Distributed training of a DLinear time-series model#

This tutorial executes a distributed training workload that connects the following steps with heterogeneous compute requirements:
Preprocessing the dataset with Ray Data
Distributed training of a DLinear model with Ray Train
Note: This tutorial doesn’t including tuning of the model. See Ray Tune for experiment execution and hyperparameter tuning.

Before starting, run the setup steps outlined in the README.
import os
# Enable Ray Train v2. This is the default in an upcoming release.
os.environ["RAY_TRAIN_V2_ENABLED"] = "1"
# Now it's safe to import from ray.train
# Enable importing from e2e_timeseries module.
import sys
sys.path.insert(0, os.path.abspath(os.path.join(os.getcwd(), os.pardir)))
import random
import tempfile
import time
import warnings
import numpy as np
import ray
from ray import train
from ray.train import Checkpoint, CheckpointConfig, RunConfig, ScalingConfig, get_dataset_shard
from ray.train.torch import TorchTrainer
import torch
import torch.nn as nn
from torch import optim
import e2e_timeseries
from e2e_timeseries.data_factory import data_provider
from e2e_timeseries.metrics import metric
from e2e_timeseries.model import DLinear
from e2e_timeseries.tools import adjust_learning_rate
warnings.filterwarnings("ignore")
Initialize the Ray cluster with the e2e_timeseries module, so that newly-spawned workers can import from it.
ray.init(runtime_env={"py_modules": [e2e_timeseries]})
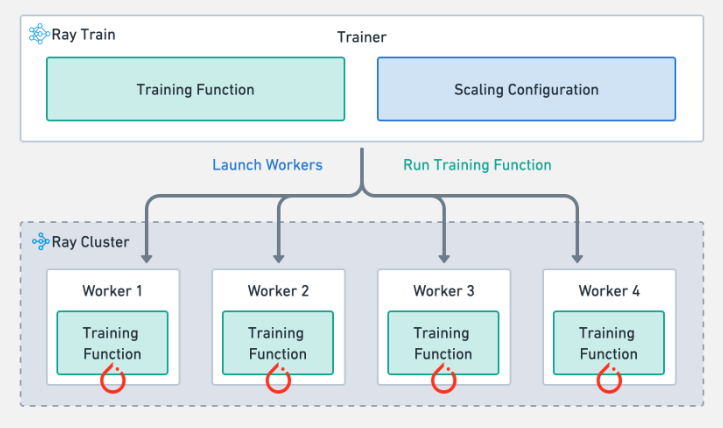
Anatomy of a Ray Train job#
Ray Train provides the Trainer abstraction, which handles the complexity of distributed training. The Trainer takes a few inputs:
Training function: The Python code that executes on each distributed training worker.
Train configuration: Contains the hyperparameters that the Trainer passes to the training function.
Scaling configuration: Defines the scaling behavior of the job and whether to use accelerators.
Run configuration: Controls checkpointing and specifies storage locations.
The Trainer then launches the workers across the Ray Cluster according to the scaling configuration and runs the training function on each worker.
The train configuration#
First, set up the training configuration for the trainable function:
config = {
# Basic config.
"train_only": False,
# Data loader args.
"num_data_workers": 10,
# Forecasting task type.
# S: univariate predict univariate
# M: multivariate predict univariate
# MS: multivariate predict multivariate
"features": "S",
"target": "OT", # Target variable name for prediction
# Forecasting task args.
"seq_len": 96,
"label_len": 48,
"pred_len": 96,
# DLinear-specific args.
"individual": False,
# Optimization args.
"num_replicas": 4,
"train_epochs": 10,
"batch_size": 32,
"learning_rate": 0.005,
"loss": "mse",
"lradj": "type1",
"use_amp": False,
# Other args.
"seed": 42,
}
# Dataset-specific args.
config["data"] = "ETTh1"
if config["features"] == "S": # S: univariate predict univariate
config["enc_in"] = 1
else: # M or MS
config["enc_in"] = 7 # ETTh1 has 7 features
Configuring persistent storage#
Next, configure the storage that the workers use to store checkpoints and artifacts. The storage needs to be accessible from all workers in the cluster. This storage can be S3, NFS, or another network-attached solution. Anyscale simplifies this process by automatically creating and mounting shared storage options on every cluster node, ensuring that model artifacts can are readable and writeable consistently across the distributed environment.
config["checkpoints"] = "/mnt/cluster_storage/checkpoints"
Note that passing large objects such as model weights and datasets through this configuration is an anti-pattern. Doing so can cause high serialization and deserialization overhead. Instead, it’s preferred to initialize these objects within the training function. Alternatively,
For the purposes of demonstration, enable smoke test mode.
config["smoke_test"] = True
if config["smoke_test"]:
print("--- RUNNING SMOKE TEST ---")
config["train_epochs"] = 2
config["batch_size"] = 2
config["num_data_workers"] = 1
Set up a training function#
The training function holds the model training logic which each distributed training worker executes. The TorchTrainer passes a configuration dictionary as input to the training function. Ray Train provides a few convenience functions for distributed training:
Automatically moving each model replica to the correct device.
Setting up the parallelization strategy (for example, distributed data parallel or fully sharded data parallel).
Setting up PyTorch data loaders for distributed execution, including auto-transfering objects to the correct device.
Reporting metrics and handling distributed checkpointing.
def train_loop_per_worker(config: dict):
"""Main training loop run on Ray Train workers."""
random.seed(config["seed"])
torch.manual_seed(config["seed"])
np.random.seed(config["seed"])
# Automatically determine device based on availability.
device = train.torch.get_device()
def _postprocess_preds_and_targets(raw_pred, batch_y, config):
pred_len = config["pred_len"]
f_dim_start_index = -1 if config["features"] == "MS" else 0
# Slice for prediction length first.
outputs_pred_len = raw_pred[:, -pred_len:, :]
batch_y_pred_len = batch_y[:, -pred_len:, :]
# Then slice for features.
final_pred = outputs_pred_len[:, :, f_dim_start_index:]
final_target = batch_y_pred_len[:, :, f_dim_start_index:]
return final_pred, final_target
# === Build Model ===
model = DLinear(config).float()
# Convenience function to move the model to the correct device and set up
# parallel strategy.
model = train.torch.prepare_model(model)
# === Get Data ===
train_ds = get_dataset_shard("train")
# === Optimizer and Criterion ===
model_optim = optim.Adam(model.parameters(), lr=config["learning_rate"])
criterion = nn.MSELoss()
# === AMP Scaler ===
scaler = None
if config["use_amp"]:
scaler = torch.amp.GradScaler("cuda")
# === Training Loop ===
for epoch in range(config["train_epochs"]):
model.train()
train_loss_epoch = []
epoch_start_time = time.time()
# Iterate over Ray Dataset batches. The dataset now yields dicts {'x': numpy_array, 'y': numpy_array}
# iter_torch_batches converts these to Torch tensors and move to device.
for batch in train_ds.iter_torch_batches(batch_size=config["batch_size"], device=device, dtypes=torch.float32):
model_optim.zero_grad()
x = batch["x"]
y = batch["y"]
# Forward pass
if config["use_amp"]:
with torch.amp.autocast("cuda"):
raw_preds = model(x)
predictions, targets = _postprocess_preds_and_targets(raw_preds, y, config)
loss = criterion(predictions, targets)
else:
raw_preds = model(x)
predictions, targets = _postprocess_preds_and_targets(raw_preds, y, config)
loss = criterion(predictions, targets)
train_loss_epoch.append(loss.item())
# Backward pass.
if config["use_amp"]:
scaler.scale(loss).backward()
scaler.step(model_optim)
scaler.update()
else:
loss.backward()
model_optim.step()
# === End of Epoch ===
epoch_train_loss = np.average(train_loss_epoch)
epoch_duration = time.time() - epoch_start_time
results_dict = {
"epoch": epoch + 1,
"train/loss": epoch_train_loss,
"epoch_duration_s": epoch_duration,
}
# === Validation ===
if not config["train_only"]:
val_ds = get_dataset_shard("val")
model.eval()
all_preds = []
all_trues = []
with torch.no_grad():
for batch in val_ds.iter_torch_batches(batch_size=config["batch_size"], device=device, dtypes=torch.float32):
x, y = batch["x"], batch["y"]
if config["use_amp"] and torch.cuda.is_available():
with torch.amp.autocast("cuda"):
raw_preds = model(x)
else:
raw_preds = model(x)
predictions, targets = _postprocess_preds_and_targets(raw_preds, y, config)
all_preds.append(predictions.detach().cpu().numpy())
all_trues.append(targets.detach().cpu().numpy())
all_preds = np.concatenate(all_preds, axis=0)
all_trues = np.concatenate(all_trues, axis=0)
mae, mse, rmse, mape, mspe, rse = metric(all_preds, all_trues)
results_dict["val/loss"] = mse
results_dict["val/mae"] = mae
results_dict["val/rmse"] = rmse
results_dict["val/mape"] = mape
results_dict["val/mspe"] = mspe
results_dict["val/rse"] = rse
print(f"Epoch {epoch + 1}: Train Loss: {epoch_train_loss:.7f}, Val Loss: {mse:.7f}, Val MSE: {mse:.7f} (Duration: {epoch_duration:.2f}s)")
# === Reporting and Checkpointing ===
if train.get_context().get_world_rank() == 0:
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
torch.save(
{
"epoch": epoch,
"model_state_dict": model.module.state_dict() if hasattr(model, "module") else model.state_dict(),
"optimizer_state_dict": model_optim.state_dict(),
"train_args": config,
},
os.path.join(temp_checkpoint_dir, "checkpoint.pt"),
)
checkpoint = Checkpoint.from_directory(temp_checkpoint_dir)
train.report(metrics=results_dict, checkpoint=checkpoint)
else:
train.report(metrics=results_dict, checkpoint=None)
adjust_learning_rate(model_optim, epoch + 1, config)
Ray Train Benefits:
Multi-node orchestration: Automatically handles multi-node, multi-GPU setup without manual SSH or hostfile configurations
Built-in fault tolerance: Supports automatic retry of failed workers and can continue from the last checkpoint
Flexible training strategies: Supports various parallelism strategies beyond just data parallel training
Heterogeneous cluster support: Define per-worker resource requirements and run on mixed hardware
Ray Train integrates with popular frameworks like PyTorch, TensorFlow, XGBoost, and more. For enterprise needs, RayTurbo Train offers additional features like elastic training, advanced monitoring, and performance optimization.

Set up the scaling config#
Next, set up the scaling configuration. This example assigns one model replica per GPU in the cluster.
scaling_config = ScalingConfig(num_workers=config["num_replicas"], use_gpu=True, resources_per_worker={"GPU": 1})
Checkpointing configuration#
Checkpointing enables you to resume training from the last checkpoint in case of interruptions or failures. Checkpointing is particularly useful for long-running training sessions. CheckpointConfig makes it easy to customize the checkpointing policy.
This example demonstrates how to keep a maximum of two model checkpoints based on their minimum validation loss score.
Note: Once you enable checkpointing, you can follow this guide to enable fault tolerance.
# Adjust run name during smoke tests.
run_name_prefix = "SmokeTest_" if config["smoke_test"] else ""
run_name = f"{run_name_prefix}DLinear_{config['data']}_{config['features']}_{config['target']}_{time.strftime('%Y%m%d_%H%M%S')}"
run_config = RunConfig(
storage_path=config["checkpoints"],
name=run_name,
checkpoint_config=CheckpointConfig(num_to_keep=2, checkpoint_score_attribute="val/loss", checkpoint_score_order="min"),
)
Datasets#
Ray Data is a library that enables distributed and streaming pre-processing of data. It’s possible to convert an existing PyTorch Dataset to a Ray Dataset using ray_ds = ray.data.from_torch(pytorch_ds).
To distribute the Ray Dataset to each training worker, pass the datasets as a dictionary to the datasets parameter. Later, calling get_dataset_shard() inside the training function automatically fetches a shard of the dataset assigned to that worker.
This tutorial uses the Electricity Transformer dataset (ETDataset), which measures the oil temperature of dozens of electrical stations in China over two years.
datasets = {"train": data_provider(config, flag="train")}
if not config["train_only"]:
datasets["val"] = data_provider(config, flag="val")
Because Ray Data lazily evaluates Ray Datasets, use show(1) to materialize a sample of the dataset:
datasets["train"].show(1)
In this tutorial, the training objective is to predict future oil temperatures y given a window of past oil temperatures x.
Executing .show(1) streams a single record through the pre-processing pipeline, standardizing the temperature column with zero-centered and unit-normalized values.
Next, combine all the inputs to initialize the TorchTrainer:
trainer = TorchTrainer(
train_loop_per_worker=train_loop_per_worker,
train_loop_config=config,
scaling_config=scaling_config,
run_config=run_config,
datasets=datasets,
)
Finally, execute training using the .fit() method:
# === Run Training ===
print("Starting Ray Train job...")
result = trainer.fit()
print("Training finished!")
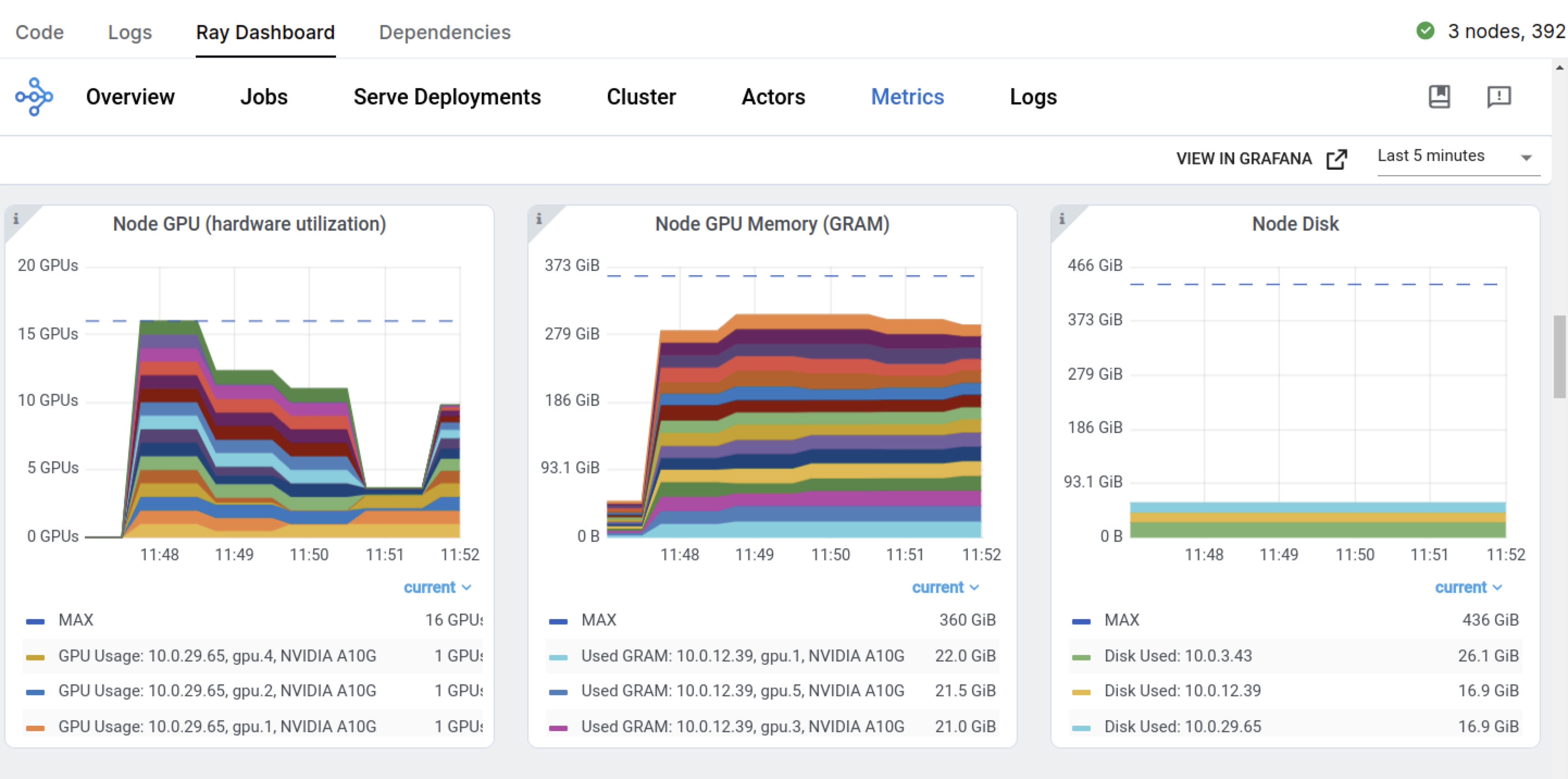
Observe that at the beginning of the training job, Ray immediately requests four GPU nodes defined in the ScalingConfig. Because you enabled “Auto-select worker nodes,” Anyscale automatically provisions any missing compute.
You can monitor the scaling behavior and cluster resource utilization on the Ray Dashboard:
The Ray Train job returns a ray.train.Result object, which contains important properties such as metrics, checkpoint info, and error details:
metrics = result.metrics
metrics
The metrics should look something like the following:
{'epoch': 2,
'train/loss': 0.33263104565833745,
'epoch_duration_s': 0.9015529155731201,
'val/loss': 0.296540230512619,
'val/mae': 0.4813770353794098,
'val/rmse': 0.544555075738551,
'val/mape': 9.20688533782959,
'val/mspe': 2256.628662109375,
'val/rse': 1.3782594203948975}
Now that the model has completed training, find the checkpoint with the lowest loss in the Result object.
# === Post-Training ===
if result.best_checkpoints:
best_checkpoint_path = None
if not config["train_only"] and "val/loss" in result.metrics_dataframe:
best_checkpoint = result.get_best_checkpoint(metric="val/loss", mode="min")
if best_checkpoint:
best_checkpoint_path = best_checkpoint.path
elif "train/loss" in result.metrics_dataframe: # Fallback or if train_only
best_checkpoint = result.get_best_checkpoint(metric="train/loss", mode="min")
if best_checkpoint:
best_checkpoint_path = best_checkpoint.path
if best_checkpoint_path:
print("Best checkpoint found:")
print(f" Directory: {best_checkpoint_path}")
best_checkpoint_metadata_fpath = os.path.join(
"/mnt/cluster_storage/checkpoints", "best_checkpoint_path.txt"
)
with open(best_checkpoint_metadata_fpath, "w") as f:
# Store the best checkpoint path in a file for later use
f.write(f"{best_checkpoint_path}/checkpoint.pt")
print("Train run metadata saved.")
else:
print("Could not retrieve the best checkpoint based on available metrics.")
else:
print("No checkpoints were saved during training.")