Ray Data Benchmarks#
This page documents benchmark results and methodologies for evaluating Ray Data performance across a variety of data modalities and workloads.
Workload Summary#
Image Classification: Processing 800k ImageNet images using ResNet18. The pipeline downloads images, deserializes them, applies transformations, runs ResNet18 inference on GPU, and outputs predicted labels.
Document Embedding: Processing 10k PDF documents from Digital Corpora. The pipeline reads PDF documents, extracts text page-by-page, splits into chunks with overlap, embeds using a
all-MiniLM-L6-v2model on GPU, and outputs embeddings with metadata.Audio Transcription: Transcribing 113,800 audio files from Mozilla Common Voice 17 dataset using a Whisper-tiny model. The pipeline loads FLAC audio files, resamples to 16kHz, extracts features using Whisper’s processor, runs GPU-accelerated batch inference with the model, and outputs transcriptions with metadata.
Video Object Detection: Processing 10k video frames from Hollywood2 action videos dataset using YOLOv11n for object detection. The pipeline loads video frames, resizes them to 640x640, runs batch inference with YOLO to detect objects, extracts individual object crops, and outputs object metadata and cropped images in Parquet format.
Large-scale Image Embedding: Processing 4TiB of base64-encoded images from a Parquet dataset using ViT for image embedding. The pipeline decodes base64 images, converts to RGB, preprocesses using ViTImageProcessor (resizing, normalization), runs GPU-accelerated batch inference with ViT to generate embeddings, and outputs results to Parquet format.
Ray Data 2.50 is compared with Daft 0.6.2, an open source multimodal data processing library built on Ray.
Results Summary#
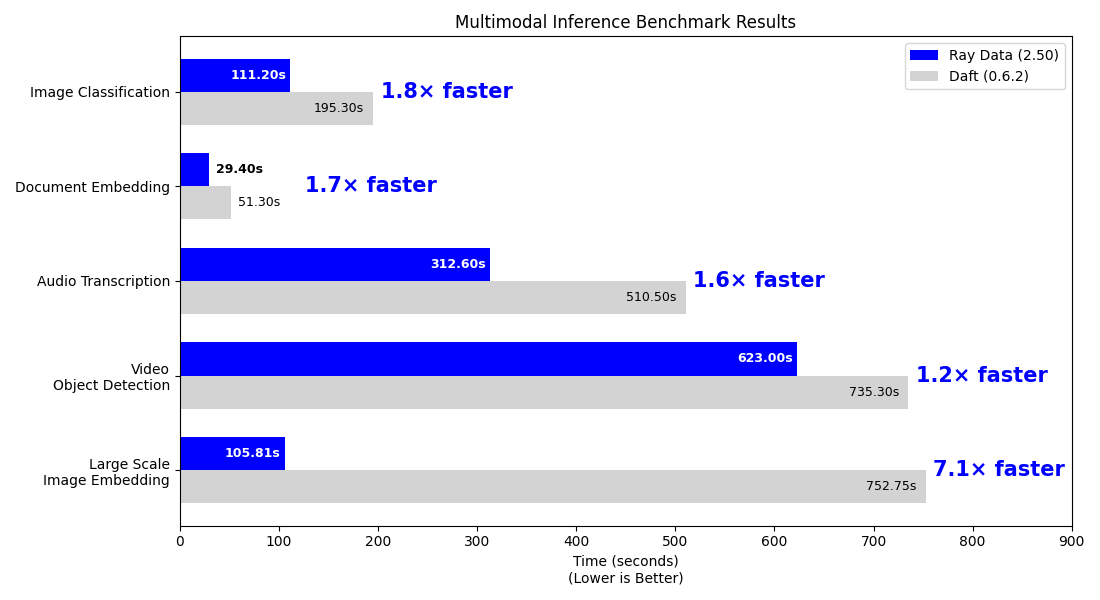
Workload |
Daft (s) |
Ray Data (s) |
|---|---|---|
Image Classification |
195.3 ± 2.5 |
111.2 ± 1.2 |
Document Embedding |
51.3 ± 1.3 |
29.4 ± 0.8 |
Audio Transcription |
510.5 ± 10.4 |
312.6 ± 3.1 |
Video Object Detection |
735.3 ± 7.6 |
623 ± 1.4 |
Large Scale Image Embedding |
752.75 ± 5.5 |
105.81 ± 0.79 |
All benchmark results are taken from an average/std across 4 runs. A warmup was also run to download the model and remove any startup overheads that would affect the result.
Workload Configuration#
Workload |
Dataset |
Data Path |
Cluster Configuration |
Code |
|---|---|---|---|---|
Image Classification |
800k images from ImageNet |
s3://ray-example-data/imagenet/metadata_file.parquet |
1 head / 8 workers of varying instance types |
|
Document Embedding |
10k PDFs from Digital Corpora |
s3://ray-example-data/digitalcorpora/metadata |
g6.xlarge head, 8 g6.xlarge workers |
|
Audio Transcription |
113,800 audio files from Mozilla Common Voice 17 en dataset |
s3://air-example-data/common_voice_17/parquet/ |
g6.xlarge head, 8 g6.xlarge workers |
|
Video Object Detection |
1,000 videos from Hollywood-2 Human Actions dataset |
s3://ray-example-data/videos/Hollywood2-actions-videos/Hollywood2/AVIClips/ |
1 head, 8 workers of varying instance types |
|
Large-scale Image Embedding |
4 TiB of Parquet files containing base64 encoded images |
s3://ray-example-data/image-datasets/10TiB-b64encoded-images-in-parquet-v3/ |
m5.24xlarge (head), 40 g6e.xlarge (gpu workers), 64 r6i.8xlarge (cpu workers) |
Image Classification across different instance types#
This experiment compares the performance of Ray Data with Daft on the image classification workload across a variety of instance types. Each run is an average/std across 3 runs. A warmup was also run to download the model and remove any startup overheads that would affect the result.
g6.xlarge (4 CPUs) |
g6.2xlarge (8 CPUs) |
g6.4xlarge (16 CPUs) |
g6.8xlarge (32 CPUs) |
|
|---|---|---|---|---|
Ray Data (s) |
456.2 ± 39.9 |
195.5 ± 7.6 |
144.8 ± 1.9 |
111.2 ± 1.2 |
Daft (s) |
315.0 ± 31.2 |
202.0 ± 2.2 |
195.0 ± 6.6 |
195.3 ± 2.5 |
Video Object Detection across different instance types#
This experiment compares the performance of Ray Data with Daft on the video object detection workload across a variety of instance types. Each run is an average/std across 4 runs. A warmup was also run to download the model and remove any startup overheads that would affect the result.
g6.xlarge (4 CPUs) |
g6.2xlarge (8 CPUs) |
g6.4xlarge (16 CPUs) |
g6.8xlarge (32 CPUs) |
|
|---|---|---|---|---|
Ray Data (s) |
922 ± 13.8 |
704.8 ± 25.0 |
629 ± 1.8 |
623 ± 1.4 |
Daft (s) |
758.8 ± 10.4 |
735.3 ± 7.6 |
747.5 ± 13.4 |
771.3 ± 25.6 |