Out-Of-Memory Prevention#
If application tasks or actors consume a large amount of heap space, it can cause the node to run out of memory (OOM). When that happens, the operating system will start killing worker or raylet processes, disrupting the application. OOM may also stall metrics and if this happens on the head node, it may stall the dashboard or other control processes and cause the cluster to become unusable.
In this section we will go over:
What is the memory monitor and how it works
How to enable and configure it
Also view Debugging Out of Memory to learn how to troubleshoot out-of-memory issues.
What is the memory monitor?#
The memory monitor is a component that runs within the raylet process on each node. It monitors the memory usage, which includes the worker heap, the object store, and the raylet as described in memory management. If the combined usage exceeds a configurable threshold the raylet will kill a task or actor process to free up memory and prevent Ray from failing.
It’s available on Linux and is tested with Ray running inside a container that is using cgroup v1/v2. If you encounter issues when running the memory monitor outside of a container, file an issue or post a question.
What to expect?#
The default memory monitoring system protects the Ray node from node death due to memory contention and OOM. Compared to the Linux OOM killer, it also aims to preserve as much application progress as possible by killing workers based on the time since the task started executing. However, the default memory monitoring system makes no guarantees.
Starting in Ray 2.56, with resource isolation enabled, the memory monitoring system provides the following:
Zero kernel OOM kills (work-preserving) when resource isolation is enabled and system-reserved memory is configured to cover the memory footprint of critical Ray system processes (raylet, gcs, agents) and other system overhead.
Zero Ray OOM kills under the above configuration when tasks and actors specify accurate logical memory requests.
Zero node deaths due to memory contention when resource isolation is enabled and system-reserved memory is configured correctly.
To enable resource isolation, see How to Enable Cgroup v2 for Resource Isolation.
How do I disable the memory monitor?#
The memory monitor is enabled by default and can only be disabled when resource isolation is disabled.
To disable the memory monitor when resource isolation is turned off, set the environment variable RAY_memory_monitor_refresh_ms to zero when Ray starts (e.g., RAY_memory_monitor_refresh_ms=0 ray start ...).
How do I configure the memory monitor?#
Default memory monitor configuration:
The memory monitor is controlled by the following environment variables:
RAY_memory_monitor_refresh_ms (int, defaults to 250)is the interval to check memory usage and kill tasks or actors if needed. Task killing is disabled when this value is 0. The memory monitor selects and kills one task at a time and waits for it to be killed before choosing another one, regardless of how frequent the memory monitor runs.RAY_memory_usage_threshold (float, defaults to 0.95)is the threshold when the node is beyond the memory capacity. If the memory usage is above this fraction it will start killing processes to free up memory. Ranges from [0, 1].
Resource isolation memory monitor configuration:
When resource isolation is enabled, the memory monitor is controlled by the following flag passed to ray start or ray.init:
--system-reserved-memorysets the amount of memory reserved for critical Ray system processes and other system processes outside of Ray’s userspace. By default, this value is 10% of the system’s total memory, bounded by a minimum of 500MB and a maximum of 10GB. The memory monitor enforces that the workload processes’ memory footprint doesn’t exceedtotal_memory - system_reserved_memorybytes.
Using the Memory Monitor#
Retry policy#
When a task or actor is killed by the memory monitor it will be retried with exponential backoff. There is a cap on the retry delay, which is 60 seconds. If tasks are killed by the memory monitor, it retries infinitely (not respecting max_retries) unless max_retries is set to 0. When max_retries is set to 0, the task will not be retried. If actors are killed by the memory monitor, it doesn’t recreate the actor infinitely (It respects max_restarts, which is 0 by default).
Worker killing policy#
Worker killing policy since Ray 2.56#
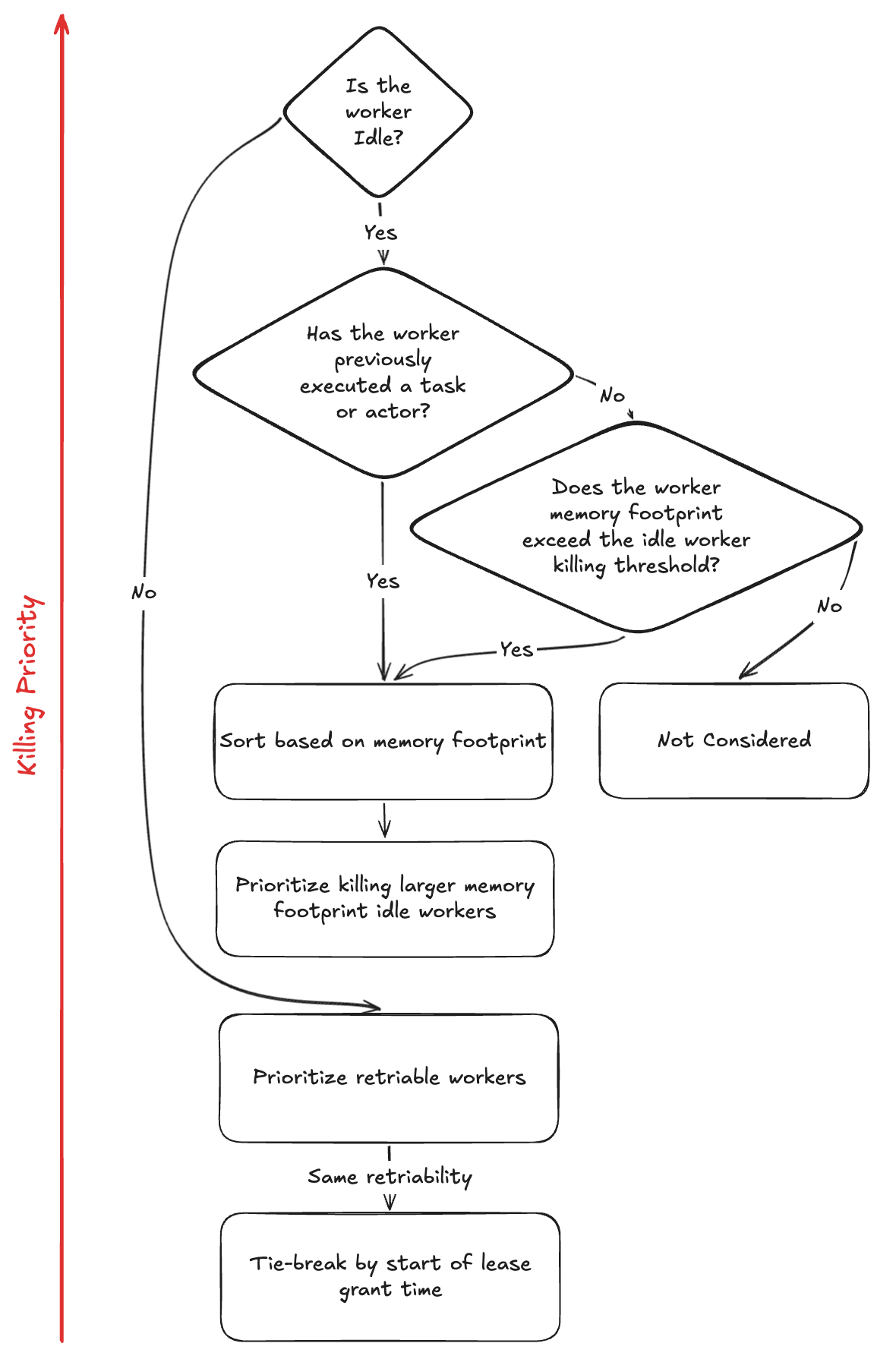
As shown in the diagram above, the worker killing policy prioritizes idle workers over active workers when selecting workers to kill.
Idle worker policy:
The memory monitor always consider all workers that have previously executed tasks or actors for killing regardless of the idle-worker killing memory threshold. Workers that have never executed any tasks or actors (cold-start idle workers) are only considered for killing if their memory footprint exceeds the idle-worker killing memory threshold. Cold-start idle workers should have a small memory footprint. In the unlikely case that the OOM logs show active workers being selected over idle workers while a large idle-worker memory footprint remains, the dependencies inherited when starting a new process in Ray’s userspace are likely too expensive. In that case, consider reducing the memory footprint of new processes in Ray’s userspace, or lowering the idle-worker killing memory threshold via the environment variable
RAY_idle_worker_killing_memory_threshold_bytes(default is 1GiB).Among the workers eligible for killing, the policy selects the worker with the largest memory footprint first.
Active worker policy:
For workers running tasks or actors (active workers), the policy prioritizes retriable tasks first to maximize retry opportunities.
Among the active workers with the same retriability, the policy selects the most recent workers next (newest granted lease time).
The policy continues to select workers until current_memory_usage - total_selected_workers_memory_footprint + kill_buffer <= available_memory_for_workload_processes.
Where current_memory_usage is the current memory usage on the node,
total_selected_workers_memory_footprint is the sum of the memory footprint of all selected workers to kill,
kill_buffer is the amount of memory to leave as breathing room between the memory usage and the memory allocated to the workload processes.
available_memory_for_workload_processes is the amount of memory available for the workload processes to use.
This is computed as total_system_memory - system_reserved_memory as mentioned above.
The kill_buffer defaults to 5% of the total system memory and caps at 3GiB (configurable via RAY_max_kill_memory_buffer_bytes).
To revert to the legacy worker killing policy, set the environment variable RAY_worker_killing_policy_by_group to true before starting Ray.
Legacy worker killing policy#
The memory monitor avoids infinite loops of task retries by ensuring at least one task is able to run for each caller on each node. If it is unable to ensure this, the workload will fail with an OOM error. Note that this is only an issue for tasks, since the memory monitor will not indefinitely retry actors. If the workload fails, refer to how to address memory issues on how to adjust the workload to make it pass. For code example, see the last task example below.
When a worker needs to be killed, the policy first prioritizes tasks that are retriable, i.e. when max_retries or max_restarts is > 0. This is done to minimize workload failure. Actors by default are not retriable since max_restarts defaults to 0. Therefore, by default, tasks are preferred to actors when it comes to what gets killed first.
When there are multiple callers that has created tasks, the policy will pick a task from the caller with the most number of running tasks. If two callers have the same number of tasks it picks the caller whose earliest task has a later start time. This is done to ensure fairness and allow each caller to make progress.
Amongst the tasks that share the same caller, the latest started task will be killed first.
Below is an example to demonstrate the policy. In the example we have a script that creates two tasks, which in turn creates four more tasks each. The tasks are colored such that each color forms a “group” of tasks where they belong to the same caller.

If, at this point, the node runs out of memory, it will pick a task from the caller with the most number of tasks, and kill its task whose started the last:

If, at this point, the node still runs out of memory, the process will repeat:

Example: Workloads fails if the last task of the caller is killed
Let’s create an application oom.py that runs a single task that requires more memory than what is available. It is set to infinite retry by setting max_retries to -1.
The worker killer policy sees that it is the last task of the caller, and will fail the workload when it kills the task as it is the last one for the caller, even when the task is set to retry forever.
import ray
@ray.remote(max_retries=0)
def leaks_memory():
chunks = []
bits_to_allocate = 8 * 100 * 1024 * 1024 # ~100 MiB
while True:
chunks.append([0] * bits_to_allocate)
try:
ray.get(leaks_memory.remote())
except ray.exceptions.OutOfMemoryError as ex:
print("task failed with OutOfMemoryError, which is expected")
Set RAY_event_stats_print_interval_ms=1000 so it prints the worker kill summary every second, since by default it prints every minute.
RAY_event_stats_print_interval_ms=1000 python oom.py
(raylet) node_manager.cc:3040: 1 Workers (tasks / actors) killed due to memory pressure (OOM), 0 Workers crashed due to other reasons at node (ID: 2c82620270df6b9dd7ae2791ef51ee4b5a9d5df9f795986c10dd219c, IP: 172.31.183.172) over the last time period. To see more information about the Workers killed on this node, use `ray logs raylet.out -ip 172.31.183.172`
(raylet)
(raylet) Refer to the documentation on how to address the out of memory issue: https://docs.ray.io/en/latest/ray-core/scheduling/ray-oom-prevention.html. Consider provisioning more memory on this node or reducing task parallelism by requesting more CPUs per task. To adjust the kill threshold, set the environment variable `RAY_memory_usage_threshold` when starting Ray. To disable worker killing, set the environment variable `RAY_memory_monitor_refresh_ms` to zero.
task failed with OutOfMemoryError, which is expected
Verify the task was indeed executed twice via ``task_oom_retry``:
Example: memory monitor prefers to kill a retriable task
Let’s first start Ray and specify the memory threshold.
RAY_memory_usage_threshold=0.4 ray start --head
Let’s create an application two_actors.py that submits two actors, where the first one is retriable and the second one is non-retriable.
from math import ceil
import ray
from ray._private.utils import (
get_system_memory,
) # do not use outside of this example as these are private methods.
from ray._private.utils import (
get_used_memory,
) # do not use outside of this example as these are private methods.
# estimates the number of bytes to allocate to reach the desired memory usage percentage.
def get_additional_bytes_to_reach_memory_usage_pct(pct: float) -> int:
used = get_used_memory()
total = get_system_memory()
bytes_needed = int(total * pct) - used
assert (
bytes_needed > 0
), "memory usage is already above the target. Increase the target percentage."
return bytes_needed
@ray.remote
class MemoryHogger:
def __init__(self):
self.allocations = []
def allocate(self, bytes_to_allocate: float) -> None:
# divide by 8 as each element in the array occupies 8 bytes
new_list = [0] * ceil(bytes_to_allocate / 8)
self.allocations.append(new_list)
first_actor = MemoryHogger.options(
max_restarts=1, max_task_retries=1, name="first_actor"
).remote()
second_actor = MemoryHogger.options(
max_restarts=0, max_task_retries=0, name="second_actor"
).remote()
# We want total bytes to exceed 40% threshold to trigger the memory monitor.
allocate_bytes = get_additional_bytes_to_reach_memory_usage_pct(0.5)
first_actor_task = first_actor.allocate.remote(0.9 * allocate_bytes)
second_actor_task = second_actor.allocate.remote(0.1* allocate_bytes)
error_thrown = False
try:
ray.get(first_actor_task)
except ray.exceptions.OutOfMemoryError as ex:
error_thrown = True
print("First started actor, which is retriable, was killed by the memory monitor.")
assert error_thrown
ray.get(second_actor_task)
print("Second started actor, which is not-retriable, finished.")
Run the application to see that only the first actor was killed.
$ python two_actors.py
First started actor, which is retriable, was killed by the memory monitor.
Second started actor, which is not-retriable, finished.
Questions or Issues?#
You can post questions or issues or feedback through the following channels:
Discussion Board: For questions about Ray usage or feature requests.
GitHub Issues: For bug reports.
Ray Slack: For getting in touch with Ray maintainers.
StackOverflow: Use the [ray] tag for questions about Ray.