Environment Dependencies#
Your Ray application may have dependencies that exist outside of your Ray script. For example:
Your Ray script may import/depend on some Python packages.
Your Ray script may be looking for some specific environment variables to be available.
Your Ray script may import some files outside of the script.
One frequent problem when running on a cluster is that Ray expects these “dependencies” to exist on each Ray node. If these are not present, you may run into issues such as ModuleNotFoundError, FileNotFoundError and so on.
To address this problem, you can (1) prepare your dependencies on the cluster in advance (e.g. using a container image) using the Ray Cluster Launcher, or (2) use Ray’s runtime environments to install them on the fly.
For production usage or non-changing environments, we recommend installing your dependencies into a container image and specifying the image using the Cluster Launcher. For dynamic environments (e.g. for development and experimentation), we recommend using runtime environments.
Concepts#
Ray Application. A program including a Ray script that calls
ray.init()and uses Ray tasks or actors.Dependencies, or Environment. Anything outside of the Ray script that your application needs to run, including files, packages, and environment variables.
Files. Code files, data files or other files that your Ray application needs to run.
Packages. External libraries or executables required by your Ray application, often installed via
piporconda.Local machine and Cluster. Usually, you may want to separate the Ray cluster compute machines/pods from the machine/pod that handles and submits the application. You can submit a Ray Job via the Ray Job Submission mechanism, or use
ray attachto connect to a cluster interactively. We call the machine submitting the job your local machine.Job. A Ray job is a single application: it is the collection of Ray tasks, objects, and actors that originate from the same script.
Preparing an environment using the Ray Cluster launcher#
The first way to set up dependencies is to prepare a single environment across the cluster before starting the Ray runtime.
You can build all your files and dependencies into a container image and specify this in your Cluster YAML Configuration.
You can also install packages using
setup_commandsin the Ray Cluster configuration file (reference); these commands will be run as each node joins the cluster. Note that for production settings, it is recommended to build any necessary packages into a container image instead.You can push local files to the cluster using
ray rsync_up(reference).
Runtime environments#
Note
This feature requires a full installation of Ray using pip install "ray[default]". This feature is available starting with Ray 1.4.0 and is currently supported on macOS and Linux, with beta support on Windows.
The second way to set up dependencies is to install them dynamically while Ray is running.
A runtime environment describes the dependencies your Ray application needs to run, including files, packages, environment variables, and more. It is installed dynamically on the cluster at runtime and cached for future use (see Caching and Garbage Collection for details about the lifecycle).
Runtime environments can be used on top of the prepared environment from the Ray Cluster launcher if it was used.
For example, you can use the Cluster launcher to install a base set of packages, and then use runtime environments to install additional packages.
In contrast with the base cluster environment, a runtime environment will only be active for Ray processes. (For example, if using a runtime environment specifying a pip package my_pkg, the statement import my_pkg will fail if called outside of a Ray task, actor, or job.)
Runtime environments also allow you to set dependencies per-task, per-actor, and per-job on a long-running Ray cluster.
import ray
runtime_env = {"pip": ["emoji"]}
ray.init(runtime_env=runtime_env)
@ray.remote
def f():
import emoji
return emoji.emojize('Python is :thumbs_up:')
print(ray.get(f.remote()))
Python is 👍
A runtime environment can be described by a Python dict:
runtime_env = {
"pip": ["emoji"],
"env_vars": {"TF_WARNINGS": "none"}
}
Alternatively, you can use ray.runtime_env.RuntimeEnv:
from ray.runtime_env import RuntimeEnv
runtime_env = RuntimeEnv(
pip=["emoji"],
env_vars={"TF_WARNINGS": "none"}
)
For more examples, jump to the API Reference.
There are two primary scopes for which you can specify a runtime environment:
Specifying a Runtime Environment Per-Job#
You can specify a runtime environment for your whole job, whether running a script directly on the cluster, using the Ray Jobs API, or submitting a KubeRay RayJob:
# Option 1: Starting a single-node local Ray cluster or connecting to existing local cluster
ray.init(runtime_env=runtime_env)
# Option 2: Using Ray Jobs API (Python SDK)
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient("http://<head-node-ip>:8265")
job_id = client.submit_job(
entrypoint="python my_ray_script.py",
runtime_env=runtime_env,
)
# Option 3: Using Ray Jobs API (CLI). (Note: can use --runtime-env to pass a YAML file instead of an inline JSON string.)
$ ray job submit --address="http://<head-node-ip>:8265" --runtime-env-json='{"working_dir": "/data/my_files", "pip": ["emoji"]}' -- python my_ray_script.py
# Option 4: Using KubeRay RayJob. You can specify the runtime environment in the RayJob YAML manifest.
# [...]
spec:
runtimeEnvYAML: |
pip:
- requests==2.26.0
- pendulum==2.1.2
env_vars:
KEY: "VALUE"
Warning
Specifying the runtime_env argument in the submit_job or ray job submit call ensures the runtime environment is installed on the cluster before the entrypoint script is run.
If runtime_env is specified from ray.init(runtime_env=...), the runtime env is only applied to all children Tasks and Actors, not the entrypoint script (Driver) itself.
If runtime_env is specified by both ray job submit and ray.init, the runtime environments are merged. See Runtime Environment Specified by Both Job and Driver for more details.
Note
There are two options for when to install the runtime environment:
As soon as the job starts (i.e., as soon as
ray.init()is called), the dependencies are eagerly downloaded and installed.The dependencies are installed only when a task is invoked or an actor is created.
The default is option 1. To change the behavior to option 2, add "eager_install": False to the config of runtime_env.
Specifying a Runtime Environment Per-Task or Per-Actor#
You can specify different runtime environments per-actor or per-task using .options() or the @ray.remote decorator:
# Invoke a remote task that will run in a specified runtime environment.
f.options(runtime_env=runtime_env).remote()
# Instantiate an actor that will run in a specified runtime environment.
actor = SomeClass.options(runtime_env=runtime_env).remote()
# Specify a runtime environment in the task definition. Future invocations via
# `g.remote()` will use this runtime environment unless overridden by using
# `.options()` as above.
@ray.remote(runtime_env=runtime_env)
def g():
pass
# Specify a runtime environment in the actor definition. Future instantiations
# via `MyClass.remote()` will use this runtime environment unless overridden by
# using `.options()` as above.
@ray.remote(runtime_env=runtime_env)
class MyClass:
pass
This allows you to have actors and tasks running in their own environments, independent of the surrounding environment. (The surrounding environment could be the job’s runtime environment, or the system environment of the cluster.)
Warning
Ray does not guarantee compatibility between tasks and actors with conflicting runtime environments.
For example, if an actor whose runtime environment contains a pip package tries to communicate with an actor with a different version of that package, it can lead to unexpected behavior such as unpickling errors.
Common Workflows#
This section describes some common use cases for runtime environments. These use cases are not mutually exclusive; all of the options described below can be combined in a single runtime environment.
Using Local Files#
Your Ray application might depend on source files or data files. For a development workflow, these might live on your local machine, but when it comes time to run things at scale, you will need to get them to your remote cluster.
The following simple example explains how to get your local files on the cluster.
import os
import ray
os.makedirs("/tmp/runtime_env_working_dir", exist_ok=True)
with open("/tmp/runtime_env_working_dir/hello.txt", "w") as hello_file:
hello_file.write("Hello World!")
# Specify a runtime environment for the entire Ray job
ray.init(runtime_env={"working_dir": "/tmp/runtime_env_working_dir"})
# Create a Ray task, which inherits the above runtime env.
@ray.remote
def f():
# The function will have its working directory changed to its node's
# local copy of /tmp/runtime_env_working_dir.
return open("hello.txt").read()
print(ray.get(f.remote()))
Hello World!
Note
The example above is written to run on a local machine, but as for all of these examples, it also works when specifying a Ray cluster to connect to
(e.g., using ray.init("ray://123.456.7.89:10001", runtime_env=...) or ray.init(address="auto", runtime_env=...)).
The specified local directory will automatically be pushed to the cluster nodes when ray.init() is called.
You can also specify files via a remote cloud storage URI; see Remote URIs for details.
If you specify a working_dir, Ray always prepares it first, and it’s present in the creation of other runtime environments in the ${RAY_RUNTIME_ENV_CREATE_WORKING_DIR} environment variable. This sequencing allows pip and conda to reference local files in the working_dir like requirements.txt or environment.yml. See pip and conda sections in API Reference for more details.
Using conda or pip packages#
Your Ray application might depend on Python packages (for example, pendulum or requests) via import statements.
Ray ordinarily expects all imported packages to be preinstalled on every node of the cluster; in particular, these packages are not automatically shipped from your local machine to the cluster or downloaded from any repository.
However, using runtime environments you can dynamically specify packages to be automatically downloaded and installed in a virtual environment for your Ray job, or for specific Ray tasks or actors.
import ray
import requests
# This example runs on a local machine, but you can also do
# ray.init(address=..., runtime_env=...) to connect to a cluster.
ray.init(runtime_env={"pip": ["requests"]})
@ray.remote
def reqs():
return requests.get("https://www.ray.io/").status_code
print(ray.get(reqs.remote()))
200
You may also specify your pip dependencies either via a Python list or a local requirements.txt file.
Consider specifying a requirements.txt file when your pip install command requires options such as --extra-index-url or --find-links; see https://pip.pypa.io/en/stable/reference/requirements-file-format/# for details.
Alternatively, you can specify a conda environment, either as a Python dictionary or via a local environment.yml file. This conda environment can include pip packages.
For details, head to the API Reference.
Warning
Since the packages in the runtime_env are installed at runtime, be cautious when specifying conda or pip packages whose installations involve building from source, as this can be slow.
Note
When using the "pip" field, the specified packages will be installed “on top of” the base environment using virtualenv, so existing packages on your cluster will still be importable. By contrast, when using the conda field, your Ray tasks and actors will run in an isolated environment. The conda and pip fields cannot both be used in a single runtime_env.
Note
The ray[default] package itself will automatically be installed in the environment. For the conda field only, if you are using any other Ray libraries (for example, Ray Serve), then you will need to specify the library in the runtime environment (e.g. runtime_env = {"conda": {"dependencies": ["pytorch", "pip", {"pip": ["requests", "ray[serve]"]}]}}.)
Note
conda environments must have the same Python version as the Ray cluster. Do not list ray in the conda dependencies, as it will be automatically installed.
Using uv for package management#
The recommended approach for package management with uv in runtime environments is through uv run.
This method offers several key advantages:
First, it keeps dependencies synchronized between your driver and Ray workers.
Additionally, it provides full support for pyproject.toml including editable
packages. It also allows you to lock package versions using uv lock.
For more details, see the UV scripts documentation as
well as our blog post.
Create a file pyproject.toml in your working directory like the following:
[project]
name = "test"
version = "0.1"
dependencies = [
"emoji",
"ray",
]
And then a test.py like the following:
import emoji
import ray
@ray.remote
def f():
return emoji.emojize('Python is :thumbs_up:')
# Execute 1000 copies of f across a cluster.
print(ray.get([f.remote() for _ in range(1000)]))
and run the driver script with uv run test.py. This runs 1000 copies of
the f function across a number of Python worker processes in a Ray cluster.
The emoji dependency, in addition to being available for the main script, is
also available for all worker processes. Also, the source code in the current
working directory is available to all the workers.
This workflow also supports editable packages, for example, you can use
uv add --editable ./path/to/package where ./path/to/package
must be inside your current working directory so it’s available to all
workers.
See here
for an end-to-end example of how to use uv run to run a batch inference workload
with Ray Data.
Using uv in a Ray Job: With the same pyproject.toml and test.py files as above,
you can submit a Ray Job via
ray job submit --working-dir . -- uv run test.py
This command makes sure both the driver and workers of the job run in the uv environment as specified by your pyproject.toml.
Using uv with Ray Serve: With appropriate pyproject.toml and app.py files, you can
run a Ray Serve application with uv run serve run app:main.
Best Practices and Tips:
If you are running on a Ray Cluster, the Ray and Python versions of your uv environment must be the same as the Ray and Python versions of your cluster or you will get a version mismatch exception. There are multiple ways to solve this:
If you are using ephemeral Ray clusters, run the application on a cluster with the right versions.
If you need to run on a cluster with a different versions, consider modifying the versions of your uv environment by updating the
pyproject.tomlfile or by using the--activeflag withuv run(i.e.,uv run --active main.py).
Use
uv lockto generate a lockfile and make sure all your dependencies are frozen, so things won’t change in uncontrolled ways if a new version of a package gets released.If you have a requirements.txt file, you can use
uv add -r requirement.txtto add the dependencies to yourpyproject.tomland then use that with uv run.If your
pyproject.tomlis in some subdirectory, you can useuv run --projectto use it from there.If you use uv run and want to reset the working directory to something that isn’t the current working directory, use the
--directoryflag. The Ray uv integration makes sure yourworking_diris set accordingly.
Advanced use cases: Under the hood, the uv run support is implemented using a low level runtime environment
plugin called py_executable. It allows you to specify the Python executable (including arguments) that Ray workers will
be started in. In the case of uv, the py_executable is set to uv run with the same parameters that were used to run the
driver. Also, the working_dir runtime environment is used to propagate the working directory of the driver
(including the pyproject.toml) to the workers. This allows uv to set up the right dependencies and environment for the
workers to run in. There are some advanced use cases where you might want to use the py_executable mechanism directly in
your programs:
Applications with heterogeneous dependencies: Ray supports using a different runtime environment for different tasks or actors. This is useful for deploying different inference engines, models, or microservices in different Ray Serve deployments and also for heterogeneous data pipelines in Ray Data. To implement this, you can specify a different
py_executablefor each of the runtime environments and use uv run with a different--projectparameter for each. Instead, you can also use a differentworking_dirfor each environment.Customizing the command the worker runs in: On the workers, you might want to customize uv with some special arguments that aren’t used for the driver. Or, you might want to run processes using
poetry run, a build system like bazel, a profiler, or a debugger. In these cases, you can explicitly specify the executable the worker should run in viapy_executable. It could even be a shell script that is stored inworking_dirif you are trying to wrap multiple processes in more complex ways.
Note
The uv environment is inherited by all children tasks and actors. If you want to mix environments, for example, pip
runtime environments with uv run, you need to set the Python executable back to an executable
that’s not running in the isolated uv environment like the following:
[project]
name = "test"
version = "0.1"
dependencies = [
"emoji",
"ray",
"pip",
"virtualenv",
]
import ray
@ray.remote(runtime_env={"pip": ["wikipedia"], "py_executable": "python"})
def f():
import wikipedia
return wikipedia.summary("Wikipedia")
@ray.remote
def g():
import emoji
return emoji.emojize('Python is :thumbs_up:')
print(ray.get(f.remote()))
print(ray.get(g.remote()))
While the above pattern can be useful for supporting legacy applications, the Ray Team recommends
also using uv for tracking nested environments. You can use this approach by creating a separate
pyproject.toml containing the dependencies of the nested environment.
Library Development#
Suppose you are developing a library my_module on Ray.
A typical iteration cycle will involve
Making some changes to the source code of
my_moduleRunning a Ray script to test the changes, perhaps on a distributed cluster.
To ensure your local changes show up across all Ray workers and can be imported properly, use the py_modules field.
import ray
import my_module
ray.init("ray://123.456.7.89:10001", runtime_env={"py_modules": [my_module]})
@ray.remote
def test_my_module():
# No need to import my_module inside this function.
my_module.test()
ray.get(test_my_module.remote())
API Reference#
The runtime_env is a Python dictionary or a Python class ray.runtime_env.RuntimeEnv including one or more of the following fields:
working_dir(str): Specifies the working directory for the Ray workers. This must either be (1) a local existing directory with total size at most 500 MiB, (2) a local existing archive file (.zip,.tar.gz, or.tgz) with total uncompressed size at most 500 MiB (Note:excludeshas no effect), or (3) a URI to a remotely-stored archive (.zip,.tar.gz, or.tgz) containing the working directory for your job (no file size limit is enforced by Ray). See Remote URIs for details. The specified directory is downloaded to each node on the cluster, and Ray workers start in their node’s copy of this directory.Examples
"." # cwd"/src/my_project""/src/my_project.zip""s3://path/to/my_dir.zip""s3://path/to/my_dir.tar.gz"
Note: Setting a local directory per-task or per-actor is currently unsupported; it can only be set per-job (i.e., in
ray.init()).Note: By default, if the local directory contains a
.gitignoreand/or.rayignorefile, the specified files are not uploaded to the cluster. To disable the.gitignorefrom being considered, setRAY_RUNTIME_ENV_IGNORE_GITIGNORE=1on the machine doing the uploading.Note: By default, common directories (
.git,.venv,venv,__pycache__) are automatically excluded from theworking_dirupload. You can override these defaults by setting theRAY_OVERRIDE_RUNTIME_ENV_DEFAULT_EXCLUDESenvironment variable to a comma-separated list of patterns, or set it to an empty string to disable default excludes entirely.Note: If the local directory contains symbolic links, Ray follows the links and the files they point to are uploaded to the cluster.
py_modules(List[str|module]): Specifies Python modules to be available for import in the Ray workers. (For more ways to specify packages, see also thepipandcondafields below.) Each entry must be either (1) a path to a local file or directory, (2) a URI to a remote archive (.zip,.tar.gz,.tgz) or wheel (.whl) file (see Remote URIs for details), (3) a Python module object, or (4) a path to a local.whlfile.Examples of entries in the list:
".""/local_dependency/my_dir_module""/local_dependency/my_file_module.py""s3://bucket/my_module.zip"my_module # Assumes my_module has already been imported, e.g. via 'import my_module'my_module.whl"s3://bucket/my_module.whl"
The modules will be downloaded to each node on the cluster.
Note: Setting options (1), (3) and (4) per-task or per-actor is currently unsupported, it can only be set per-job (i.e., in
ray.init()).Note: For option (1), by default, if the local directory contains a
.gitignoreand/or.rayignorefile, the specified files are not uploaded to the cluster. To disable the.gitignorefrom being considered, setRAY_RUNTIME_ENV_IGNORE_GITIGNORE=1on the machine doing the uploading.py_executable(str): Specifies the executable used for running the Ray workers. It can include arguments as well. The executable can be located in theworking_dir. This runtime environment is useful to run workers in a custom debugger or profiler as well as to run workers in an environment set up by a package manager likeUV(see here).Note:
py_executableis new functionality and currently experimental. If you have some requirements or run into any problems, raise issues in github.excludes(List[str]): When used withworking_dirorpy_modules, specifies a list of files or paths to exclude from being uploaded to the cluster. This field uses the pattern-matching syntax used by.gitignorefiles: see https://git-scm.com/docs/gitignore for details. Note: In accordance with.gitignoresyntax, if there is a separator (/) at the beginning or middle (or both) of the pattern, then the pattern is interpreted relative to the level of theworking_dir. In particular, you shouldn’t use absolute paths (e.g./Users/my_working_dir/subdir/) withexcludes; rather, you should use the relative path/subdir/(written here with a leading/to match only the top-levelsubdirdirectory, rather than all directories namedsubdirat all levels.)Example:
{"working_dir": "/Users/my_working_dir/", "excludes": ["my_file.txt", "/subdir/", "path/to/dir", "*.log"]}
pip(dict | List[str] | str): Either (1) a list of pip requirements specifiers, (2) a string containing the path to a local pip “requirements.txt” file, or (3) a python dictionary that has three fields: (a)packages(required, List[str]): a list of pip packages, (b)pip_check(optional, bool): whether to enable pip check at the end of pip install, defaults toFalse. (c)pip_version(optional, str): the version of pip; Ray will spell the package name “pip” in front of thepip_versionto form the final requirement string. (d)pip_install_options(optional, List[str]): user-provided options forpip installcommand. Defaults to["--disable-pip-version-check", "--no-cache-dir"]. The syntax of a requirement specifier is defined in full in PEP 508. This will be installed in the Ray workers at runtime. Packages in the preinstalled cluster environment will still be available. To use a library like Ray Serve or Ray Tune, you will need to include"ray[serve]"or"ray[tune]"here. The Ray version must match that of the cluster.Example:
["requests==1.0.0", "aiohttp", "ray[serve]"]Example:
"./requirements.txt"Example:
{"packages":["tensorflow", "requests"], "pip_check": False, "pip_version": "==22.0.2;python_version=='3.8.11'"}
When specifying a path to a
requirements.txtfile, the file must be present on your local machine and it must be a valid absolute path or relative filepath relative to your local current working directory, not relative to theworking_dirspecified in theruntime_env. Furthermore, referencing local files within arequirements.txtfile isn’t directly supported (e.g.,-r ./my-laptop/more-requirements.txt,./my-pkg.whl). Instead, use the${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}environment variable in the creation process. For example, use-r ${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}/my-laptop/more-requirements.txtor${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}/my-pkg.whlto reference local files, while ensuring they’re in theworking_dir.uv(dict | List[str] | str): Alpha version feature. This plugin is theuv pipversion of thepipplugin above. If you are looking foruv runsupport withpyproject.tomlanduv.locksupport, use the uv run runtime environment plugin instead.Either (1) a list of uv requirements specifiers, (2) a string containing the path to a local uv “requirements.txt” file, or (3) a python dictionary that has three fields: (a)
packages(required, List[str]): a list of uv packages, (b)uv_version(optional, str): the version of uv; Ray will spell the package name “uv” in front of theuv_versionto form the final requirement string. (c)uv_check(optional, bool): whether to enable pip check at the end of uv install, default to False. (d)uv_pip_install_options(optional, List[str]): user-provided options foruv pip installcommand, default to["--no-cache"]. To override the default options and install without any options, use an empty list[]as install option value. The syntax of a requirement specifier is the same aspiprequirements. This will be installed in the Ray workers at runtime. Packages in the preinstalled cluster environment will still be available. To use a library like Ray Serve or Ray Tune, you will need to include"ray[serve]"or"ray[tune]"here. The Ray version must match that of the cluster.Example:
["requests==1.0.0", "aiohttp", "ray[serve]"]Example:
"./requirements.txt"Example:
{"packages":["tensorflow", "requests"], "uv_version": "==0.4.0;python_version=='3.8.11'"}
When specifying a path to a
requirements.txtfile, the file must be present on your local machine and it must be a valid absolute path or relative filepath relative to your local current working directory, not relative to theworking_dirspecified in theruntime_env. Furthermore, referencing local files within arequirements.txtfile isn’t directly supported (e.g.,-r ./my-laptop/more-requirements.txt,./my-pkg.whl). Instead, use the${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}environment variable in the creation process. For example, use-r ${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}/my-laptop/more-requirements.txtor${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}/my-pkg.whlto reference local files, while ensuring they’re in theworking_dir.conda(dict | str): Either (1) a dict representing the conda environment YAML, (2) a string containing the path to a local conda “environment.yml” file, or (3) the name of a local conda environment already installed on each node in your cluster (e.g.,"pytorch_p36") or its absolute path (e.g."/home/youruser/anaconda3/envs/pytorch_p36") . In the first two cases, the Ray and Python dependencies will be automatically injected into the environment to ensure compatibility, so there is no need to manually include them. The Python and Ray version must match that of the cluster, so you likely should not specify them manually. Note that thecondaandpipkeys ofruntime_envcannot both be specified at the same time—to use them together, please usecondaand add your pip dependencies in the"pip"field in your condaenvironment.yaml.Example:
{"dependencies": ["pytorch", "torchvision", "pip", {"pip": ["pendulum"]}]}Example:
"./environment.yml"Example:
"pytorch_p36"Example:
"/home/youruser/anaconda3/envs/pytorch_p36"
When specifying a path to a
environment.ymlfile, the file must be present on your local machine and it must be a valid absolute path or a relative filepath relative to your local current working directory, not relative to theworking_dirspecified in theruntime_env. Furthermore, referencing local files within aenvironment.ymlfile isn’t directly supported (e.g.,-r ./my-laptop/more-requirements.txt,./my-pkg.whl). Instead, use the${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}environment variable in the creation process. For example, use-r ${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}/my-laptop/more-requirements.txtor${RAY_RUNTIME_ENV_CREATE_WORKING_DIR}/my-pkg.whlto reference local files, while ensuring they’re in theworking_dir.env_vars(Dict[str, str]): Environment variables to set. Environment variables already set on the cluster will still be visible to the Ray workers; so there is no need to includeos.environor similar in theenv_varsfield. By default, these environment variables override the same name environment variables on the cluster. You can also reference existing environment variables using ${ENV_VAR} to achieve the appending behavior. If the environment variable doesn’t exist, it becomes an empty string"".Example:
{"OMP_NUM_THREADS": "32", "TF_WARNINGS": "none"}Example:
{"LD_LIBRARY_PATH": "${LD_LIBRARY_PATH}:/home/admin/my_lib"}Non-existent variable example:
{"ENV_VAR_NOT_EXIST": "${ENV_VAR_NOT_EXIST}:/home/admin/my_lib"}->ENV_VAR_NOT_EXIST=":/home/admin/my_lib".
nsight(Union[str, Dict[str, str]]): specifies the config for the Nsight System Profiler. The value is either (1) “default”, which refers to the default config, or (2) a dict of Nsight System Profiler options and their values. See here for more details on setup and usage.Example:
"default"Example:
{"stop-on-exit": "true", "t": "cuda,cublas,cudnn", "ftrace": ""}
image_uri(dict): Require a given Docker image. The worker process runs in a container with this image. - Example:{"image_uri": "anyscale/ray:2.53.0-py310-cpu"}Note:
image_uriis experimental. If you have some requirements or run into any problems, raise issues in github.config(dict |ray.runtime_env.RuntimeEnvConfig): config for runtime environment. Either a dict or a RuntimeEnvConfig. Fields: (1) setup_timeout_seconds, the timeout of runtime environment creation, timeout is in seconds.Example:
{"setup_timeout_seconds": 10}Example:
RuntimeEnvConfig(setup_timeout_seconds=10)
(2)
eager_install(bool): Indicates whether to install the runtime environment on the cluster atray.init()time, before the workers are leased. This flag is set toTrueby default. If set toFalse, the runtime environment will be only installed when the first task is invoked or when the first actor is created. Currently, specifying this option per-actor or per-task is not supported.Example:
{"eager_install": False}Example:
RuntimeEnvConfig(eager_install=False)
Caching and Garbage Collection#
Runtime environment resources on each node (such as conda environments, pip packages, or downloaded working_dir or py_modules directories) will be cached on the cluster to enable quick reuse across different runtime environments within a job. Each field (working_dir, py_modules, etc.) has its own cache whose size defaults to 10 GB. To change this default, you may set the environment variable RAY_RUNTIME_ENV_<field>_CACHE_SIZE_GB on each node in your cluster before starting Ray e.g. export RAY_RUNTIME_ENV_WORKING_DIR_CACHE_SIZE_GB=1.5.
When the cache size limit is exceeded, resources not currently used by any Actor, Task or Job are deleted.
Runtime Environment Specified by Both Job and Driver#
When running an entrypoint script (Driver), the runtime environment can be specified via ray.init(runtime_env=...) or ray job submit --runtime-env (See Specifying a Runtime Environment Per-Job for more details).
If the runtime environment is specified by
ray job submit --runtime-env=..., the runtime environments are applied to the entrypoint script (Driver) and all the tasks and actors created from it.If the runtime environment is specified by
ray.init(runtime_env=...), the runtime environments are applied to all the tasks and actors, but not the entrypoint script (Driver) itself.
Since ray job submit submits a Driver (that calls ray.init), sometimes runtime environments are specified by both of them. When both the Ray Job and Driver specify runtime environments, their runtime environments are merged if there’s no conflict.
It means the driver script uses the runtime environment specified by ray job submit, and all the tasks and actors are going to use the merged runtime environment.
Ray raises an exception if the runtime environments conflict.
The
runtime_env["env_vars"]ofray job submit --runtime-env=...is merged with theruntime_env["env_vars"]ofray.init(runtime_env=...). Note that each individual env_var keys are merged. If the environment variables conflict, Ray raises an exception.Every other field in the
runtime_envwill be merged. If any key conflicts, it raises an exception.
Example:
# `ray job submit --runtime_env=...`
{"pip": ["requests", "chess"],
"env_vars": {"A": "a", "B": "b"}}
# ray.init(runtime_env=...)
{"env_vars": {"C": "c"}}
# Driver's actual `runtime_env` (merged with Job's)
{"pip": ["requests", "chess"],
"env_vars": {"A": "a", "B": "b", "C": "c"}}
Conflict Example:
# Example 1, env_vars conflicts
# `ray job submit --runtime_env=...`
{"pip": ["requests", "chess"],
"env_vars": {"C": "a", "B": "b"}}
# ray.init(runtime_env=...)
{"env_vars": {"C": "c"}}
# Ray raises an exception because the "C" env var conflicts.
# Example 2, other field (e.g., pip) conflicts
# `ray job submit --runtime_env=...`
{"pip": ["requests", "chess"]}
# ray.init(runtime_env=...)
{"pip": ["torch"]}
# Ray raises an exception because "pip" conflicts.
You can set an environment variable RAY_OVERRIDE_JOB_RUNTIME_ENV=1
to avoid raising an exception upon a conflict. In this case, the runtime environments
are inherited in the same way as Driver and Task and Actor both specify
runtime environments, where ray job submit
is a parent and ray.init is a child.
Inheritance#
The runtime environment is inheritable, so it applies to all Tasks and Actors within a Job and all child Tasks and Actors of a Task or Actor once set, unless it is overridden.
If an Actor or Task specifies a new runtime_env, it overrides the parent’s runtime_env (i.e., the parent Actor’s or Task’s runtime_env, or the Job’s runtime_env if Actor or Task doesn’t have a parent) as follows:
The
runtime_env["env_vars"]field will be merged with theruntime_env["env_vars"]field of the parent. This allows for environment variables set in the parent’s runtime environment to be automatically propagated to the child, even if new environment variables are set in the child’s runtime environment.Every other field in the
runtime_envwill be overridden by the child, not merged. For example, ifruntime_env["py_modules"]is specified, it will replace theruntime_env["py_modules"]field of the parent.
Example:
# Parent's `runtime_env`
{"pip": ["requests", "chess"],
"env_vars": {"A": "a", "B": "b"}}
# Child's specified `runtime_env`
{"pip": ["torch", "ray[serve]"],
"env_vars": {"B": "new", "C": "c"}}
# Child's actual `runtime_env` (merged with parent's)
{"pip": ["torch", "ray[serve]"],
"env_vars": {"A": "a", "B": "new", "C": "c"}}
Frequently Asked Questions#
Are environments installed on every node?#
If a runtime environment is specified in ray.init(runtime_env=...), then the environment will be installed on every node. See Per-Job for more details.
(Note, by default the runtime environment will be installed eagerly on every node in the cluster. If you want to lazily install the runtime environment on demand, set the eager_install option to false: ray.init(runtime_env={..., "config": {"eager_install": False}}.)
When is the environment installed?#
When specified per-job, the environment is installed when you call ray.init() (unless "eager_install": False is set).
When specified per-task or per-actor, the environment is installed when the task is invoked or the actor is instantiated (i.e. when you call my_task.remote() or my_actor.remote().)
See Per-Job Per-Task/Actor, within a job for more details.
Where are the environments cached?#
Any local files downloaded by the environments are cached at /tmp/ray/session_latest/runtime_resources.
How long does it take to install or to load from cache?#
The install time usually mostly consists of the time it takes to run pip install or conda create / conda activate, or to upload/download a working_dir, depending on which runtime_env options you’re using.
This could take seconds or minutes.
On the other hand, loading a runtime environment from the cache should be nearly as fast as the ordinary Ray worker startup time, which is on the order of a few seconds. A new Ray worker is started for every Ray actor or task that requires a new runtime environment.
(Note that loading a cached conda environment could still be slow, since the conda activate command sometimes takes a few seconds.)
You can set setup_timeout_seconds config to avoid the installation hanging for a long time. If the installation is not finished within this time, your tasks or actors will fail to start.
What is the relationship between runtime environments and Docker?#
They can be used independently or together. A container image can be specified in the Cluster Launcher for large or static dependencies, and runtime environments can be specified per-job or per-task/actor for more dynamic use cases. The runtime environment will inherit packages, files, and environment variables from the container image.
My runtime_env was installed, but when I log into the node I can’t import the packages.#
The runtime environment is only active for the Ray worker processes; it does not install any packages “globally” on the node.
Remote URIs#
The working_dir and py_modules arguments in the runtime_env dictionary can specify either local path(s) or remote URI(s).
A local path must be a directory path. The directory’s contents will be directly accessed as the working_dir or a py_module.
A remote URI must be a link directly to a zip file or a wheel file (only for py_module). The zip file must contain only a single top-level directory.
The contents of this directory will be directly accessed as the working_dir or a py_module.
For example, suppose you want to use the contents in your local /some_path/example_dir directory as your working_dir.
If you want to specify this directory as a local path, your runtime_env dictionary should contain:
runtime_env = {..., "working_dir": "/some_path/example_dir", ...}
Suppose instead you want to host your files in your /some_path/example_dir directory remotely and provide a remote URI.
You need to first compress the example_dir directory into a .zip or .tar.gz archive.
There should be no other files or directories at the top level of the archive, other than example_dir.
You can use one of the following commands in the Terminal:
cd /some_path
# Using zip:
zip -r archive.zip example_dir
# Using tar.gz:
tar -czf archive.tar.gz example_dir
Run this command from the parent directory of the desired working_dir to ensure that the resulting archive contains a single top-level directory.
In general, the archive’s name and the top-level directory’s name can be anything.
The top-level directory’s contents are used as the working_dir (or py_module).
You can check that the archive contains a single top-level directory by running one of the following commands in the Terminal:
# For zip:
zipinfo -1 archive.zip
# For tar.gz:
tar -tzf archive.tar.gz
# example_dir/
# example_dir/my_file_1.txt
# example_dir/subdir/my_file_2.txt
Suppose you upload the compressed example_dir directory to AWS S3 at the S3 URI s3://example_bucket/example.zip.
Your runtime_env dictionary should contain:
runtime_env = {..., "working_dir": "s3://example_bucket/example.zip", ...}
You can also use .tar.gz or .tgz archives:
runtime_env = {..., "working_dir": "s3://example_bucket/example.tar.gz", ...}
Warning
Check for hidden files and metadata directories in archived dependencies.
You can inspect an archive’s contents by running zipinfo -1 archive.zip or tar -tzf archive.tar.gz in the Terminal.
Some archiving methods can cause hidden files or metadata directories to appear at the top level.
To avoid this, use zip -r or tar -czf directly on the directory you want to compress from its parent’s directory. For example, if you have a directory structure such as: a/b and you want to compress b, issue the command from the directory a.
If Ray detects more than a single directory at the top level, it uses the entire archive instead of the top-level directory, which may lead to unexpected behavior.
Remote URIs support .zip, .tar.gz, and .tgz archive formats. Four types of remote URIs are supported for hosting working_dir and py_modules packages:
HTTPS:HTTPSrefers to URLs that start withhttps. These are particularly useful because remote Git providers (e.g. GitHub, Bitbucket, GitLab, etc.) usehttpsURLs as download links for repository archives. This allows you to host your dependencies on remote Git providers, push updates to them, and specify which dependency versions (i.e. commits) your jobs should use. To use packages viaHTTPSURIs, you must have thesmart_openlibrary (you can install it usingpip install smart_open).Example:
runtime_env = {"working_dir": "https://github.com/example_username/example_repository/archive/HEAD.zip"}
S3:S3refers to URIs starting withs3://that point to compressed packages stored in AWS S3. To use packages viaS3URIs, you must have thesmart_openandboto3libraries (you can install them usingpip install smart_openandpip install boto3). Ray does not explicitly pass in any credentials toboto3for authentication.boto3will use your environment variables, shared credentials file, and/or AWS config file to authenticate access. See the AWS boto3 documentation to learn how to configure these.Example:
runtime_env = {"working_dir": "s3://example_bucket/example_file.zip"}
GS:GSrefers to URIs starting withgs://that point to compressed packages stored in Google Cloud Storage. To use packages viaGSURIs, you must have thesmart_openandgoogle-cloud-storagelibraries (you can install them usingpip install smart_openandpip install google-cloud-storage). Ray does not explicitly pass in any credentials to thegoogle-cloud-storage’sClientobject.google-cloud-storagewill use your local service account key(s) and environment variables by default. Follow the steps on Google Cloud Storage’s Getting started with authentication guide to set up your credentials, which allow Ray to access your remote package.Example:
runtime_env = {"working_dir": "gs://example_bucket/example_file.zip"}
Azure:Azurerefers to URIs starting withazure://that point to compressed packages stored in Azure Blob Storage. To use packages viaAzureURIs, you must have thesmart_open,azure-storage-blob, andazure-identitylibraries (you can install them usingpip install smart_open[azure] azure-storage-blob azure-identity). Ray supports two authentication methods for Azure Blob Storage:Connection string: Set the environment variable
AZURE_STORAGE_CONNECTION_STRINGwith your Azure storage connection string.Managed Identity: Set the environment variable
AZURE_STORAGE_ACCOUNTwith your Azure storage account name. This will use Azure’s Managed Identity for authentication.
Example:
runtime_env = {"working_dir": "azure://container-name/example_file.zip"}
Note that the smart_open, boto3, google-cloud-storage, azure-storage-blob, and azure-identity packages are not installed by default, and it is not sufficient to specify them in the pip section of your runtime_env.
The relevant packages must already be installed on all nodes of the cluster when Ray starts.
Hosting a Dependency on a Remote Git Provider: Step-by-Step Guide#
You can store your dependencies in repositories on a remote Git provider (e.g. GitHub, Bitbucket, GitLab, etc.), and you can periodically push changes to keep them updated. In this section, you will learn how to store a dependency on GitHub and use it in your runtime environment.
Note
These steps will also be useful if you use another large, remote Git provider (e.g. BitBucket, GitLab, etc.). For simplicity, this section refers to GitHub alone, but you can follow along on your provider.
First, create a repository on GitHub to store your working_dir contents or your py_module dependency.
By default, when you download a zip file of your repository, the zip file will already contain a single top-level directory that holds the repository contents,
so you can directly upload your working_dir contents or your py_module dependency to the GitHub repository.
Once you have uploaded your working_dir contents or your py_module dependency, you need the HTTPS URL of the repository zip file, so you can specify it in your runtime_env dictionary.
You have two options to get the HTTPS URL.
Option 1: Download Zip (quicker to implement, but not recommended for production environments)#
The first option is to use the remote Git provider’s “Download Zip” feature, which provides an HTTPS link that zips and downloads your repository. This is quick, but it is not recommended because it only allows you to download a zip file of a repository branch’s latest commit. To find a GitHub URL, navigate to your repository on GitHub, choose a branch, and click on the green “Code” drop down button:
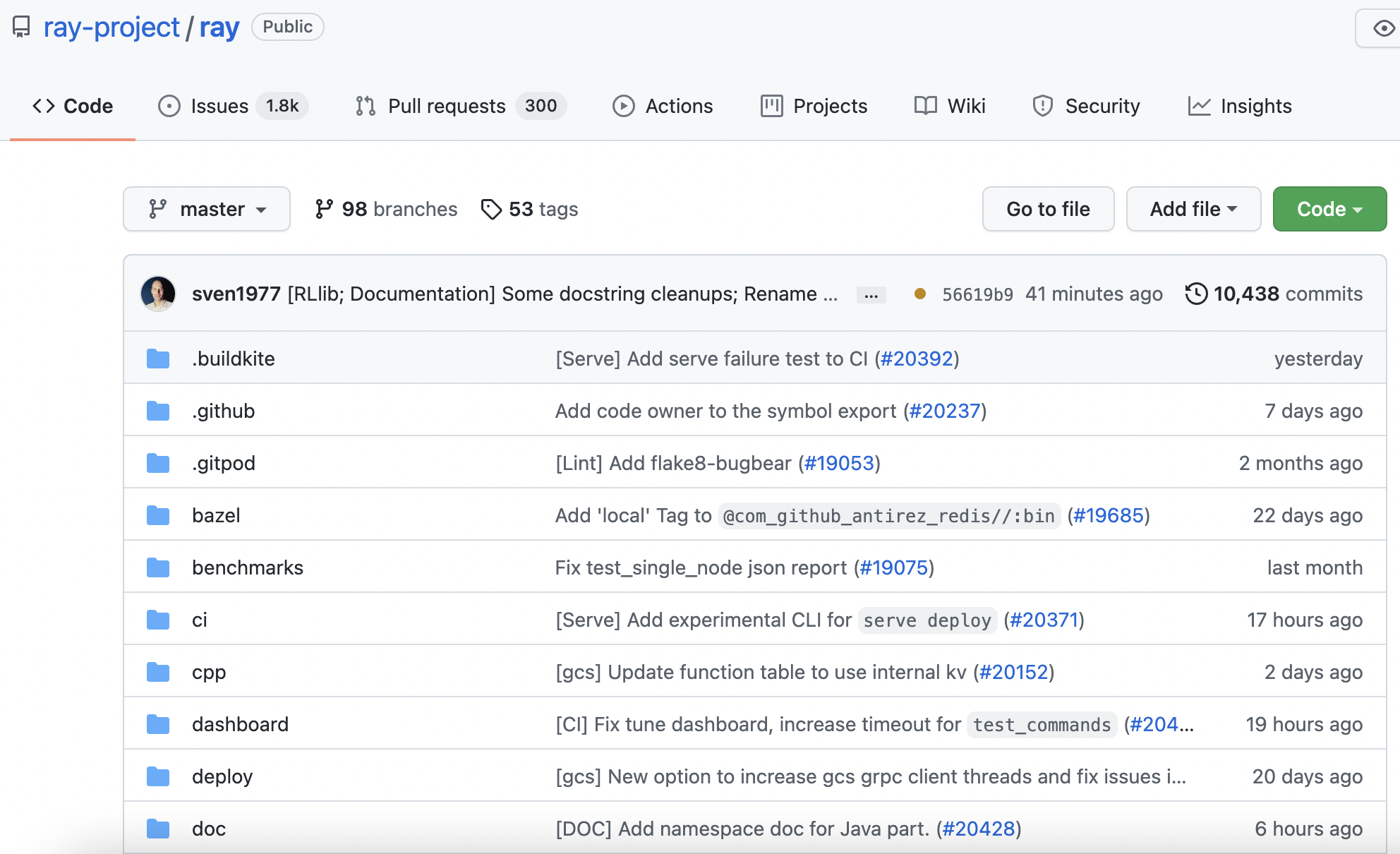
This will drop down a menu that provides three options: “Clone” which provides HTTPS/SSH links to clone the repository, “Open with GitHub Desktop”, and “Download ZIP.” Right-click on “Download Zip.” This will open a pop-up near your cursor. Select “Copy Link Address”:
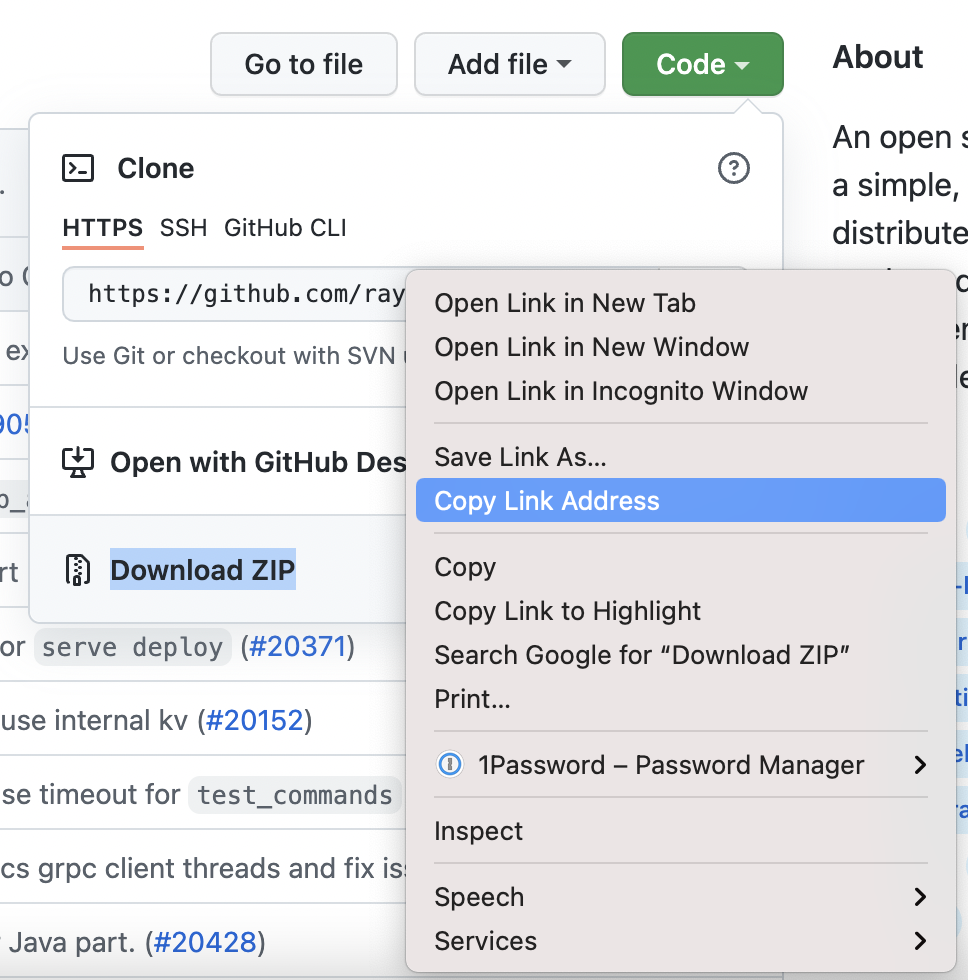
Now your HTTPS link is copied to your clipboard. You can paste it into your runtime_env dictionary.
Warning
Using the HTTPS URL from your Git provider’s “Download as Zip” feature is not recommended if the URL always points to the latest commit. For instance, using this method on GitHub generates a link that always points to the latest commit on the chosen branch.
By specifying this link in the runtime_env dictionary, your Ray Cluster always uses the chosen branch’s latest commit.
This creates a consistency risk: if you push an update to your remote Git repository while your cluster’s nodes are pulling the repository’s contents,
some nodes may pull the version of your package just before you pushed, and some nodes may pull the version just after.
For consistency, it is better to specify a particular commit, so all the nodes use the same package.
See “Option 2: Manually Create URL” to create a URL pointing to a specific commit.
Option 2: Manually Create URL (slower to implement, but recommended for production environments)#
The second option is to manually create this URL by pattern-matching your specific use case with one of the following examples.
This is recommended because it provides finer-grained control over which repository branch and commit to use when generating your dependency zip file.
These options prevent consistency issues on Ray Clusters (see the warning above for more info).
To create the URL, pick a URL template below that fits your use case, and fill in all parameters in brackets (e.g. [username], [repository], etc.) with the specific values from your repository.
For instance, suppose your GitHub username is example_user, the repository’s name is example_repository, and the desired commit hash is abcdefg.
If example_repository is public and you want to retrieve the abcdefg commit (which matches the first example use case), the URL would be:
runtime_env = {"working_dir": ("https://github.com"
"/example_user/example_repository/archive/abcdefg.zip")}
Here is a list of different use cases and corresponding URLs:
Example: Retrieve package from a specific commit hash on a public GitHub repository
runtime_env = {"working_dir": ("https://github.com"
"/[username]/[repository]/archive/[commit hash].zip")}
Example: Retrieve package from a private GitHub repository using a Personal Access Token during development. For production see this document to learn how to authenticate private dependencies safely.
runtime_env = {"working_dir": ("https://[username]:[personal access token]@github.com"
"/[username]/[private repository]/archive/[commit hash].zip")}
Example: Retrieve package from a public GitHub repository’s latest commit
runtime_env = {"working_dir": ("https://github.com"
"/[username]/[repository]/archive/HEAD.zip")}
Example: Retrieve package from a specific commit hash on a public Bitbucket repository
runtime_env = {"working_dir": ("https://bitbucket.org"
"/[owner]/[repository]/get/[commit hash].tar.gz")}
Tip
It is recommended to specify a particular commit instead of always using the latest commit. This prevents consistency issues on a multi-node Ray Cluster. See the warning below “Option 1: Download Zip” for more info.
Once you have specified the URL in your runtime_env dictionary, you can pass the dictionary
into a ray.init() or .options() call. Congratulations! You have now hosted a runtime_env dependency
remotely on GitHub!
Debugging#
If runtime_env cannot be set up (e.g., network issues, download failures, etc.), Ray will fail to schedule tasks/actors
that require the runtime_env. If you call ray.get, it will raise RuntimeEnvSetupError with
the error message in detail.
import ray
import time
@ray.remote
def f():
pass
@ray.remote
class A:
def f(self):
pass
start = time.time()
bad_env = {"conda": {"dependencies": ["this_doesnt_exist"]}}
# [Tasks] will raise `RuntimeEnvSetupError`.
try:
ray.get(f.options(runtime_env=bad_env).remote())
except ray.exceptions.RuntimeEnvSetupError:
print("Task fails with RuntimeEnvSetupError")
# [Actors] will raise `RuntimeEnvSetupError`.
a = A.options(runtime_env=bad_env).remote()
try:
ray.get(a.f.remote())
except ray.exceptions.RuntimeEnvSetupError:
print("Actor fails with RuntimeEnvSetupError")
Task fails with RuntimeEnvSetupError
Actor fails with RuntimeEnvSetupError
Full logs can always be found in the file runtime_env_setup-[job_id].log for per-actor, per-task and per-job environments, or in
runtime_env_setup-ray_client_server_[port].log for per-job environments when using Ray Client.
You can also enable runtime_env debugging log streaming by setting an environment variable RAY_RUNTIME_ENV_LOG_TO_DRIVER_ENABLED=1 on each node before starting Ray, for example using setup_commands in the Ray Cluster configuration file (reference).
This will print the full runtime_env setup log messages to the driver (the script that calls ray.init()).
Example log output:
ray.init(runtime_env={"pip": ["requests"]})
(pid=runtime_env) 2022-02-28 14:12:33,653 INFO pip.py:188 -- Creating virtualenv at /tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv, current python dir /Users/user/anaconda3/envs/ray-py38
(pid=runtime_env) 2022-02-28 14:12:33,653 INFO utils.py:76 -- Run cmd[1] ['/Users/user/anaconda3/envs/ray-py38/bin/python', '-m', 'virtualenv', '--app-data', '/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv_app_data', '--reset-app-data', '--no-periodic-update', '--system-site-packages', '--no-download', '/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv']
(pid=runtime_env) 2022-02-28 14:12:34,267 INFO utils.py:97 -- Output of cmd[1]: created virtual environment CPython3.8.11.final.0-64 in 473ms
(pid=runtime_env) creator CPython3Posix(dest=/private/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv, clear=False, no_vcs_ignore=False, global=True)
(pid=runtime_env) seeder FromAppData(download=False, pip=bundle, setuptools=bundle, wheel=bundle, via=copy, app_data_dir=/private/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv_app_data)
(pid=runtime_env) added seed packages: pip==22.0.3, setuptools==60.6.0, wheel==0.37.1
(pid=runtime_env) activators BashActivator,CShellActivator,FishActivator,NushellActivator,PowerShellActivator,PythonActivator
(pid=runtime_env)
(pid=runtime_env) 2022-02-28 14:12:34,268 INFO utils.py:76 -- Run cmd[2] ['/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv/bin/python', '-c', 'import ray; print(ray.__version__, ray.__path__[0])']
(pid=runtime_env) 2022-02-28 14:12:35,118 INFO utils.py:97 -- Output of cmd[2]: 3.0.0.dev0 /Users/user/ray/python/ray
(pid=runtime_env)
(pid=runtime_env) 2022-02-28 14:12:35,120 INFO pip.py:236 -- Installing python requirements to /tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv
(pid=runtime_env) 2022-02-28 14:12:35,122 INFO utils.py:76 -- Run cmd[3] ['/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv/bin/python', '-m', 'pip', 'install', '--disable-pip-version-check', '--no-cache-dir', '-r', '/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/requirements.txt']
(pid=runtime_env) 2022-02-28 14:12:38,000 INFO utils.py:97 -- Output of cmd[3]: Requirement already satisfied: requests in /Users/user/anaconda3/envs/ray-py38/lib/python3.8/site-packages (from -r /tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/requirements.txt (line 1)) (2.26.0)
(pid=runtime_env) Requirement already satisfied: idna<4,>=2.5 in /Users/user/anaconda3/envs/ray-py38/lib/python3.8/site-packages (from requests->-r /tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/requirements.txt (line 1)) (3.2)
(pid=runtime_env) Requirement already satisfied: certifi>=2017.4.17 in /Users/user/anaconda3/envs/ray-py38/lib/python3.8/site-packages (from requests->-r /tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/requirements.txt (line 1)) (2021.10.8)
(pid=runtime_env) Requirement already satisfied: urllib3<1.27,>=1.21.1 in /Users/user/anaconda3/envs/ray-py38/lib/python3.8/site-packages (from requests->-r /tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/requirements.txt (line 1)) (1.26.7)
(pid=runtime_env) Requirement already satisfied: charset-normalizer~=2.0.0 in /Users/user/anaconda3/envs/ray-py38/lib/python3.8/site-packages (from requests->-r /tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/requirements.txt (line 1)) (2.0.6)
(pid=runtime_env)
(pid=runtime_env) 2022-02-28 14:12:38,001 INFO utils.py:76 -- Run cmd[4] ['/tmp/ray/session_2022-02-28_14-12-29_909064_87908/runtime_resources/pip/0cc818a054853c3841171109300436cad4dcf594/virtualenv/bin/python', '-c', 'import ray; print(ray.__version__, ray.__path__[0])']
(pid=runtime_env) 2022-02-28 14:12:38,804 INFO utils.py:97 -- Output of cmd[4]: 3.0.0.dev0 /Users/user/ray/python/ray
See Logging Directory Structure for more details.