Use Custom Algorithm for Request Routing#
Warning
This API is in alpha and may change before becoming stable.
Different Ray serve applications demand different logics for load balancing. For example, in serving LLMs you might want to have a different policy than balancing number of requests across replicas: e.g. balancing ongoing input tokens, balancing kv-cache utilization, etc. RequestRouter is an abstraction in Ray Serve that allows extension and customization of load-balancing logic for each deployment.
This guide shows how to use RequestRouter API to achieve custom load balancing across replicas of a given deployment. It will cover the following:
Define a simple uniform request router for load balancing
Deploy an app with the uniform request router
Utility mixins for request routing
Define a complex throughput-aware request router
Deploy an app with the throughput-aware request router
Experimental: Use the round-robin request router
Experimental: Use the consistent-hash request router for session stickiness
Experimental: Define a centralized capacity queue request router
Define simple uniform request router#
Create a file custom_request_router.py with the following code:
import random
from ray.serve.request_router import (
PendingRequest,
RequestRouter,
ReplicaID,
ReplicaResult,
RunningReplica,
)
from typing import (
List,
Optional,
)
class UniformRequestRouter(RequestRouter):
async def choose_replicas(
self,
candidate_replicas: List[RunningReplica],
pending_request: Optional[PendingRequest] = None,
) -> List[List[RunningReplica]]:
print("UniformRequestRouter routing request")
index = random.randint(0, len(candidate_replicas) - 1)
return [[candidate_replicas[index]]]
def on_request_routed(
self,
pending_request: PendingRequest,
replica_id: ReplicaID,
result: ReplicaResult,
):
print("on_request_routed callback is called!!")
This code defines a simple uniform request router that routes requests a random replica to distribute the load evenly regardless of the queue length of each replica or the body of the request. The router is defined as a class that inherits from RequestRouter. It implements the choose_replicas method, which returns the random replica for all incoming requests. The returned type is a list of lists of replicas, where each inner list represents a rank of replicas. The first rank is the most preferred and the last rank is the least preferred. The request will be attempted to be routed to the replica with the shortest request queue in each set of the rank in order until a replica is able to process the request. If none of the replicas are able to process the request, choose_replicas will be called again with a backoff delay until a replica is able to process the request.
Note
This request router also implements on_request_routed which can help you update the state of the request router after a request is routed.
Deploy an app with the uniform request router#
To use a custom request router, you need to pass the request_router_class argument to the deployment decorator. Also note that the request_router_class can be passed as the already imported class or as the string of import path to the class. Let’s deploy a simple app that uses the uniform request router like this:
from ray import serve
from ray.serve.request_router import ReplicaID
import time
from collections import defaultdict
from ray.serve.context import _get_internal_replica_context
from typing import Any, Dict
from ray.serve.config import RequestRouterConfig
@serve.deployment(
request_router_config=RequestRouterConfig(
request_router_class="custom_request_router:UniformRequestRouter",
),
num_replicas=10,
ray_actor_options={"num_cpus": 0},
)
class UniformRequestRouterApp:
def __init__(self):
context = _get_internal_replica_context()
self.replica_id: ReplicaID = context.replica_id
async def __call__(self):
return self.replica_id
handle = serve.run(UniformRequestRouterApp.bind())
response = handle.remote().result()
print(f"Response from UniformRequestRouterApp: {response}")
# Example output:
# Response from UniformRequestRouterApp:
# Replica(id='67vc4ts5', deployment='UniformRequestRouterApp', app='default')
As the request is routed, both “UniformRequestRouter routing request” and “on_request_routed callback is called!!” messages will be printed to the console. The response will also be randomly routed to one of the replicas. You can test this by sending more requests and seeing the distribution of the replicas are roughly equal.
Note
Currently, the only way to configure the request router is to pass it as an argument to the deployment decorator. This means that you cannot change the request router for an existing deployment handle with running router. If you have a particular usecase where you need to reconfigure a request router on the deployment handle, please open a feature request on the Ray GitHub repository
Utility mixins for request routing#
Ray Serve provides utility mixins that can be used to extend the functionality of the request router. These mixins can be used to implement common routing policies such as locality-aware routing, multiplexed model support, and FIFO request routing.
FIFOMixin: This mixin implements first in first out (FIFO) request routing. The default behavior for the request router is OOO (out of order) which routes requests to the exact replica which got assigned by the request passed tochoose_replicas. This mixin is useful for the routing algorithm that can work independently of the request content, so the requests can be routed as soon as possible in the order they were received. By including this mixin, in your custom request router, the request matching algorithm will be updated to route requests FIFO. There are no additional flags needs to be configured and no additional helper methods provided by this mixin.LocalityMixin: This mixin implements locality-aware request routing. It updates the internal states when between replica updates to track the location between replicas in the same node, same zone, and everything else. It offers helpersapply_locality_routingandrank_replicas_via_localityto route and ranks replicas based on their locality to the request, which can be useful for reducing latency and improving performance.MultiplexMixin: When you use model-multiplexing you need to route requests based on knowing which replica has already a hot version of the model. It updates the internal states when between replica updates to track the model loaded on each replica, and size of the model cache on each replica. It offers helpersapply_multiplex_routingandrank_replicas_via_multiplexto route and ranks replicas based on their multiplexed model id of the request.
Define a complex throughput-aware request router#
A fully featured request router can be more complex and should take into account the multiplexed model, locality, the request queue length on each replica, and using custom statistics like throughput to decide which replica to route the request to. The following class defines a throughput-aware request router that routes requests to the replica with these factors in mind. Add the following code into the custom_request_router.py file:
from ray.serve.request_router import (
FIFOMixin,
LocalityMixin,
MultiplexMixin,
PendingRequest,
RequestRouter,
ReplicaID,
ReplicaResult,
RunningReplica,
)
from typing import (
Dict,
List,
Optional,
)
class ThroughputAwareRequestRouter(
FIFOMixin, MultiplexMixin, LocalityMixin, RequestRouter
):
async def choose_replicas(
self,
candidate_replicas: List[RunningReplica],
pending_request: Optional[PendingRequest] = None,
) -> List[List[RunningReplica]]:
"""
This method chooses the best replica for the request based on
multiplexed, locality, and custom throughput stats. The algorithm
works as follows:
1. Populate top_ranked_replicas based on available replicas based on
multiplex_id
2. Populate and override top_ranked_replicas info based on locality
information of replicas (we want to prefer replicas that are in the
same vicinity to this deployment)
3. Select the replica with minimum throughput.
"""
# Dictionary to hold the top-ranked replicas
top_ranked_replicas: Dict[ReplicaID, RunningReplica] = {}
# Take the best set of replicas for the multiplexed model
if (
pending_request is not None
and pending_request.metadata.multiplexed_model_id
):
ranked_replicas_multiplex: List[RunningReplica] = (
self.rank_replicas_via_multiplex(
replicas=candidate_replicas,
multiplexed_model_id=pending_request.metadata.multiplexed_model_id,
)
)[0]
# Filter out replicas that are not available (queue length exceed max ongoing request)
ranked_replicas_multiplex = self.select_available_replicas(
candidates=ranked_replicas_multiplex
)
for replica in ranked_replicas_multiplex:
top_ranked_replicas[replica.replica_id] = replica
# Take the best set of replicas in terms of locality
ranked_replicas_locality: List[
RunningReplica
] = self.rank_replicas_via_locality(replicas=candidate_replicas)[0]
# Filter out replicas that are not available (queue length exceed max ongoing request)
ranked_replicas_locality = self.select_available_replicas(
candidates=ranked_replicas_locality
)
for replica in ranked_replicas_locality:
top_ranked_replicas[replica.replica_id] = replica
print("ThroughputAwareRequestRouter routing request")
# Take the replica with minimum throughput.
min_throughput_replicas = min(
[replica for replica in top_ranked_replicas.values()],
key=lambda r: r.routing_stats.get("throughput", 0),
)
return [[min_throughput_replicas]]
This request router inherits from RequestRouter, as well as FIFOMixin for FIFO request routing, LocalityMixin for locality-aware request routing, and MultiplexMixin for multiplexed model support. It implements choose_replicas to take the highest ranked replicas from rank_replicas_via_multiplex and rank_replicas_via_locality and uses the select_available_replicas helper to filter out replicas that have reached their maximum request queue length. Finally, it takes the replicas with the minimum throughput and returns the top one.
Deploy an app with the throughput-aware request router#
To use the throughput-aware request router, you can deploy an app like this:
def _time_ms() -> int:
return int(time.time() * 1000)
@serve.deployment(
request_router_config=RequestRouterConfig(
request_router_class="custom_request_router:ThroughputAwareRequestRouter",
request_routing_stats_period_s=1,
request_routing_stats_timeout_s=1,
),
num_replicas=3,
ray_actor_options={"num_cpus": 0},
)
class ThroughputAwareRequestRouterApp:
def __init__(self):
self.throughput_buckets: Dict[int, int] = defaultdict(int)
self.last_throughput_buckets = _time_ms()
context = _get_internal_replica_context()
self.replica_id: ReplicaID = context.replica_id
def __call__(self):
self.update_throughput()
return self.replica_id
def update_throughput(self):
current_timestamp_ms = _time_ms()
# Under high concurrency, requests can come in at different times. This
# early return helps to skip if the current_timestamp_ms is more than a
# second older than the last throughput bucket.
if current_timestamp_ms < self.last_throughput_buckets - 1000:
return
# Record the request to the bucket
self.throughput_buckets[current_timestamp_ms] += 1
self.last_throughput_buckets = current_timestamp_ms
def record_routing_stats(self) -> Dict[str, Any]:
current_timestamp_ms = _time_ms()
throughput = 0
for t, c in list(self.throughput_buckets.items()):
if t < current_timestamp_ms - 1000:
# Remove the bucket if it is older than 1 second
self.throughput_buckets.pop(t)
else:
throughput += c
return {
"throughput": throughput,
}
handle = serve.run(ThroughputAwareRequestRouterApp.bind())
response = handle.remote().result()
print(f"Response from ThroughputAwareRequestRouterApp: {response}")
# Example output:
# Response from ThroughputAwareRequestRouterApp:
# Replica(id='tkywafya', deployment='ThroughputAwareRequestRouterApp', app='default')
Similar to the uniform request router, the custom request router can be defined in the request_router_class argument of the deployment decorator. The Serve controller pulls statistics from the replica of each deployment by calling record_routing_stats. The request_routing_stats_period_s and request_routing_stats_timeout_s arguments control the frequency and timeout time of the serve controller pulling information from each replica in its background thread. You can customize the emission of these statistics by overriding record_routing_stats in the definition of the deployment class. The custom request router can then get the updated routing stats by looking up the routing_stats attribute of the running replicas and use it in the routing policy.
Experimental: Use the round-robin request router#
RoundRobinRouter cycles through replicas in round-robin fashion, starting at an arbitrary replica so routers spun up together don’t synchronize on the same first replica. If the chosen replica is at capacity, the router falls back to the next replica in order and wraps around the candidate list. Each router instance keeps its own cursor, so with multiple routers (for example, one per Ray Serve proxy) the fan-out is round-robin per router and approximately uniform across replicas in aggregate. The router mixes in FIFOMixin so queued requests are routed in arrival order.
When to use#
Use the round-robin router when you want a predictable, even distribution across replicas and don’t need load-aware or locality-aware decisions. It fits stateless workloads with roughly uniform per-request latency. Unlike the default power-of-two-choices router, the round-robin router doesn’t compare replicas by their number of ongoing requests. It only skips a replica once it reaches max_ongoing_requests. Therefore, requests can pile up behind a slow replica before it falls back to the next one.
Example#
Reference the router by import path through RequestRouterConfig:
@serve.deployment(
request_router_config=RequestRouterConfig(
request_router_class=(
"ray.serve.experimental.round_robin_router:RoundRobinRouter"
),
),
num_replicas=4,
ray_actor_options={"num_cpus": 0},
)
class RoundRobinRouterApp:
def __init__(self):
context = _get_internal_replica_context()
self.replica_id: ReplicaID = context.replica_id
async def __call__(self):
return self.replica_id
handle = serve.run(RoundRobinRouterApp.bind())
response = handle.remote().result()
print(f"Response from RoundRobinRouterApp: {response}")
Experimental: Use the consistent-hash request router for session stickiness#
ConsistentHashRouter pins each session to a specific replica using a consistent-hash ring with virtual nodes. The routing key is the session ID read from the HTTP header named by RAY_SERVE_SESSION_ID_HEADER_KEY (default x-session-id), so the same session ID consistently maps to the same replica. Requests without that header fall back to a per-request internal ID and spread uniformly across replicas. If the chosen replica rejects (for example, due to backpressure from the number of ongoing request), the router walks up to num_fallback_replicas clockwise successors on the ring. If those are also at capacity, the router sleeps with exponential backoff and retries the same primary and fallbacks until one accepts. When the replica set changes, the ring is rebuilt and only keys owned by added or removed replicas are reshuffled.
Two parameters are configurable through request_router_kwargs:
num_virtual_nodes(default100): vnodes per replica on the ring. Higher values spread sessions more evenly across replicas.num_fallback_replicas(default2): clockwise successors tried after the primary rejects. Set to0for strict affinity with no fallback.
When to use#
Use the consistent-hash router when requests carry session-scoped state worth keeping warm on a single replica, for example in-memory caches keyed by user or KV-cache reuse for LLM chat sessions. Skip it for stateless workloads, since affinity sacrifices queue-aware balancing and a hot session can saturate its assigned replica while others are idle. The router does not combine with queue-depth, locality, or multiplexed-model signals, since mixing them in would break determinism and therefore break affinity.
Example#
Configure the router via RequestRouterConfig and pass tuning parameters through request_router_kwargs:
import requests
from starlette.requests import Request
@serve.deployment(
request_router_config=RequestRouterConfig(
request_router_class=(
"ray.serve.experimental.consistent_hash_router:ConsistentHashRouter"
),
request_router_kwargs={
"num_virtual_nodes": 100,
"num_fallback_replicas": 2,
},
),
num_replicas=4,
ray_actor_options={"num_cpus": 0},
)
class ConsistentHashRouterApp:
def __init__(self):
context = _get_internal_replica_context()
self.replica_id: ReplicaID = context.replica_id
async def __call__(self, request: Request) -> str:
return str(self.replica_id)
serve.run(ConsistentHashRouterApp.bind())
# Clients pin a session to a replica by sending the same `x-session-id`
# on every request.
response = requests.get(
"http://localhost:8000/",
headers={"x-session-id": "example-session-id"},
)
print(f"Response from ConsistentHashRouterApp: {response.text}")
# Example output:
# Response from ConsistentHashRouterApp:
# Replica(id='...', deployment='ConsistentHashRouterApp', app='default')
If your clients send the session identifier under a different header (for example, x-correlation-id), point Ray Serve at it before the cluster starts:
export RAY_SERVE_SESSION_ID_HEADER_KEY=x-correlation-id
Experimental: Define a centralized capacity queue request router#
In the previous examples, the routing decisions are based on the locally visible state of the target replicas from the perspective of the router replica. This view is eventually consistent not strongly because the serve controller frequently broadcasts the replica information to the router. Under high concurrency with multiple routers, this information can drift from reality and can cause several routers to simultaneously pick the same replica, causing transient load imbalance or triggering rejections and retries. For some applications this can result in lower throughput. A centralized approach avoids this: a single actor tracks per-replica in-flight counts, and every router acquires a capacity token before forwarding a request. This way, each token guarantees the target replica has room, eliminating the rejection protocol entirely.
This example demonstrates how we can implement such routing policy. The example has three pieces:
An importable
CapacityQueueactor that tracks per-replica capacity and hands out tokens using a least-loaded selection strategy.An importable
CapacityQueueRoutercustom request router that acquires a token before routing and releases it when the request completes. In a real application, we can have multiple replicas ofCapacityQueueRoutereach one keeping tracking their own view of state of replicas. The centralizedCapacityQueueactor is meant to keep their local information synchronized with reality.A deployment that ties them together using a deployment actor for the queue and a
RequestRouterConfigfor the router.
Deploy an app with the capacity queue router#
The deployment wires the pieces together: a DeploymentActorConfig for the capacity queue and a RequestRouterConfig pointing at the custom router:
import ray
from ray import serve
from ray.serve.config import DeploymentActorConfig, RequestRouterConfig
from ray.serve.context import _get_internal_replica_context
from ray.serve.experimental.capacity_queue import (
CapacityQueue,
)
@serve.deployment(
deployment_actors=[
DeploymentActorConfig(
name="capacity_queue",
actor_class=CapacityQueue,
init_kwargs={
"acquire_timeout_s": 0.5,
"token_ttl_s": 5,
},
actor_options={"num_cpus": 0},
),
],
request_router_config=RequestRouterConfig(
request_router_class=(
"ray.serve.experimental.capacity_queue_router:CapacityQueueRouter"
),
request_router_kwargs={
"capacity_queue_actor_name": "capacity_queue",
# Fall back to Pow2 after this many consecutive CapacityQueue faults.
"max_fault_retries": 3,
},
# Backoff between retries when the CapacityQueue is unavailable or capacity is exhausted.
initial_backoff_s=0.05,
backoff_multiplier=2.0,
max_backoff_s=1.0,
),
num_replicas=3,
max_ongoing_requests=5,
ray_actor_options={"num_cpus": 0},
)
class CapacityQueueApp:
def __init__(self):
context = _get_internal_replica_context()
self.replica_id = context.replica_id
async def __call__(self):
return self.replica_id
handle = serve.run(CapacityQueueApp.bind())
response = handle.remote().result()
print(f"Response from CapacityQueueApp: {response}")
When the app starts:
The Serve controller creates the
CapacityQueuedeployment actor before any replicas start.CapacityQueuesubscribes to replica updates via long poll.As the controller starts replicas, it sends deployment-target updates. The queue’s long-poll callback automatically registers each replica with its
max_ongoing_requestscapacity and unregisters replicas that are removed during scale-down or crash recovery.The
CapacityQueueRouterrunning in each proxy discovers the singletonCapacityQueuedeployment actor, acquires a token for every incoming request, and routes to the replica identified by the token.When the request completes,
CapacityQueueRouter.on_request_completedfires and the token is released back to the queue.
Because the queue is a deployment actor, the controller handles its lifecycle automatically — health checks, cleanup on app deletion, and versioning during rolling updates.
Fault tolerance#
The CapacityQueueRouter handles failures gracefully:
Queue unavailable — if the queue actor is dead, not yet discovered, or errors, the router retries with exponential backoff and falls back to power-of-two-choices after
MAX_FAULT_RETRIESconsecutive failures. Requests never raise exceptions due to queue issues.Capacity exhausted — when all replicas are at capacity, the router backs off and retries until capacity frees up.
Queue restart — a restarted queue has no knowledge of pre-crash in-flight counts and may temporarily over-provision. This self-heals: replicas reject excess requests, and the router does not release rejected tokens intentionally, ratcheting up
in_flighton the queue until it matches reality.token_ttl_s(if configured) auto-reclaims any remaining leaked tokens.Replica death — the controller sends a long-poll update, the queue unregisters the dead replica, and tokens are only issued for live replicas.
Usage#
The centralized capacity queue request router could bring performance benefits particularly in a constrained supply deployment, i.e. max_ongoing_request=1 or 2.
Benchmark#
Benchmark Setup#
Deployment topology: Client ->
ParentDeployment->ChildDeployment. Request router selection is applied to both deployments, controlling how parent replicas are selected by the HTTP proxy and how child replicas are selected by parent’sDeploymentHandle.Scale: small (8 replicas), medium (32 replicas), large (128 replicas), xlarge (512 replicas).
Workload: Replica processing latency is drawn from an exponential distribution with mean 1s and capped at 10s.
max_ongoing_requestis set to2.Load generation: Applies closed-loop load generation where the load consistently keeps replicas saturated at
max_ongoing_requestconcurrency.Warmup: 10s; metrics within the warmup window are discarded entirely.
Benchmark Metrics#
Throughput: Requests per second, i.e.
num_requests / duration.Utilization: Measures what fraction of a replica’s total processing capacity was consumed by actual work during the experiment. Concretely,
sum(replica_processing_latency_s) / (duration_s * max_ongoing_requests). For GPU deployments, utilization serves as an assessment proxy for GPU utilization.Latency: Measures the client-side end-to-end latency, covering the full round-trip – client ->
ParentDeployment->ChildDeployment->ParentDeployment-> client.
Normal Situation#
Under normal (success) situations, CapacityQueueRouter yields higher throughput and utilization and lower latency.

Fault Situation#
A fault is simulated by killing the CapacityQueue router, and upon recovery, CapacityQueue converges towards its pre-fault performance.
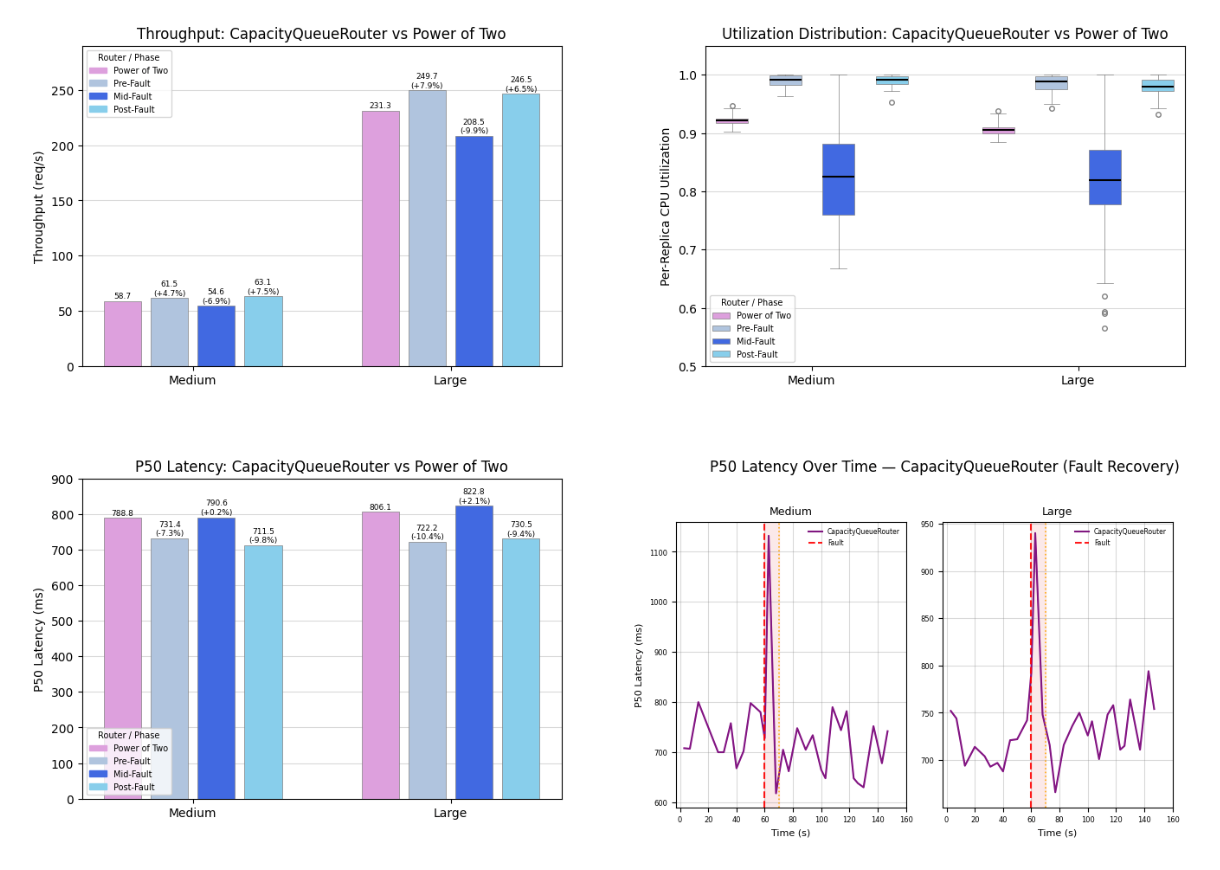
Note
If you experience the following error when the CapacityQueue actor experiences faults and routing decisions fall back to the power-of-two-choices router, set RAY_SERVE_QUEUE_LENGTH_RESPONSE_DEADLINE_S to a higher value.
Failed to get queue length from Replica(id=‘…’, deployment=‘ParentDeployment’, app=‘…’) within 0.1s.
Warning
Gotchas and limitations
When you provide a custom router, Ray Serve can fully support it as long as it’s simple, self-contained Python code that relies only on the standard library. Once the router becomes more complex, such as depending on other custom modules or packages, you need to ensure those modules are bundled into the Docker image or environment. This is because Ray Serve uses cloudpickle to serialize custom routers and it doesn’t vendor transitive dependencies—if your router inherits from a superclass in another module or imports custom packages, those must exist in the target environment. Additionally, environment parity matters: differences in Python version, cloudpickle version, or library versions can affect deserialization.
Alternatives for complex routers
When your custom request router has complex dependencies or you want better control over versioning and deployment, you have several alternatives:
Use built-in routers: Consider using the routers shipped with Ray Serve—these are well-tested, production-ready, and guaranteed to work across different environments.
Contribute to Ray Serve: If your router is general-purpose and might benefit others, consider contributing it to Ray Serve as a built-in router by opening a feature request or pull request on the Ray GitHub repository. The recommended location for the implementation is
python/ray/serve/_private/request_router/.Ensure dependencies in your environment: Make sure that the external dependencies are installed in your Docker image or environment.