Online serving for DLinear model using Ray Serve#

This tutorial launches an online service that:
deploys trained DLinear model artifacts to generate time series predictions
autoscales based on real-time incoming traffic
covers observability and debugging around the service
Note that this notebook requires that you run the Distributed training of a DLinear model tutorial to generate the pre-trained model artifacts that this tutorial fetches.
Ray Serve is a highly scalable and flexible model serving library for building online inference APIs. You can:
Wrap models and business logic as separate serve deployments and connect them together (pipeline, ensemble, etc.)
Avoid one large service that’s network and compute bounded and an inefficient use of resources
Utilize fractional heterogeneous resources, which isn’t possible with SageMaker, Vertex, KServe, etc., and horizontally scale, with
num_replicasAutoscale up and down based on traffic
Integrate with FastAPI and HTTP
Set up a gRPC service to build distributed systems and microservices
Enable dynamic batching based on batch size, time, etc.
Access a suite of utilities for serving LLMs that are inference-engine agnostic and have batteries-included support for LLM-specific features such as multi-LoRA support

Set up the environment#
First, import the necessary modules and set up the environment for Ray Serve deployment:
import asyncio
import os
import aiohttp
import numpy as np
import pandas as pd
import requests
import torch
from fastapi import FastAPI
# Remove this setting when it becomes the default in a future release.
os.environ["RAY_TRAIN_V2_ENABLED"] = "1"
# Now it's safe to import from Ray.
import ray
from ray import serve
from starlette.requests import Request
Initialize the Ray cluster with the e2e_timeseries module, so that newly spawned workers can import from it.
import e2e_timeseries
from e2e_timeseries.model import DLinear
ray.init(runtime_env={"py_modules": [e2e_timeseries]})
Create a Ray Serve deployment#
Next, define the Ray Serve endpoint for the DLinear model. This implementation uses a reusable class to avoid reloading the model for each request. The deployment supports both Pythonic and HTTP requests with dynamic batching for efficient inference.
DEPLOYMENT_NAME = "dlinear-ett-server"
# Create a FastAPI app that adds endpoints to the Serve deployment.
app = FastAPI(title="DLinear", description="predict future oil temperatures", version="0.1")
@serve.deployment(num_replicas=1, ray_actor_options={"num_cpus": 1, "num_gpus": 1})
@serve.ingress(app)
class DLinearModelServe:
def __init__(self, model_checkpoint_path: str | None = None):
checkpoint = torch.load(model_checkpoint_path, map_location=torch.device("cpu")) # Load to CPU first
self.args = checkpoint["train_args"]
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {self.device}")
# Load model from checkpoint.
self.model = DLinear(self.args).float()
self.model.load_state_dict(checkpoint["model_state_dict"])
print(f"Model loaded successfully from {model_checkpoint_path}")
self.model.to(self.device)
self.model.eval()
@serve.batch(max_batch_size=32, batch_wait_timeout_s=0.1)
async def predict_batch(self, batch_x: list[list[float]]) -> list[list[float]]:
"""
Expects a list of series, where each series is a 1D list of floats/integers.
e.g., [[0.1, 0.2, ..., 0.N], [0.3, 0.4, ..., 0.M]]
Each series is a 1D list of floats/integers.
"""
# Convert list of 1D series to a 2D numpy array (batch_size, seq_len).
batch_x = np.array(batch_x, dtype=np.float32)
batch_x = torch.from_numpy(batch_x).float().to(self.device)
# Ensure batch_x is 3D: (batch_size, seq_len, num_features)
# For univariate 'S' models, num_features is 1.
if batch_x.ndim == 2:
batch_x = batch_x.unsqueeze(-1)
with torch.no_grad():
outputs = self.model(batch_x)
# Output shape: (batch_size, pred_len, features_out)
# Slice to get the prediction length part of the output.
# The [:, :, :] part takes all output features.
# For 'S' (single-feature) forecasting, DLinear typically outputs 1 feature.
# For 'M' (multi-feature) forecasting, DLinear typically outputs multiple features.
outputs = outputs[:, -self.args["pred_len"] :, :]
# If 'S' (single feature forecasting) and the model's output for that single
# feature has an explicit last dimension of 1, squeeze it.
# This approach makes the output a list of 1D series (list of lists of floats).
if outputs.shape[-1] == 1:
outputs = outputs.squeeze(-1) # Shape: (batch_size, pred_len)
outputs_list = outputs.cpu().numpy().tolist()
return outputs_list
@app.post("/predict")
async def predict_endpoint(self, request: Request):
"""
Expects a JSON body, which is a list of floats/integers.
e.g., [0.1, 0.2, ..., 0.N]
where N must be equal to self.args.seq_len.
"""
try:
input_data = await request.json()
if not isinstance(input_data, list):
return {"error": "Invalid input. JSON list of numbers expected."}
if len(input_data) != self.args["seq_len"]:
return {"error": f"Invalid series length. Expected {self.args['seq_len']}, got {len(input_data)}."}
except Exception as e:
return {"error": f"Failed to parse JSON request: {str(e)}"}
# Pass the single list input_data, wrapped in another list, to predict_batch.
# Ray Serve's @serve.batch handles collecting these into a batch for predict_batch.
# The await call returns the specific result for this input_data.
single_prediction_output = await self.predict_batch(input_data)
# single_prediction_output is expected to be a list[float] (the prediction for one series)
return single_prediction_output
# Expose get_seq_len as a GET endpoint.
@app.get("/seq_len")
async def get_sequence_length(self):
return {"seq_len": self.args["seq_len"]}
Ray Serve makes it easy to do model composition where you can compose multiple deployments containing ML models or business logic into a single application. You can independently scale fractional resources and configure each of the deployments.
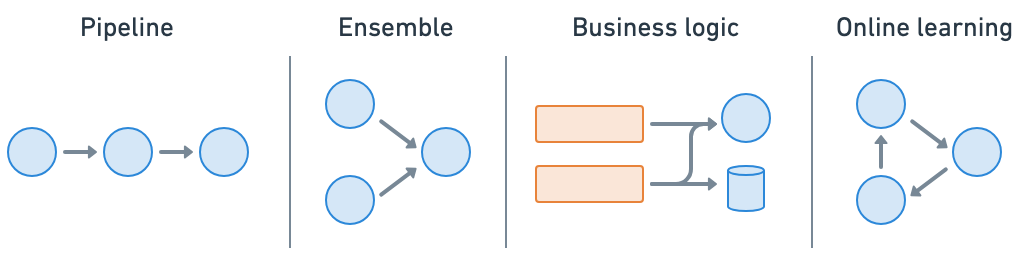
Load the model and start the service#
Load the trained DLinear model and start the Ray Serve deployment. The model checkpoint path loads from the metadata file created during training:
# Load the best checkpoint path from the metadata file created in the training notebook.
best_checkpoint_metadata_fpath = "/mnt/cluster_storage/checkpoints/best_checkpoint_path.txt"
with open(best_checkpoint_metadata_fpath, "r") as f:
best_checkpoint_path = f.read().strip()
def serve_model(best_checkpoint_path):
dlinear_app = DLinearModelServe.bind(model_checkpoint_path=best_checkpoint_path)
# The route_prefix applies to all routes within the FastAPI app.
serve.run(dlinear_app, name=DEPLOYMENT_NAME, route_prefix="/predict_dlinear")
print(f"DLinear model deployment '{DEPLOYMENT_NAME}' is running with FastAPI app.")
print(" Prediction endpoint: http://127.0.0.1:8000/predict_dlinear/predict")
print(" Sequence length endpoint: http://127.0.0.1:8000/predict_dlinear/seq_len")
print("\nTo stop the server, press Ctrl+C in the terminal where it's running.")
serve_model(best_checkpoint_path)
You should see logs indicating that the service is running locally:
INFO 2025-04-09 14:06:55,760 serve 31684 -- Started Serve in namespace "serve".
INFO 2025-04-09 14:06:57,875 serve 31684 -- Application 'dlinear-ett-server' is ready at http://127.0.0.1:8000/.
Test the service#
Test the deployed DLinear model with both single requests and concurrent batch requests to demonstrate the dynamic batching capabilities:
async def test_serve():
# --- Example Client Code, which can be run in a separate script or after serve starts ---
# Base URL for the service.
base_url = "http://127.0.0.1:8000/predict_dlinear"
seq_len_url = f"{base_url}/seq_len"
predict_url = f"{base_url}/predict"
# Get the proper seq_len for the deployed model.
response = requests.get(seq_len_url)
response.raise_for_status()
seq_len_data = response.json()
seq_len = seq_len_data.get("seq_len")
# Load sample data for demonstration purposes.
df = pd.read_csv("s3://air-example-data/electricity-transformer/ETTh2.csv")
ot_series = df["OT"].tolist()
# Create a single sample request from the loaded data.
sample_input_series = ot_series[:seq_len]
sample_request_body = sample_input_series
print("\n--- Sending Single Synchronous Request to /predict endpoint ---")
response = requests.post(predict_url, json=sample_request_body)
response.raise_for_status()
prediction = response.json()
print(f"Prediction (first 5 values): {prediction[:5]}")
print("\n--- Sending Batch Asynchronous Requests to /predict endpoint ---")
sample_input_list = [sample_input_series] * 100 # Use identical requests
async def fetch(session, url, data):
async with session.post(url, json=data) as response:
response.raise_for_status()
return await response.json()
async def fetch_all_concurrently(requests_to_send: list):
async with aiohttp.ClientSession() as session:
tasks = [fetch(session, predict_url, input_data) for input_data in requests_to_send]
responses = await asyncio.gather(*tasks, return_exceptions=True)
return responses
predictions = await fetch_all_concurrently(sample_input_list)
print(f"Finished predictions for {len(sample_input_list)} inputs")
# Running this code in a notebook creates an asyncio event loop in the global scope.
# So, use await directly.
await test_serve()
# Use `asyncio.run(test_serve())` instead if running the code in a script.
Ray Serve’s dynamic batching automatically chunks incoming requests to maximize throughput and hardware utilization while maintaining low latency.
The Ray dashboard automatically captures observability for Ray Serve applications in the Serve view. You can view the service deployments and their replicas and time-series metrics about the service’s health.

Production deployment considerations#
Anyscale Services offers a fault tolerant, scalable, and optimized way to serve Ray Serve applications. See the API ref for more details. You can:
rollout and update services with canary deployment and zero-downtime upgrades.
monitor services through a dedicated service page, unified log viewer, tracing, set up alerts, etc.
scale a service with
num_replicas=autoand utilize replica compaction to consolidate nodes that are fractionally utilized.have head node fault tolerance. OSS Ray recovers from failed workers and replicas but not head node crashes.
serving multiple applications in a single service.

RayTurbo Serve on Anyscale has more capabilities on top of Ray Serve:
fast autoscaling and model loading to get services up and running even faster with 5x improvements even for LLMs
54% higher QPS and up-to 3x streaming tokens per second for high traffic serving use-cases with no proxy bottlenecks
replica compaction into fewer nodes where possible to reduce resource fragmentation and improve hardware utilization
zero-downtime incremental rollouts so the service is never interrupted
different environments for each service in a multi-serve application
multi availability-zone aware scheduling of Ray Serve replicas to provide higher redundancy to availability zone failures
Deploying to production#
For production deployment on Anyscale, you can use the following command:
# Production online service.
anyscale service deploy e2e_timeseries.serve:dlinear_model --name=dlinear-ett-forecaster \
--containerfile="${WORKING_DIR}/containerfile" \
--working-dir="${WORKING_DIR}" \
--exclude=""
Note:
This example uses a
containerfileto define dependencies, but you could easily use a pre-built image as well.You can specify the compute as a compute config or inline in a Service config file.
When you don’t specify compute and you launch from a workspace, the default is the compute configuration of the workspace.
After the service is running remotely, you need to use the bearer token to query it. You can modify the requests code to use this token:
# Service specific config. Replace with your own values from the deployment logs.
base_url = "https://dlinear-ett-forecaster-jgz99.cld-kvedzwag2qa8i5bj.s.anyscaleuserdata.com"
token = "tXhmYYY7qMbrb1ToO9_J3n5_kD7ym7Nirs8djtip7P0"
# Requests config.
path = "/predict_dlinear/predict"
full_url = f"{base_url}{path}"
headers = {"Authorization": f"Bearer {token}"}
prediction = requests.post(full_url, json=sample_input_series, headers=headers).json()
Don’t forget to stop the service once it’s no longer needed:
anyscale service terminate --name dlinear-ett-forecaster
While Anyscale Jobs and Services are useful atomic concepts that help you productionize workloads, they’re also convenient for nodes in a larger ML DAG or CI/CD workflow. You can chain Jobs together, store results, and then serve the application with those artifacts. From there, you can trigger updates to the service and retrigger the Jobs based on events, time, etc. While you can use the Anyscale CLI to integrate with any orchestration platform, Anyscale does support some purpose-built integrations like Airflow and Prefect.
