Enable High Throughput on Ray Serve with KubeRay#
Take advantage of major upgrades to Ray Serve, delivering online inference with 88% lower latency and 11.1x higher throughput.
Prerequisites#
Ray 2.56 or later
Enabling high throughput mode#
With Ray 2.56 and later, high throughput config options are available for Ray Serve by setting the following environment variables:
RAY_SERVE_ENABLE_HA_PROXY=1: Enables HAProxy ingress for each Ray pod’s proxy ingress (serving on port 8000 by default), which is a highly optimized, battle-tested open-source load balancer written in C.RAY_SERVE_THROUGHPUT_OPTIMIZED=1: Enables multiple high throughput serving optimizations, including direct gRPC data-plane communications between Ray Serve replicas, improving the performance of inter-deployment traffic.RAY_SERVE_LLM_ENABLE_DIRECT_STREAMING=1: Enables direct streaming, allowing requests and responses to stream directly to the backend server instead of passing through an ingress.VLLM_USE_RAY_V2_EXECUTOR_BACKEND=1: Configures vLLM to use the Ray V2 executor backend.
Example: Serving Qwen on GKE#
The following example demonstrates how to deploy Qwen 3.5 on four replicas with NVIDIA L4 GPUs using KubeRay on Google Kubernetes Engine (GKE) with this sample RayService.
A corresponding sample for high-performance serving with Gemma 4 E2B with NVIDIA B200s is also available here.
1. Configure the environment#
Set the following environment variables for your project:
CLUSTER=serve-qwen-optimized
PROJECT=$(gcloud config get-value project)
LOCATION=us-central1-b
REGION=us-central1
HUGGING_FACE_TOKEN=<your-token>
2. Create the GKE cluster with KubeRay#
Create a GKE cluster:
gcloud container clusters create $CLUSTER \
--project $PROJECT \
--location $LOCATION \
--machine-type=e2-standard-16 \
--num-nodes=1
3. Install the KubeRay operator#
Install the most recent stable KubeRay operator from the Helm repository by following Deploy a KubeRay operator. The Kubernetes NoSchedule taint in the example config prevents the KubeRay operator pod from running on a GPU node.
4. Configure the GPU node pool#
Create a node pool with NVIDIA L4 GPUs:
gcloud container node-pools create gpu-pool \
--cluster=$CLUSTER \
--location=$LOCATION \
--accelerator="type=nvidia-l4,count=1,gpu-driver-version=latest" \
--machine-type=g2-standard-8 \
--num-nodes=4
5. Set up Hugging Face access#
Create a Kubernetes secret with your Hugging Face API token:
kubectl create secret generic hf-secret \
--from-literal=hf_api_token=${HUGGING_FACE_TOKEN?}
6. Deploy the RayService#
Deploy the example high-throughput LLM service:
kubectl apply -f https://raw.githubusercontent.com/ray-project/kuberay/master/ray-operator/config/samples/ray-service.high-throughput-llm.yaml
To enable these optimizations on your own Ray Service, add these environment variables to both the head and worker group specifications:
apiVersion: ray.io/v1
kind: RayService
metadata:
name: my-ray-service
spec:
serveConfigV2: ...
rayClusterConfig:
headGroupSpec:
template:
spec:
containers:
- name: ray-head
env:
- name: RAY_SERVE_ENABLE_HA_PROXY
value: "1"
- name: RAY_SERVE_THROUGHPUT_OPTIMIZED
value: "1"
- name: RAY_SERVE_LLM_ENABLE_DIRECT_STREAMING
value: "1"
- name: VLLM_USE_RAY_V2_EXECUTOR_BACKEND
value: "1"
workerGroupSpecs:
- template:
spec:
containers:
- name: worker
env:
- name: RAY_SERVE_ENABLE_HA_PROXY
value: "1"
- name: RAY_SERVE_THROUGHPUT_OPTIMIZED
value: "1"
- name: RAY_SERVE_LLM_ENABLE_DIRECT_STREAMING
value: "1"
- name: VLLM_USE_RAY_V2_EXECUTOR_BACKEND
value: "1"
7. Verify HAProxy status#
Using the Ray kubectl plugin or kubectl port-forward to establish a connection to the Ray head:
CLUSTER=$(kubectl get raycluster -o jsonpath='{.items[0].metadata.name}')
kubectl ray session $CLUSTER
Now, use the Ray CLI to check for HAProxy. Alternatively, navigate to the Ray dashboard’s Actors tab and search for class HAProxyManager.
ray list actors | grep HAProxy
You should see an HAProxy for the head pod and every worker. If there are fewer HAProxy actors than there are pods, double check your configuration.
For example: 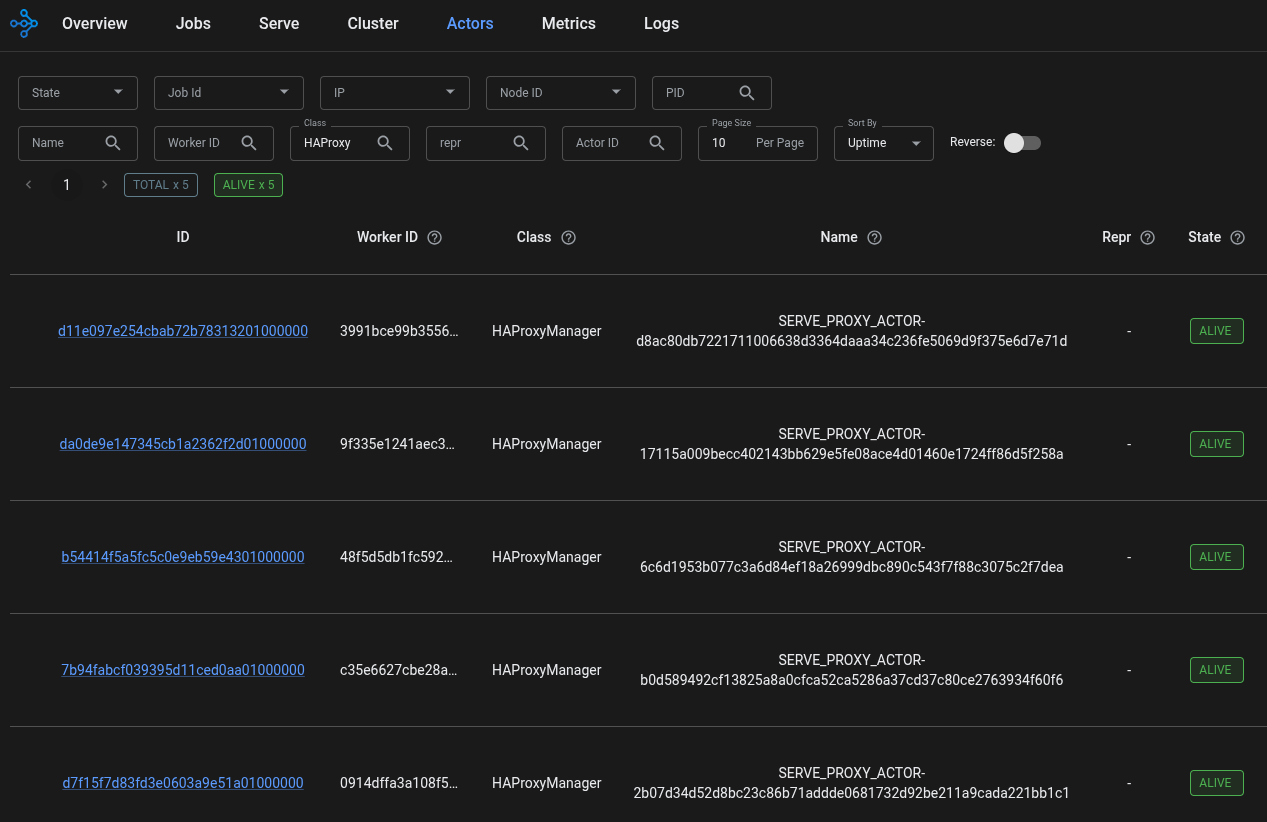 .
.
Expected performance#
See the announcement blog post for detailed performance numbers.
The optimizations work best with deployments with high load, where the serve app handles 50+ requests per second, concurrent connections per replica is greater than 250, and bursty traffic.
Performance gains scale with the size of the deployment. The more replicas your RayService is using, the greater the performance improvement compared to versions preceding 2.56.
Next steps#
Learn more about Ray Serve Performance Tuning.
Read the technical deep dive: Ray Serve: Lower Latency and Higher Throughput with HAProxy.