Online serving#


This tutorial launches an online service that deploys the trained model to generate predictions and autoscales based on incoming traffic.
%%bash
pip install -q -r /home/ray/default/requirements.txt
pip install -q -e /home/ray/default/doggos
Successfully registered `ipywidgets, matplotlib` and 4 other packages to be installed on all cluster nodes.
View and update dependencies here: https://console.anyscale.com/cld_kvedZWag2qA8i5BjxUevf5i7/prj_cz951f43jjdybtzkx1s5sjgz99/workspaces/expwrk_23ry3pgfn3jgq2jk3e5z25udhz?workspace-tab=dependencies
Successfully registered `doggos` package to be installed on all cluster nodes.
View and update dependencies here: https://console.anyscale.com/cld_kvedZWag2qA8i5BjxUevf5i7/prj_cz951f43jjdybtzkx1s5sjgz99/workspaces/expwrk_23ry3pgfn3jgq2jk3e5z25udhz?workspace-tab=dependencies
Note: A kernel restart may be required for all dependencies to become available.
If using uv, then:
Turn off the runtime dependencies (
Dependenciestab up top > Toggle offPip packages). And no need to run thepip installcommands above.Change the python kernel of this notebook to use the
venv(Click onbase (Python x.yy.zz)on top right cordern of notebook >Select another Kernel>Python Environments...>Create Python Environment>Venv>Use Existing) and done! Now all the notebook’s cells will use the virtual env.Change the py executable to use
uv runinstead ofpythonby adding this line after importing ray.
import os
os.environ.pop("RAY_RUNTIME_ENV_HOOK", None)
import ray
ray.init(runtime_env={"py_executable": "uv run", "working_dir": "/home/ray/default"})
%load_ext autoreload
%autoreload all
import os
import ray
import sys
sys.path.append(os.path.abspath("../doggos/"))
# If using UV
# os.environ.pop("RAY_RUNTIME_ENV_HOOK", None)
# ray.init(runtime_env={"py_executable": "uv run", "working_dir": "/home/ray/default"})
import os
from fastapi import FastAPI
import mlflow
import requests
from starlette.requests import Request
from urllib.parse import urlparse
from ray import serve
import numpy as np
from PIL import Image
import torch
from transformers import CLIPModel, CLIPProcessor
from doggos.infer import TorchPredictor
from doggos.model import collate_fn
from doggos.utils import url_to_array
Deployments#
First create a deployment for the trained model that generates a probability distribution for a given image URL. You can specify the compute you want to use with ray_actor_options, and how you want to horizontally scale, with num_replicas, this specific deployment.
@serve.deployment(
num_replicas="1",
ray_actor_options={
"num_gpus": 1,
"accelerator_type": "T4",
},
)
class ClassPredictor:
def __init__(self, model_id, artifacts_dir, device="cuda"):
"""Initialize the model."""
# Embdding model
self.processor = CLIPProcessor.from_pretrained(model_id)
self.model = CLIPModel.from_pretrained(model_id)
self.model.to(device=device)
self.device = device
# Trained classifier
self.predictor = TorchPredictor.from_artifacts_dir(artifacts_dir=artifacts_dir)
self.preprocessor = self.predictor.preprocessor
def get_probabilities(self, url):
image = Image.fromarray(np.uint8(url_to_array(url=url))).convert("RGB")
inputs = self.processor(images=[image], return_tensors="pt", padding=True).to(self.device)
with torch.inference_mode():
embedding = self.model.get_image_features(**inputs).cpu().numpy()
outputs = self.predictor.predict_probabilities(
collate_fn({"embedding": embedding}))
return {"probabilities": outputs["probabilities"][0]}
Ray Serve makes it easy to do model composition where you can compose multiple deployments containing ML models or business logic into a single application. You can independently scale even fractional resources, and configure each of your deployments.
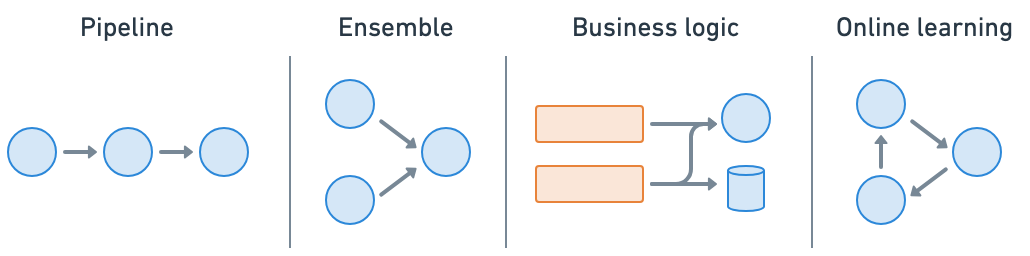
Application#
# Define app.
api = FastAPI(
title="doggos",
description="classify your dog",
version="0.1",
)
@serve.deployment
@serve.ingress(api)
class Doggos:
def __init__(self, classifier):
self.classifier = classifier
@api.post("/predict/")
async def predict(self, request: Request):
data = await request.json()
probabilities = await self.classifier.get_probabilities.remote(url=data["url"])
return probabilities
# Model registry.
model_registry = "/mnt/cluster_storage/mlflow/doggos"
experiment_name = "doggos"
mlflow.set_tracking_uri(f"file:{model_registry}")
# Get best_run's artifact_dir.
sorted_runs = mlflow.search_runs(
experiment_names=[experiment_name],
order_by=["metrics.val_loss ASC"])
best_run = sorted_runs.iloc[0]
artifacts_dir = urlparse(best_run.artifact_uri).path
# Define app.
app = Doggos.bind(
classifier=ClassPredictor.bind(
model_id="openai/clip-vit-base-patch32",
artifacts_dir=artifacts_dir,
device="cuda"
)
)
# Run service locally.
serve.run(app, route_prefix="/")
2025-08-28 05:15:38,455 INFO worker.py:1771 -- Connecting to existing Ray cluster at address: 10.0.17.148:6379...
2025-08-28 05:15:38,465 INFO worker.py:1942 -- Connected to Ray cluster. View the dashboard at https://session-jhxhj69d6ttkjctcxfnsfe7gwk.i.anyscaleuserdata.com
2025-08-28 05:15:38,471 INFO packaging.py:588 -- Creating a file package for local module '/home/ray/default/doggos/doggos'.
2025-08-28 05:15:38,475 INFO packaging.py:380 -- Pushing file package 'gcs://_ray_pkg_62e649352ce105b6.zip' (0.04MiB) to Ray cluster...
2025-08-28 05:15:38,476 INFO packaging.py:393 -- Successfully pushed file package 'gcs://_ray_pkg_62e649352ce105b6.zip'.
2025-08-28 05:15:38,478 INFO packaging.py:380 -- Pushing file package 'gcs://_ray_pkg_c3f5a1927d401ecc93333d17727d37c3401aeed9.zip' (1.08MiB) to Ray cluster...
2025-08-28 05:15:38,484 INFO packaging.py:393 -- Successfully pushed file package 'gcs://_ray_pkg_c3f5a1927d401ecc93333d17727d37c3401aeed9.zip'.
(autoscaler +9s) Tip: use `ray status` to view detailed cluster status. To disable these messages, set RAY_SCHEDULER_EVENTS=0.
(ProxyActor pid=42150) INFO 2025-08-28 05:15:42,208 proxy 10.0.17.148 -- Proxy starting on node 524d54fa7a3dfe7fcd55149e6efeaa7a697a4ce87282da72073206b6 (HTTP port: 8000).
INFO 2025-08-28 05:15:42,290 serve 41929 -- Started Serve in namespace "serve".
(ProxyActor pid=42150) INFO 2025-08-28 05:15:42,286 proxy 10.0.17.148 -- Got updated endpoints: {}.
(ServeController pid=42086) INFO 2025-08-28 05:15:47,403 controller 42086 -- Deploying new version of Deployment(name='ClassPredictor', app='default') (initial target replicas: 1).
(ServeController pid=42086) INFO 2025-08-28 05:15:47,404 controller 42086 -- Deploying new version of Deployment(name='Doggos', app='default') (initial target replicas: 1).
(ProxyActor pid=42150) INFO 2025-08-28 05:15:47,423 proxy 10.0.17.148 -- Got updated endpoints: {Deployment(name='Doggos', app='default'): EndpointInfo(route='/', app_is_cross_language=False)}.
(ProxyActor pid=42150) WARNING 2025-08-28 05:15:47,430 proxy 10.0.17.148 -- ANYSCALE_RAY_SERVE_GRPC_RUN_PROXY_ROUTER_SEPARATE_LOOP has been deprecated and will be removed in the ray v2.50.0. Please use RAY_SERVE_RUN_ROUTER_IN_SEPARATE_LOOP instead.
(ProxyActor pid=42150) INFO 2025-08-28 05:15:47,434 proxy 10.0.17.148 -- Started <ray.serve._private.router.SharedRouterLongPollClient object at 0x79fb040771d0>.
(ServeController pid=42086) INFO 2025-08-28 05:15:47,524 controller 42086 -- Adding 1 replica to Deployment(name='ClassPredictor', app='default').
(ServeController pid=42086) INFO 2025-08-28 05:15:47,525 controller 42086 -- Adding 1 replica to Deployment(name='Doggos', app='default').
(ServeReplica:default:ClassPredictor pid=20055, ip=10.0.5.20) Using a slow image processor as `use_fast` is unset and a slow processor was saved with this model. `use_fast=True` will be the default behavior in v4.52, even if the model was saved with a slow processor. This will result in minor differences in outputs. You'll still be able to use a slow processor with `use_fast=False`.
(ProxyActor pid=20172, ip=10.0.5.20) INFO 2025-08-28 05:15:56,055 proxy 10.0.5.20 -- Proxy starting on node b84e244dca75c40ea981202cae7a1a06df9598ac29ad2b18e1bedb99 (HTTP port: 8000).
(ProxyActor pid=20172, ip=10.0.5.20) INFO 2025-08-28 05:15:56,131 proxy 10.0.5.20 -- Got updated endpoints: {Deployment(name='Doggos', app='default'): EndpointInfo(route='/', app_is_cross_language=False)}.
(ProxyActor pid=20172, ip=10.0.5.20) WARNING 2025-08-28 05:15:56,137 proxy 10.0.5.20 -- ANYSCALE_RAY_SERVE_GRPC_RUN_PROXY_ROUTER_SEPARATE_LOOP has been deprecated and will be removed in the ray v2.50.0. Please use RAY_SERVE_RUN_ROUTER_IN_SEPARATE_LOOP instead.
(ProxyActor pid=20172, ip=10.0.5.20) INFO 2025-08-28 05:15:56,141 proxy 10.0.5.20 -- Started <ray.serve._private.router.SharedRouterLongPollClient object at 0x76c838542d80>.
INFO 2025-08-28 05:15:57,505 serve 41929 -- Application 'default' is ready at http://127.0.0.1:8000/.
INFO 2025-08-28 05:15:57,511 serve 41929 -- Started <ray.serve._private.router.SharedRouterLongPollClient object at 0x7955d893cd70>.
DeploymentHandle(deployment='Doggos')
# Send a request.
url = "https://doggos-dataset.s3.us-west-2.amazonaws.com/samara.png"
data = {"url": url}
response = requests.post("http://127.0.0.1:8000/predict/", json=data)
probabilities = response.json()["probabilities"]
sorted_probabilities = sorted(probabilities.items(), key=lambda x: x[1], reverse=True)
sorted_probabilities[0:3]
(ServeReplica:default:Doggos pid=42244) INFO 2025-08-28 05:15:57,646 default_Doggos fs1weamq 31c15b70-89a9-4b2d-b4ab-f8424fe6d8d2 -- Started <ray.serve._private.router.SharedRouterLongPollClient object at 0x7ba028149fd0>.
(ServeReplica:default:ClassPredictor pid=20055, ip=10.0.5.20) /home/ray/anaconda3/lib/python3.12/site-packages/ray/serve/_private/replica.py:1397: UserWarning: Calling sync method 'get_probabilities' directly on the asyncio loop. In a future version, sync methods will be run in a threadpool by default. Ensure your sync methods are thread safe or keep the existing behavior by making them `async def`. Opt into the new behavior by setting RAY_SERVE_RUN_SYNC_IN_THREADPOOL=1.
(ServeReplica:default:ClassPredictor pid=20055, ip=10.0.5.20) warnings.warn(
[('border_collie', 0.1990548074245453),
('collie', 0.1363961398601532),
('german_shepherd', 0.07545585185289383)]
(ServeReplica:default:Doggos pid=42244) INFO 2025-08-28 05:15:58,150 default_Doggos fs1weamq 31c15b70-89a9-4b2d-b4ab-f8424fe6d8d2 -- POST /predict/ 200 516.2ms
(ServeReplica:default:ClassPredictor pid=20055, ip=10.0.5.20) INFO 2025-08-28 05:15:58,148 default_ClassPredictor y7tebd3e 31c15b70-89a9-4b2d-b4ab-f8424fe6d8d2 -- CALL /predict/ OK 491.4ms
Ray Serve#
Ray Serve is a highly scalable and flexible model serving library for building online inference APIs that allows you to:
Wrap models and business logic as separate serve deployments and connect them together (pipeline, ensemble, etc.)
Avoid one large service that’s network and compute bounded and an inefficient use of resources.
Utilize fractional heterogeneous resources, which isn’t possible with SageMaker, Vertex, KServe, etc., and horizontally scale with
num_replicas.autoscale up and down based on traffic.
Integrate with FastAPI and HTTP.
Set up a gRPC service to build distributed systems and microservices.
Enable dynamic batching based on batch size, time, etc.
Access a suite of utilities for serving LLMs that are inference-engine agnostic and have batteries-included support for LLM-specific features such as multi-LoRA support
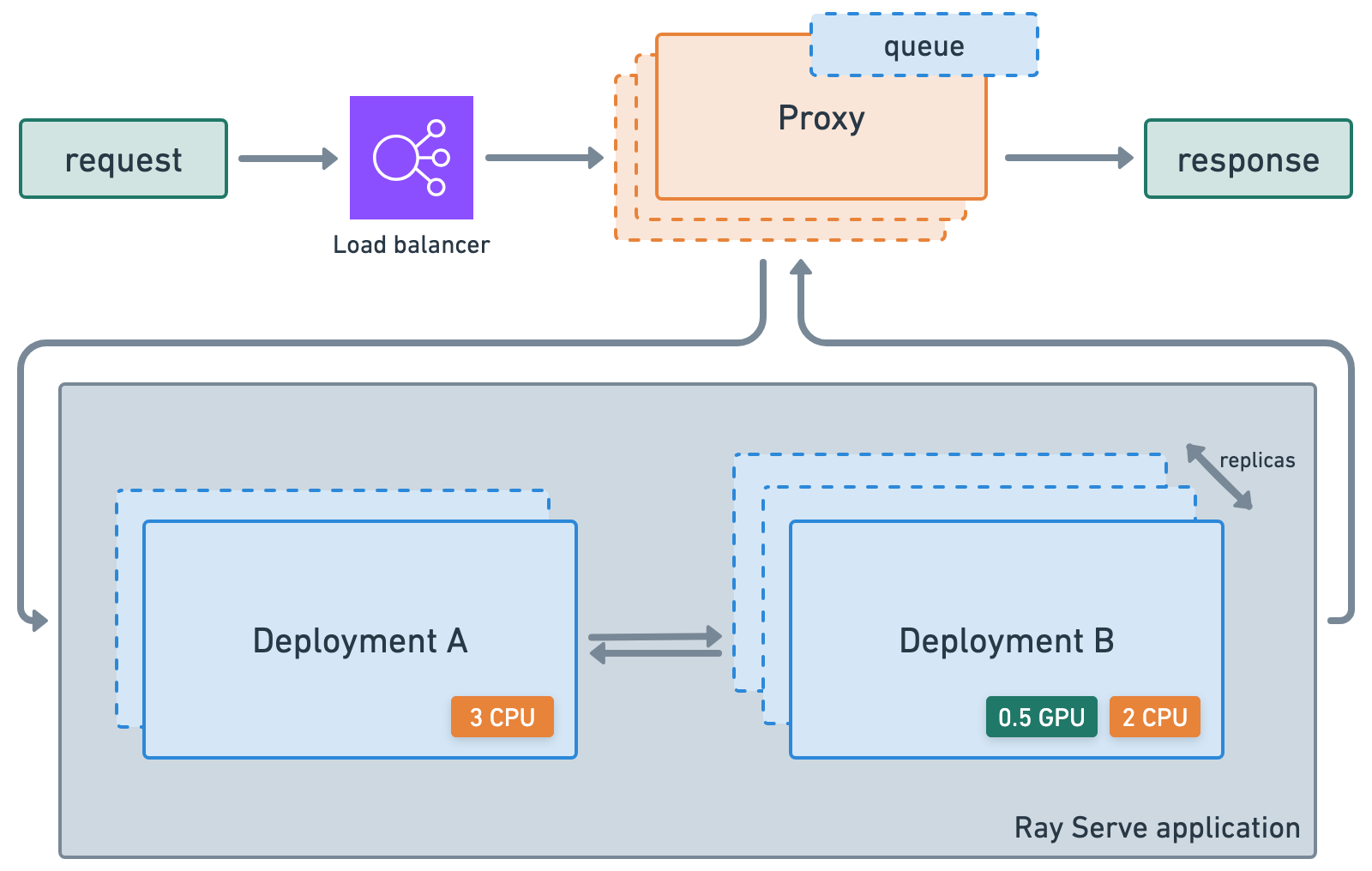
🔥 RayTurbo Serve on Anyscale has more functionality on top of Ray Serve:
fast autoscaling and model loading to get services up and running even faster with 5x improvements even for LLMs.
54% higher QPS and up-to 3x streaming tokens per second for high traffic serving use-cases with no proxy bottlenecks.
replica compaction into fewer nodes where possible to reduce resource fragmentation and improve hardware utilization.
zero-downtime incremental rollouts so your service is never interrupted.
different environments for each service in a multi-serve application.
multi availability-zone aware scheduling of Ray Serve replicas to provide higher redundancy to availability zone failures.
Observability#
The Ray dashboard and specifically the Serve view automatically captures observability for Ray Serve applications. You can view the service deployments and their replicas and time-series metrics to see the service’s health.
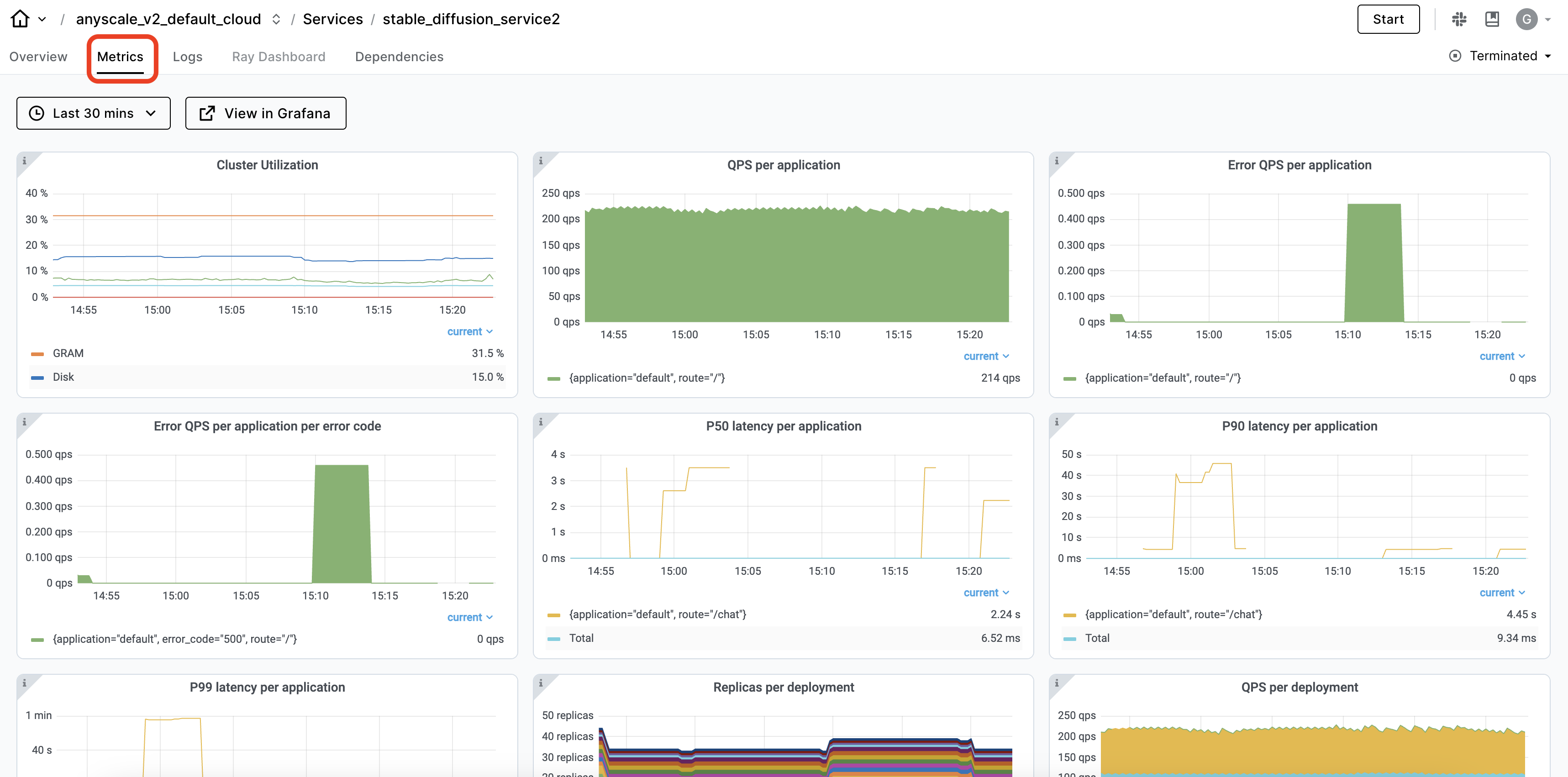
Production services#
Anyscale Services (API ref) offers a fault tolerant, scalable, and optimized way to serve Ray Serve applications. You can:
rollout and update services with canary deployment and zero-downtime upgrades.
monitor services through a dedicated service page, unified log viewer, tracing, set up alerts, etc.
scale a service, with
num_replicas=auto, and utilize replica compaction to consolidate nodes that are fractionally utilized.get head node fault tolerance. OSS Ray recovers from failed workers and replicas but not head node crashes.
serve multiple applications in a single service.
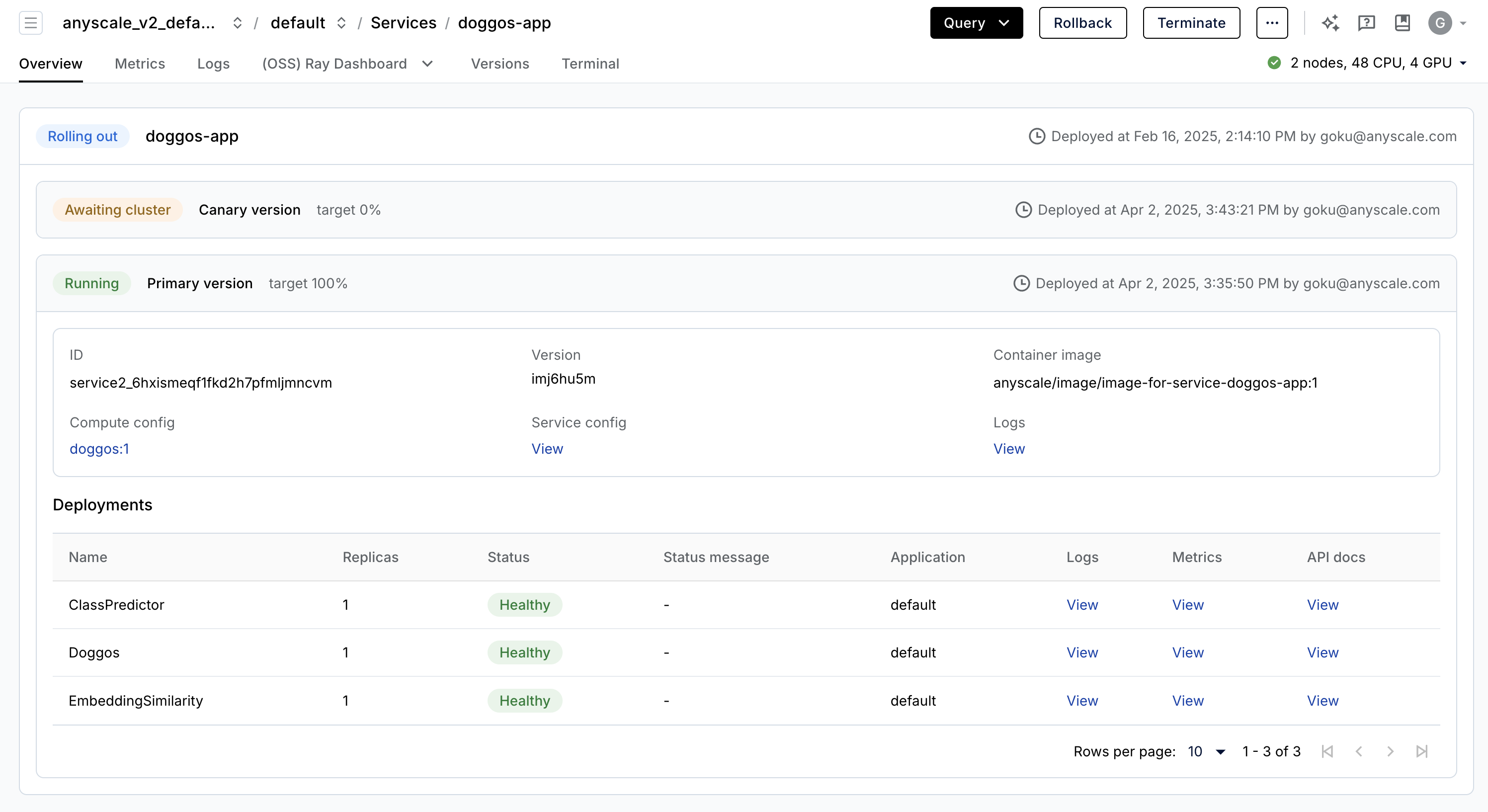
Note:
This tutorial uses a
containerfileto define dependencies, but you could easily use a pre-built image as well.You can specify the compute as a compute config or inline in a Service config file.
When you don’t specify compute while launching from a workspace, this configuration defaults to the compute configuration of the workspace.
# Production online service.
anyscale service deploy -f /home/ray/default/configs/service.yaml
(anyscale +1.9s) Restarting existing service 'doggos-app'.
(anyscale +3.2s) Uploading local dir '/home/ray/default' to cloud storage.
(anyscale +5.2s) Including workspace-managed pip dependencies.
(anyscale +5.8s) Service 'doggos-app' deployed (version ID: akz9ul28).
(anyscale +5.8s) View the service in the UI: 'https://console.anyscale.com/services/service2_6hxismeqf1fkd2h7pfmljmncvm'
(anyscale +5.8s) Query the service once it's running using the following curl command (add the path you want to query):
(anyscale +5.8s) curl -H "Authorization: Bearer <BEARER_TOKEN>" https://doggos-app-bxauk.cld-kvedzwag2qa8i5bj.s.anyscaleuserdata.com/
curl -X POST "https://doggos-app-bxauk.cld-kvedzwag2qa8i5bj.s.anyscaleuserdata.com/predict/" \
-H "Authorization: Bearer <BEARER_TOKEN>" \
-H "Content-Type: application/json" \
-d '{"url": "https://doggos-dataset.s3.us-west-2.amazonaws.com/samara.png", "k": 4}'
# Terminate service.
anyscale service terminate --name doggos-app
(anyscale +1.5s) Service service2_6hxismeqf1fkd2h7pfmljmncvm terminate initiated.
(anyscale +1.5s) View the service in the UI at https://console.anyscale.com/services/service2_6hxismeqf1fkd2h7pfmljmncvm
CI/CD#
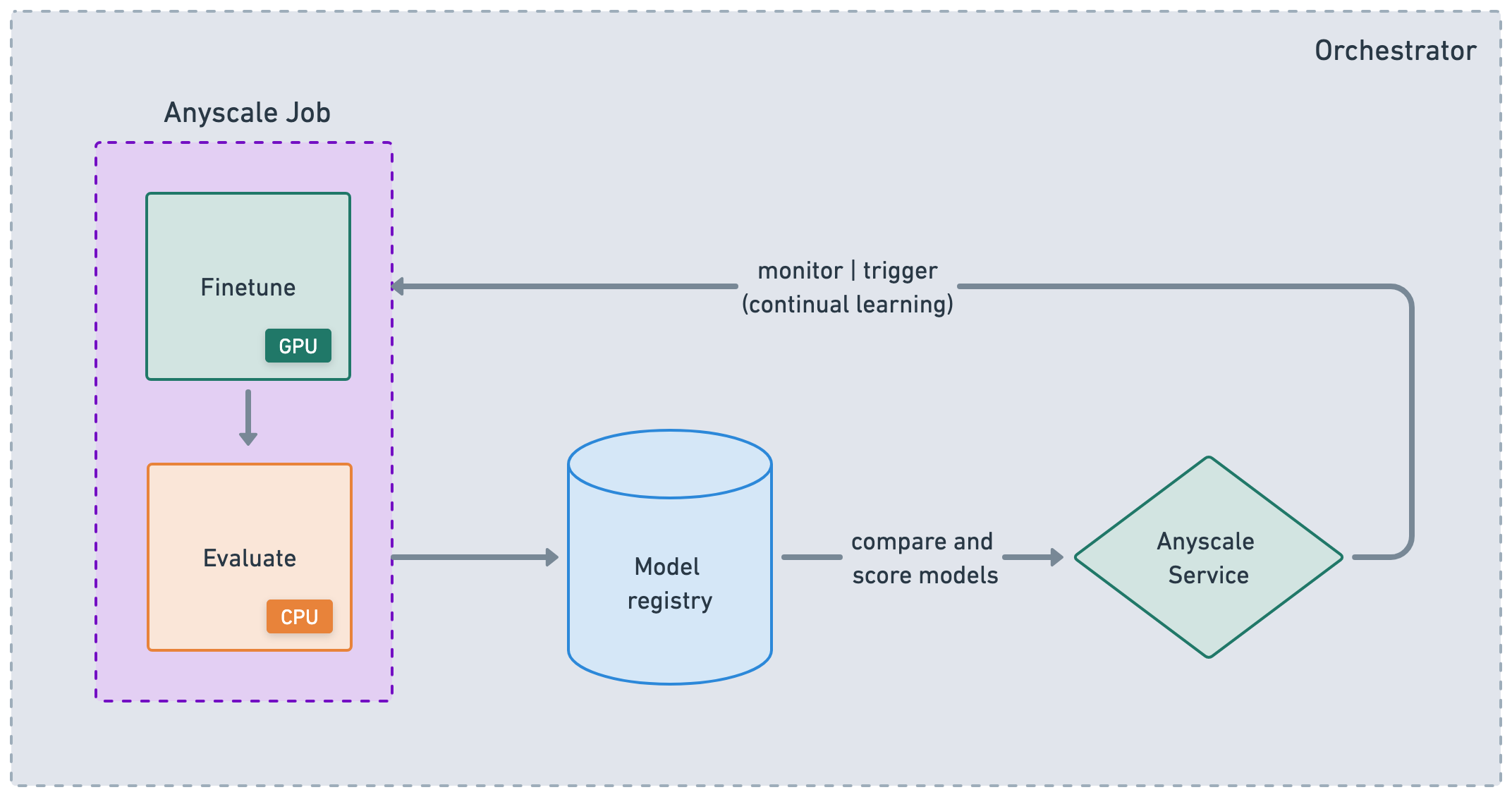
While Anyscale Jobs and Services are useful atomic concepts that help you productionize workloads, they’re also useful for nodes in a larger ML DAG or CI/CD workflow. You can chain Jobs together, store results and then serve your application with those artifacts. From there, you can trigger updates to your service and retrigger the Jobs based on events, time, etc. While you can simply use the Anyscale CLI to integrate with any orchestration platform, Anyscale does support some purpose-built integrations like Airflow and Prefect.
🚨 Note: Reset this notebook using the “🔄 Restart” button location at the notebook’s menu bar. This way we can free up all the variables, utils, etc. used in this notebook.