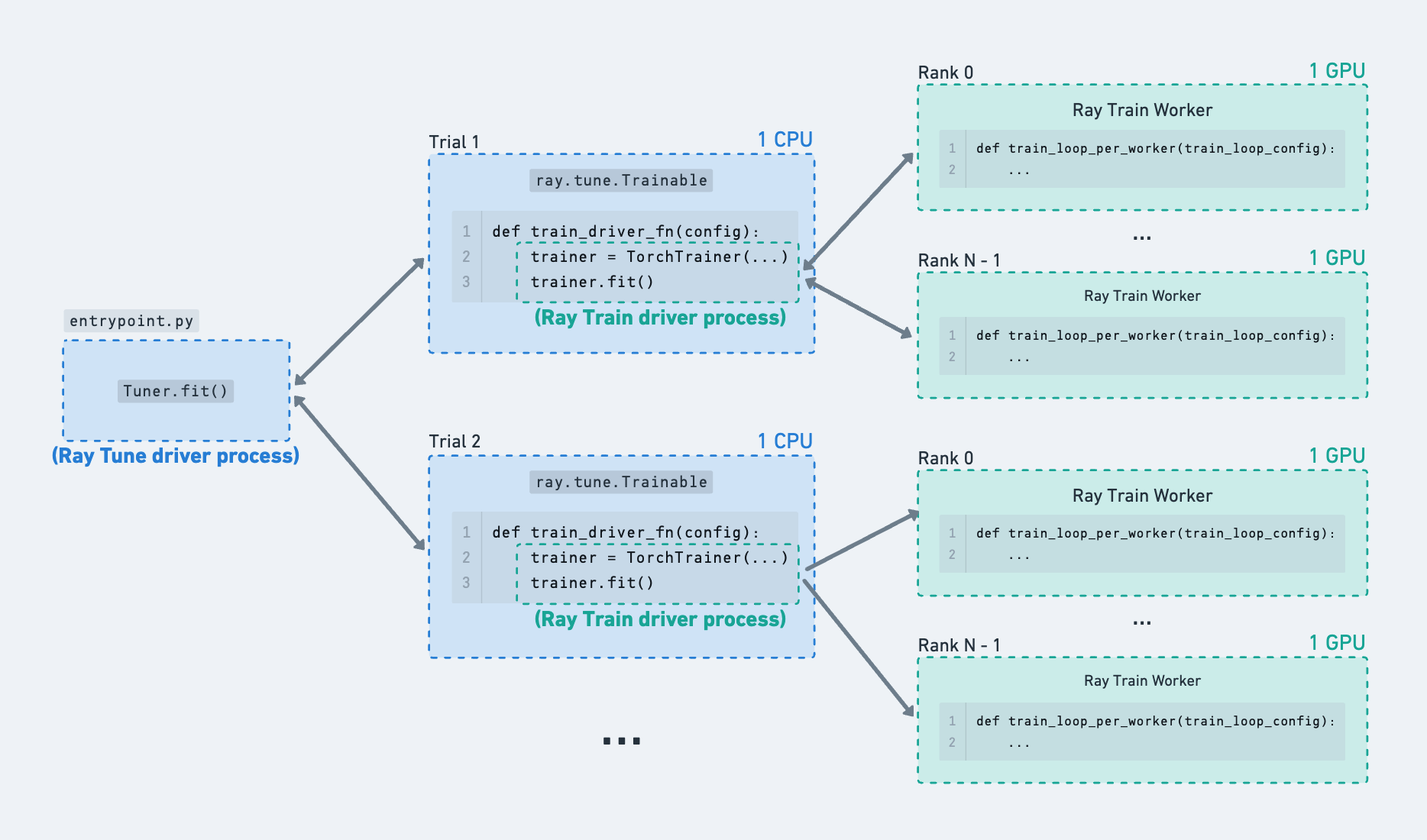
Example of Ray Train runs being launched from within Ray Tune trials.#
Limit the number of concurrent Ray Train runs#
Ray Train runs can only start when resources for all workers can be acquired at once. This means that multiple Tune trials spawning Train runs will be competing for the logical resources available in the Ray cluster.
If there is a limiting cluster resource such as GPUs, then it won’t be possible to run training for all hyperparameter configurations concurrently.
Since the cluster only has enough resources for a handful of trials to run concurrently,
set tune.TuneConfig(max_concurrent_trials) on the Tuner to limit the number of “in-flight” Train runs so that no trial is being starved of resources.
# For a fixed size cluster, calculate this based on the limiting resource (ex: GPUs).
total_cluster_gpus = 8
num_gpu_workers_per_trial = 4
max_concurrent_trials = total_cluster_gpus // num_gpu_workers_per_trial
def train_driver_fn(config: dict):
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
scaling_config=ray.train.ScalingConfig(
num_workers=num_gpu_workers_per_trial, use_gpu=True
),
)
trainer.fit()
tuner = ray.tune.Tuner(
train_driver_fn,
tune_config=ray.tune.TuneConfig(max_concurrent_trials=max_concurrent_trials),
)
As a concrete example, consider a fixed sized cluster with 128 CPUs and 8 GPUs.
The
Tuner(param_space)sweeps over 4 hyperparameter configurations with a grid search:param_space={“train_loop_config”: {“batch_size”: tune.grid_search([8, 16, 32, 64])}}Each Ray Train run is configured to train with 4 GPU workers:
ScalingConfig(num_workers=4, use_gpu=True). Since there are only 8 GPUs, only 2 Train runs can acquire their full set of resources at a time.However, since there are many CPUs available in the cluster, the 4 total Ray Tune trials (which default to requesting 1 CPU) can be launched immediately. This results in 2 extra Ray Tune trial processes being launched, even though their inner Ray Train run just waits for resources until one of the other trials finishes. This introduces some spammy log messages when Train waits for resources. There may also be an excessive number of Ray Tune trial processes if the total number of hyperparameter configurations is large.
To fix this issue, set
Tuner(tune_config=tune.TuneConfig(max_concurrent_trials=2)). Now, only two Ray Tune trial processes will be running at a time. This number can be calculated based on the limiting cluster resource and the amount of that resources required by each trial.
Advanced: Set Train driver resources#
The default Train driver runs as a Ray Tune function with 1 CPU. Ray Tune will schedule these functions to run anywhere on the cluster that has free logical CPU resources.
Recommendation: If you are launching longer-running training jobs or using spot instances, these Tune functions which act as the Ray Train driver process should be run on “safe nodes” that are at lower risk of going down. For example, they should not be scheduled to run on preemptible spot instances and should not be colocated with training workers. This could be the head node or a dedicated CPU node in your cluster.
This is because the Ray Train driver process is responsible for handling fault tolerance of the worker processes, which are more likely to error. Nodes that are running Train workers can crash due to spot preemption or other errors that come up due to the user-defined model training code.
If a Train worker node dies, the Ray Train driver process that is still alive on a different node can gracefully handle the error.
On the other hand, if the driver process dies, then all Ray Train workers will ungracefully exit and some of the run state may not be committed fully.
One way to achieve this behavior is to set custom resources on certain node types and configure the Tune functions to request those resources.
# Cluster setup:
# head_node:
# resources:
# CPU: 16.0
# worker_node_cpu:
# resources:
# CPU: 32.0
# TRAIN_DRIVER_RESOURCE: 1.0
# worker_node_gpu:
# resources:
# GPU: 4.0
import ray.tune
def train_driver_fn(config):
# trainer = TorchTrainer(...)
...
tuner = ray.tune.Tuner(
ray.tune.with_resources(
train_driver_fn,
# Note: 0.01 is an arbitrary value to schedule the actor
# onto the `worker_node_cpu` node type.
{"TRAIN_DRIVER_RESOURCE": 0.01},
),
)
Reporting metrics and checkpoints#
Both Ray Train and Ray Tune provide utilities to help upload and track checkpoints via the ray.train.report and ray.tune.report APIs.
See the Saving and Loading Checkpoints user guide for more details.
If the Ray Train workers report checkpoints, saving another Ray Tune checkpoint at the Train driver level is not needed because it does not hold any extra training state. The Ray Train driver process will already periodically snapshot its status to the configured storage_path, which is further described in the next section on fault tolerance.
In order to access the checkpoints from the Tuner output, you can append the checkpoint path as a metric. The provided TuneReportCallback
does this by propagating reported Ray Train results over to Ray Tune, where the checkpoint path is attached as a separate metric.
Advanced: Fault Tolerance#
In the event that the Ray Tune trials running the Ray Train driver process crash, you can enable trial fault tolerance on the Ray Tune side via:
ray.tune.Tuner(run_config=ray.tune.RunConfig(failure_config)).
Fault tolerance on the Ray Train side is configured and handled separately. See the Handling Failures and Node Preemption user guide for more details.
import tempfile
import ray.tune
import ray.train
import ray.train.torch
def train_fn_per_worker(train_loop_config: dict):
# [1] Train worker restoration logic.
checkpoint = ray.train.get_checkpoint()
if checkpoint:
with checkpoint.as_directory() as temp_checkpoint_dir:
# model.load_state_dict(torch.load(...))
...
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
# torch.save(...)
ray.train.report(
{"loss": 0.1},
checkpoint=ray.train.Checkpoint.from_directory(temp_checkpoint_dir),
)
def train_fn_driver(config: dict):
trainer = ray.train.torch.TorchTrainer(
train_fn_per_worker,
run_config=ray.train.RunConfig(
# [2] Train driver restoration is automatic, as long as
# the (storage_path, name) remains the same across trial restarts.
# The easiest way to do this is to attach the trial ID in the name.
# **Do not include any timestamps or random values in the name.**
name=f"train-trial_id={ray.tune.get_context().get_trial_id()}",
# [3] Enable worker-level fault tolerance to gracefully handle
# Train worker failures.
failure_config=ray.train.FailureConfig(max_failures=3),
# (If multi-node, configure S3 / NFS as the storage path.)
# storage_path="s3://...",
),
)
trainer.fit()
tuner = ray.tune.Tuner(
train_fn_driver,
run_config=ray.tune.RunConfig(
# [4] Enable trial-level fault tolerance to gracefully handle
# Train driver process failures.
failure_config=ray.tune.FailureConfig(max_failures=3)
),
)
tuner.fit()
Advanced: Using Ray Tune callbacks#
Ray Tune callbacks should be passed into the ray.tune.RunConfig(callbacks) at the Tuner level.
For Ray Train users that depend on behavior of built-in or custom Ray Tune callbacks, it’s possible to use them by running Ray Train as a single trial Tune run and passing in the callbacks to the Tuner.
If any callback functionality depends on reported metrics, make sure to pass the ray.tune.integration.ray_train.TuneReportCallback to the trainer callbacks,
which propagates results to the Tuner.
import ray.tune
from ray.tune.integration.ray_train import TuneReportCallback
from ray.tune.logger import TBXLoggerCallback
def train_driver_fn(config: dict):
trainer = TorchTrainer(
...,
run_config=ray.train.RunConfig(..., callbacks=[TuneReportCallback()])
)
trainer.fit()
tuner = ray.tune.Tuner(
train_driver_fn,
run_config=ray.tune.RunConfig(callbacks=[TBXLoggerCallback()])
)
Tuner(trainer) API Deprecation#
The Tuner(trainer) API which directly takes in a Ray Train trainer instance is deprecated as of Ray 2.43 and will be removed in a future release.
Motivation#
This API change provides several benefits:
Better separation of concerns: Decouples Ray Train and Ray Tune responsibilities
Improved configuration experience: Makes hyperparameter and run configuration more explicit and flexible
Migration Steps#
To migrate from the old Tuner(trainer) API to the new pattern:
Enable the environment variable
RAY_TRAIN_V2_ENABLED=1.Replace
Tuner(trainer)with a function-based approach where Ray Train is launched inside a Tune trial.Move your training logic into a driver function that Tune will call with different hyperparameters.
Additional Resources#
Train V2 REP: Technical details about the API change
Train V2 Migration Guide: Full migration guide for Train V2
Hyperparameter Tuning with Ray Tune (Deprecated API): Documentation for the old API