Analyzing Tune Experiment Results#

In this guide, we’ll walk through some common workflows of what analysis you might want to perform after running your Tune experiment with tuner.fit().
Loading Tune experiment results from a directory
Basic experiment-level analysis: get a quick overview of how trials performed
Basic trial-level analysis: access individual trial hyperparameter configs and last reported metrics
Plotting the entire history of reported metrics for a trial
Accessing saved checkpoints (assuming that you have enabled checkpointing) and loading into a model for test inference
result_grid: ResultGrid = tuner.fit()
best_result: Result = result_grid.get_best_result()
The output of tuner.fit() is a ResultGrid, which is a collection of Result objects. See the linked documentation references for ResultGrid and Result for more details on what attributes are available.
Let’s start by performing a hyperparameter search with the MNIST PyTorch example. The training function is defined here, and we pass it into a Tuner to start running the trials in parallel.
import os
from ray import tune
from ray.tune import ResultGrid
from ray.tune.examples.mnist_pytorch import train_mnist
storage_path = "/tmp/ray_results"
exp_name = "tune_analyzing_results"
tuner = tune.Tuner(
train_mnist,
param_space={
"lr": tune.loguniform(0.001, 0.1),
"momentum": tune.grid_search([0.8, 0.9, 0.99]),
"should_checkpoint": True,
},
run_config=tune.RunConfig(
name=exp_name,
stop={"training_iteration": 100},
checkpoint_config=tune.CheckpointConfig(
checkpoint_score_attribute="mean_accuracy",
num_to_keep=5,
),
storage_path=storage_path,
),
tune_config=tune.TuneConfig(mode="max", metric="mean_accuracy", num_samples=3),
)
result_grid: ResultGrid = tuner.fit()
Loading experiment results from an directory#
Although we have the result_grid object in memory because we just ran the Tune experiment above, we might be performing this analysis after our initial training script has exited. We can retrieve the ResultGrid from a restored Tuner, passing in the experiment directory, which should look something like ~/ray_results/{exp_name}. If you don’t specify an experiment name in the RunConfig, the experiment name will be auto-generated and can be found in the logs of your experiment.
experiment_path = os.path.join(storage_path, exp_name)
print(f"Loading results from {experiment_path}...")
restored_tuner = tune.Tuner.restore(experiment_path, trainable=train_mnist)
result_grid = restored_tuner.get_results()
Loading results from /tmp/ray_results/tune_analyzing_results...
Experiment-level Analysis: Working with ResultGrid#
The first thing we might want to check is if there were any erroring trials.
# Check if there have been errors
if result_grid.errors:
print("One of the trials failed!")
else:
print("No errors!")
No errors!
Note that ResultGrid is an iterable, and we can access its length and index into it to access individual Result objects.
We should have 9 results in this example, since we have 3 samples for each of the 3 grid search values.
num_results = len(result_grid)
print("Number of results:", num_results)
Number of results: 9
# Iterate over results
for i, result in enumerate(result_grid):
if result.error:
print(f"Trial #{i} had an error:", result.error)
continue
print(
f"Trial #{i} finished successfully with a mean accuracy metric of:",
result.metrics["mean_accuracy"]
)
Trial #0 finished successfully with a mean accuracy metric of: 0.953125
Trial #1 finished successfully with a mean accuracy metric of: 0.9625
Trial #2 finished successfully with a mean accuracy metric of: 0.95625
Trial #3 finished successfully with a mean accuracy metric of: 0.946875
Trial #4 finished successfully with a mean accuracy metric of: 0.925
Trial #5 finished successfully with a mean accuracy metric of: 0.934375
Trial #6 finished successfully with a mean accuracy metric of: 0.965625
Trial #7 finished successfully with a mean accuracy metric of: 0.95625
Trial #8 finished successfully with a mean accuracy metric of: 0.94375
Above, we printed the last reported mean_accuracy metric for all trials by looping through the result_grid.
We can access the same metrics for all trials in a pandas DataFrame.
results_df = result_grid.get_dataframe()
results_df[["training_iteration", "mean_accuracy"]]
| training_iteration | mean_accuracy | |
|---|---|---|
| 0 | 100 | 0.953125 |
| 1 | 100 | 0.962500 |
| 2 | 100 | 0.956250 |
| 3 | 100 | 0.946875 |
| 4 | 100 | 0.925000 |
| 5 | 100 | 0.934375 |
| 6 | 100 | 0.965625 |
| 7 | 100 | 0.956250 |
| 8 | 100 | 0.943750 |
print("Shortest training time:", results_df["time_total_s"].min())
print("Longest training time:", results_df["time_total_s"].max())
Shortest training time: 8.674914598464966
Longest training time: 8.945653676986694
The last reported metrics might not contain the best accuracy each trial achieved. If we want to get maximum accuracy that each trial reported throughout its training, we can do so by using get_dataframe() specifying a metric and mode used to filter each trial’s training history.
best_result_df = result_grid.get_dataframe(
filter_metric="mean_accuracy", filter_mode="max"
)
best_result_df[["training_iteration", "mean_accuracy"]]
| training_iteration | mean_accuracy | |
|---|---|---|
| 0 | 50 | 0.968750 |
| 1 | 55 | 0.975000 |
| 2 | 95 | 0.975000 |
| 3 | 71 | 0.978125 |
| 4 | 65 | 0.959375 |
| 5 | 77 | 0.965625 |
| 6 | 82 | 0.975000 |
| 7 | 80 | 0.968750 |
| 8 | 92 | 0.975000 |
Trial-level Analysis: Working with an individual Result#
Let’s take a look at the result that ended with the best mean_accuracy metric. By default, get_best_result will use the same metric and mode as defined in the TuneConfig above. However, it’s also possible to specify a new metric/order in which results should be ranked.
from ray.tune import Result
# Get the result with the maximum test set `mean_accuracy`
best_result: Result = result_grid.get_best_result()
# Get the result with the minimum `mean_accuracy`
worst_performing_result: Result = result_grid.get_best_result(
metric="mean_accuracy", mode="min"
)
We can examine a few of the properties of the best Result. See the API reference for a list of all accessible properties.
First, we can access the best result’s hyperparameter configuration with Result.config.
best_result.config
{'lr': 0.009781335971854077, 'momentum': 0.9, 'should_checkpoint': True}
Next, we can access the trial directory via Result.path. The result path gives the trial level directory that contains checkpoints (if you reported any) and logged metrics to load manually or inspect using a tool like Tensorboard (see result.json, progress.csv).
best_result.path
'/tmp/ray_results/tune_analyzing_results/train_mnist_6e465_00007_7_lr=0.0098,momentum=0.9000_2023-08-25_17-42-27'
You can also directly get the latest checkpoint for a specific trial via Result.checkpoint.
# Get the last Checkpoint associated with the best-performing trial
best_result.checkpoint
Checkpoint(filesystem=local, path=/tmp/ray_results/tune_analyzing_results/train_mnist_6e465_00007_7_lr=0.0098,momentum=0.9000_2023-08-25_17-42-27/checkpoint_000099)
You can also get the last-reported metrics associated with a specific trial via Result.metrics.
# Get the last reported set of metrics
best_result.metrics
{'mean_accuracy': 0.965625,
'timestamp': 1693010559,
'should_checkpoint': True,
'done': True,
'training_iteration': 100,
'trial_id': '6e465_00007',
'date': '2023-08-25_17-42-39',
'time_this_iter_s': 0.08028697967529297,
'time_total_s': 8.77775764465332,
'pid': 94910,
'node_ip': '127.0.0.1',
'config': {'lr': 0.009781335971854077,
'momentum': 0.9,
'should_checkpoint': True},
'time_since_restore': 8.77775764465332,
'iterations_since_restore': 100,
'checkpoint_dir_name': 'checkpoint_000099',
'experiment_tag': '7_lr=0.0098,momentum=0.9000'}
Access the entire history of reported metrics from a Result as a pandas DataFrame:
result_df = best_result.metrics_dataframe
result_df[["training_iteration", "mean_accuracy", "time_total_s"]]
| training_iteration | mean_accuracy | time_total_s | |
|---|---|---|---|
| 0 | 1 | 0.168750 | 0.111393 |
| 1 | 2 | 0.609375 | 0.195086 |
| 2 | 3 | 0.800000 | 0.283543 |
| 3 | 4 | 0.840625 | 0.388538 |
| 4 | 5 | 0.840625 | 0.479402 |
| ... | ... | ... | ... |
| 95 | 96 | 0.946875 | 8.415694 |
| 96 | 97 | 0.943750 | 8.524299 |
| 97 | 98 | 0.956250 | 8.606126 |
| 98 | 99 | 0.934375 | 8.697471 |
| 99 | 100 | 0.965625 | 8.777758 |
100 rows × 3 columns
Plotting metrics#
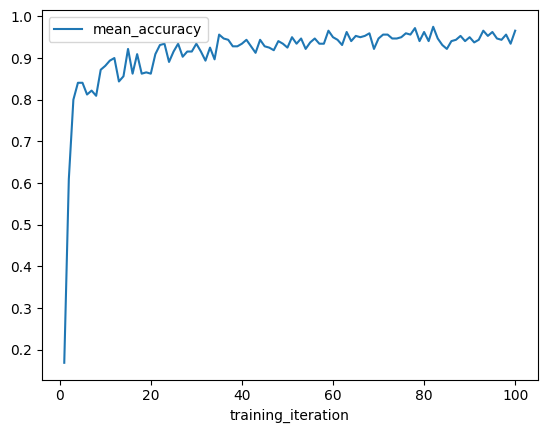
We can use the metrics DataFrame to quickly visualize learning curves. First, let’s plot the mean accuracy vs. training iterations for the best result.
best_result.metrics_dataframe.plot("training_iteration", "mean_accuracy")
<AxesSubplot:xlabel='training_iteration'>
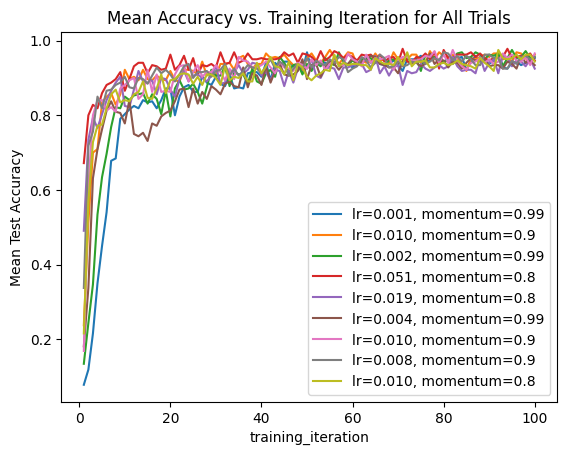
We can also iterate through the entire set of results and create a combined plot of all trials with the hyperparameters as labels.
ax = None
for result in result_grid:
label = f"lr={result.config['lr']:.3f}, momentum={result.config['momentum']}"
if ax is None:
ax = result.metrics_dataframe.plot("training_iteration", "mean_accuracy", label=label)
else:
result.metrics_dataframe.plot("training_iteration", "mean_accuracy", ax=ax, label=label)
ax.set_title("Mean Accuracy vs. Training Iteration for All Trials")
ax.set_ylabel("Mean Test Accuracy")
Text(0, 0.5, 'Mean Test Accuracy')
Accessing checkpoints and loading for test inference#
We saw earlier that Result contains the last checkpoint associated with a trial. Let’s see how we can use this checkpoint to load a model for performing inference on some sample MNIST images.
import torch
from ray.tune.examples.mnist_pytorch import ConvNet, get_data_loaders
model = ConvNet()
with best_result.checkpoint.as_directory() as checkpoint_dir:
# The model state dict was saved under `model.pt` by the training function
# imported from `ray.tune.examples.mnist_pytorch`
model.load_state_dict(torch.load(os.path.join(checkpoint_dir, "model.pt")))
Refer to the training loop definition here to see how we are saving the checkpoint in the first place.
Next, let’s test our model with a sample data point and print out the predicted class.
import matplotlib.pyplot as plt
_, test_loader = get_data_loaders()
test_img = next(iter(test_loader))[0][0]
predicted_class = torch.argmax(model(test_img)).item()
print("Predicted Class =", predicted_class)
# Need to reshape to (batch_size, channels, width, height)
test_img = test_img.numpy().reshape((1, 1, 28, 28))
plt.figure(figsize=(2, 2))
plt.imshow(test_img.reshape((28, 28)))
Predicted Class = 9
<matplotlib.image.AxesImage at 0x31ddd2fd0>
Consider using Ray Data if you want to use a checkpointed model for large scale inference!
Summary#
In this guide, we looked at some common analysis workflows you can perform using the ResultGrid output returned by Tuner.fit. These included: loading results from an experiment directory, exploring experiment-level and trial-level results, plotting logged metrics, and accessing trial checkpoints for inference.
Take a look at Tune’s experiment tracking integrations for more analysis tools that you can build into your Tune experiment with a few callbacks!