Multi-modal AI pipeline#

💻 Run this entire tutorial on Anyscale for free: https://console.anyscale.com/template-preview/image-search-and-classification or access the repository here.
This tutorial focuses on the fundamental challenges of multimodal AI workloads at scale:
🔋 Compute: managing heterogeneous clusters, reducing idle time, and handling complex dependencies
📈 Scale: integrating with the Python ecosystem, improving observability, and enabling effective debugging
🛡️ Reliability: ensuring fault tolerance, leveraging checkpointing, and supporting job resumability
🚀 Production: bridging dev-to-prod gaps, enabling fast iteration, maintaining zero downtime, and meeting SLAs
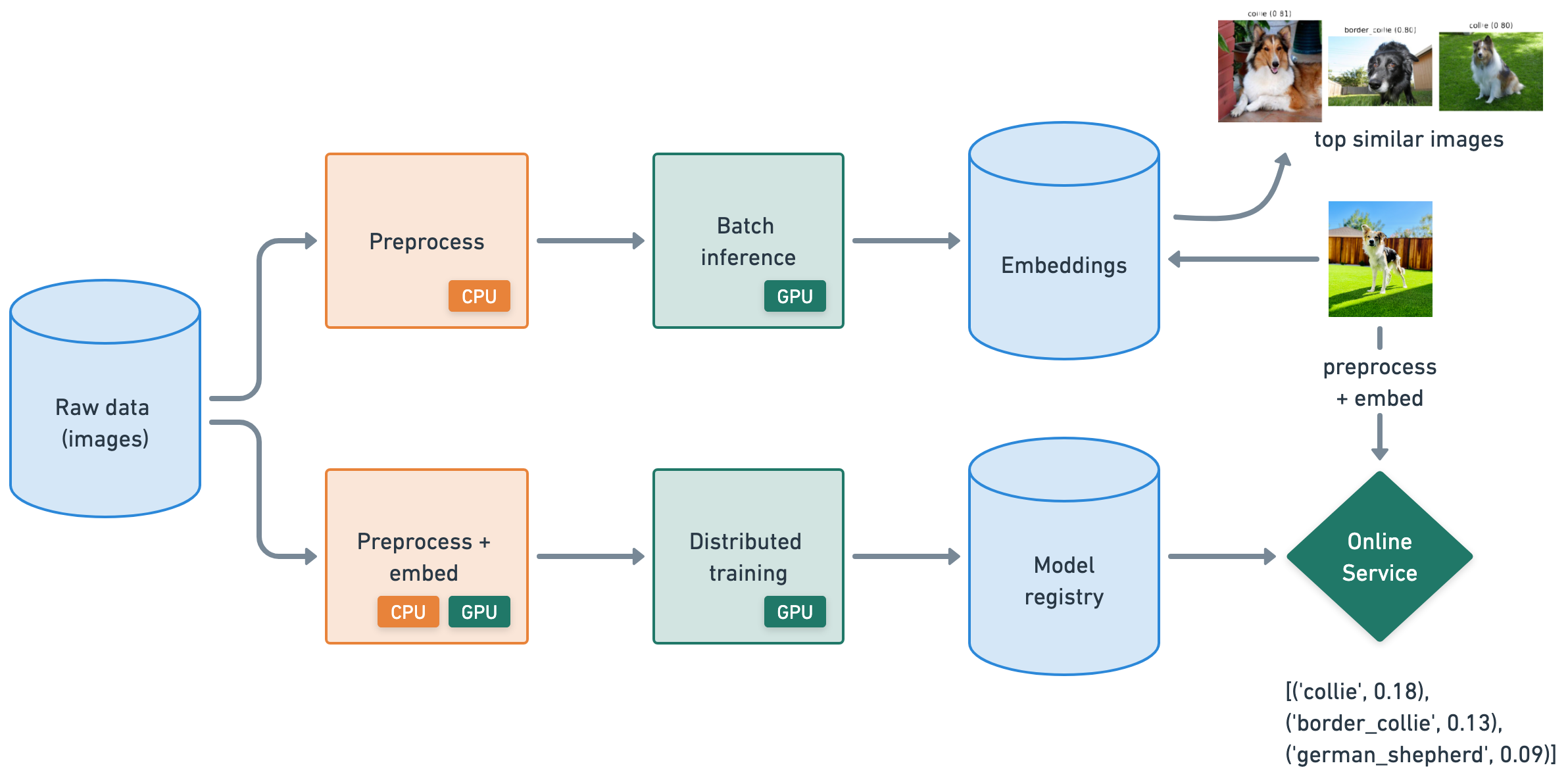
This tutorial covers how Ray addresses each of these challenges and shows the solutions hands-on by implementing scalable batch inference, distributed training, and online serving workloads.
01-Batch-Inference.ipynb: ingest and preprocess data at scale using Ray Data to generate embeddings for an image dataset of different dog breeds and store them.02-Distributed-Training.ipynb: preprocess data to train an image classifier using Ray Train and save model artifacts to a model registry (MLOps).03-Online-Serving.ipynb: deploy an online service using Ray Serve, that uses the trained model to generate predictions.Create production batch Jobs for offline workloads like embedding generation, model training, etc., and production online Services that can scale.
Development#
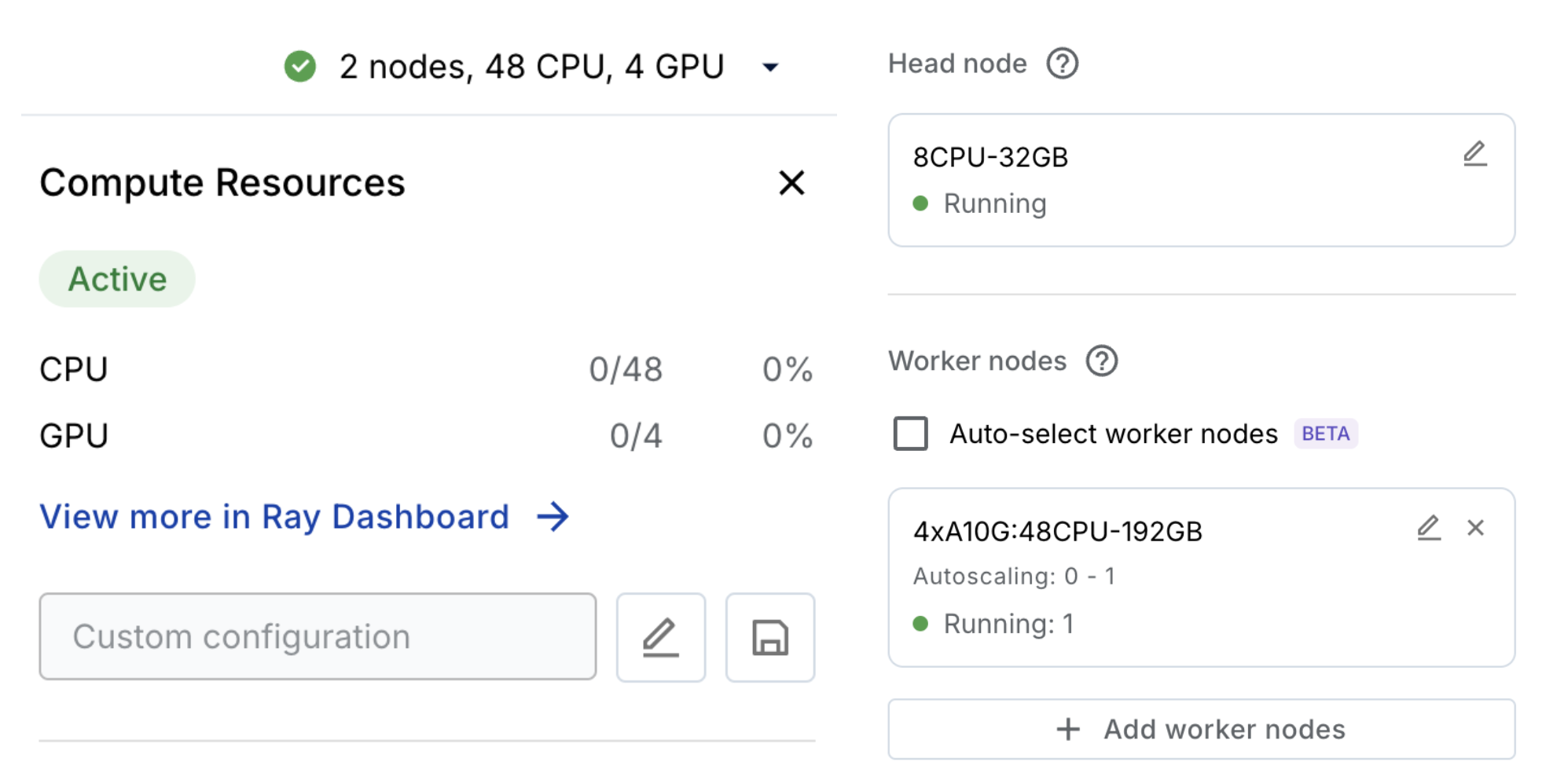
The application is developed on Anyscale Workspaces, which enables development without worrying about infrastructure—just like working on a laptop. Workspaces come with:
Development tools: Spin up a remote session from your local IDE (Cursor, VS Code, etc.) and start coding, using the same tools you love but with the power of Anyscale’s compute.
Dependencies: Install dependencies using familiar tools like pip or uv. Anyscale propagates all dependencies to the cluster’s worker nodes.
Compute: Leverage any reserved instance capacity, spot instance from any compute provider of your choice by deploying Anyscale into your account. Alternatively, you can use the Anyscale cloud for a full serverless experience.
Under the hood, a cluster spins up and is efficiently managed by Anyscale.
Debugging: Leverage a distributed debugger to get the same VS Code-like debugging experience.
Learn more about Anyscale Workspaces in the official documentation.
Additional dependencies#
You can choose to manage the additional dependencies through uv or pip.
uv#
# UV setup instructions
uv init . # this creates pyproject.toml, uv lockfile, etc.
ray_wheel_url=http://localhost:9478/ray/$(pip freeze | grep -oP '^ray @ file:///home/ray/\.whl/\K.*')
uv add "$ray_wheel_url[data, train, tune, serve]" # to use anyscale's performant ray runtime
uv add $(grep -v '^\s*#' requirements.txt)
uv add --editable ./doggos
Pip#
# Pip setup instructions
pip install -q -r /home/ray/default/requirements.txt
pip install -e ./doggos
Note: Run the entire tutorial for free on Anyscale—all dependencies come pre-installed, and compute autoscales automatically. To run it elsewhere, install the dependencies from the containerfile and provision the appropriate GPU resources.
Production#
Seamlessly integrate with your existing CI/CD pipelines by leveraging the Anyscale CLI or SDK to deploy highly available services and run reliable batch jobs. Developing in an environment nearly identical to production—a multi-node cluster—drastically accelerates the dev-to-prod transition. This tutorial also introduces proprietary RayTurbo features that optimize workloads for performance, fault tolerance, scale, and observability.
anyscale job submit -f /home/ray/default/configs/generate_embeddings.yaml
anyscale job submit -f /home/ray/default/configs/train_model.yaml
anyscale service deploy -f /home/ray/default/configs/service.yaml
No infrastructure headaches#
Abstract away infrastructure from your ML/AI developers so they can focus on their core ML development. You can additionally better manage compute resources and costs with enterprise governance and observability and admin capabilities so you can set resource quotas, set priorities for different workloads and gain observability of your utilization across your entire compute fleet. Users running on a Kubernetes cloud (EKS, GKE, etc.) can still access the proprietary RayTurbo optimizations demonstrated in this tutorial by deploying the Anyscale Kubernetes Operator.