Ray on Kubernetes#
Overview#
In this section we cover how to execute your distributed Ray programs on a Kubernetes cluster.
Using the KubeRay operator is the recommended way to do so. The operator provides a Kubernetes-native way to manage Ray clusters. Each Ray cluster consists of a head node pod and a collection of worker node pods. Optional autoscaling support allows the KubeRay operator to size your Ray clusters according to the requirements of your Ray workload, adding and removing Ray pods as needed. KubeRay supports heterogenous compute nodes (including GPUs) as well as running multiple Ray clusters with different Ray versions in the same Kubernetes cluster.
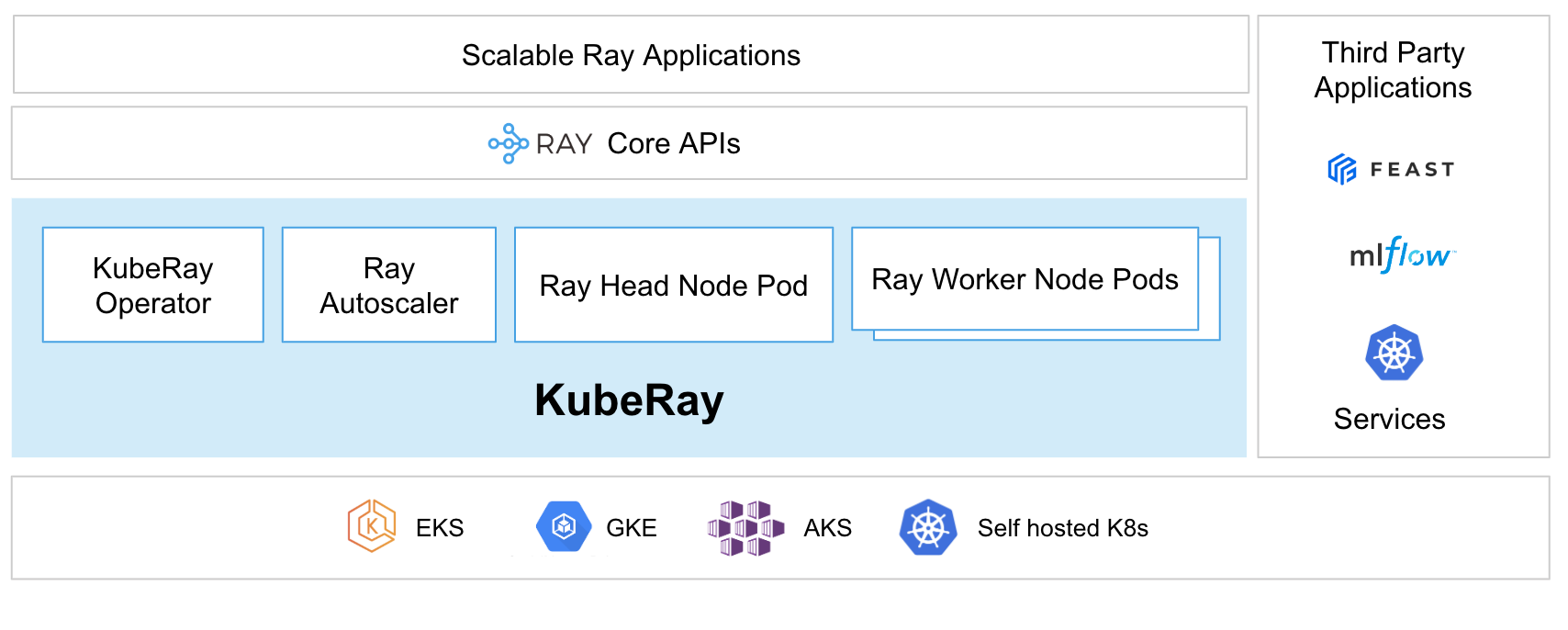
KubeRay introduces three distinct Kubernetes Custom Resource Definitions (CRDs): RayCluster, RayJob, and RayService. These CRDs assist users in efficiently managing Ray clusters tailored to various use cases.
See Getting Started to learn the basics of KubeRay and follow the quickstart guides to run your first Ray application on Kubernetes with KubeRay.
Additionally, Anyscale is the managed Ray platform developed by the creators of Ray. It offers an easy path to deploy Ray clusters on your existing Kubernetes infrastructure, including EKS, GKE, AKS, or self-hosted Kubernetes.
Learn More#
The Ray docs present all the information you need to start running Ray workloads on Kubernetes.
Getting Started
Learn how to start a Ray cluster and deploy Ray applications on Kubernetes.
User Guides
Learn best practices for configuring Ray clusters on Kubernetes.
Examples
Try example Ray workloads on Kubernetes.
Ecosystem
Integrate KubeRay with third party Kubernetes ecosystem tools.
Benchmarks
Check the KubeRay benchmark results.
Troubleshooting
Consult the KubeRay troubleshooting guides.
About KubeRay#
Ray’s Kubernetes support is developed at the KubeRay GitHub repository, under the broader Ray project. KubeRay is used by several companies to run production Ray deployments.
Visit the KubeRay GitHub repo to track progress, report bugs, propose new features, or contribute to the project.