Key Concepts#
This page introduces key concepts for Ray clusters:
Ray Cluster#
A Ray cluster consists of a single head node and any number of connected worker nodes:

A Ray cluster with two worker nodes. Each node runs Ray helper processes to facilitate distributed scheduling and memory management. The head node runs additional control processes (highlighted in blue).#
The number of worker nodes may be autoscaled with application demand as specified by your Ray cluster configuration. The head node runs the autoscaler.
Note
Ray nodes are implemented as pods when running on Kubernetes.
Users can submit jobs for execution on the Ray cluster, or can interactively use the
cluster by connecting to the head node and running ray.init. See
Ray Jobs for more information.
Head Node#
Every Ray cluster has one node which is designated as the head node of the cluster. The head node is identical to other worker nodes, except that it also runs singleton processes responsible for cluster management such as the autoscaler, GCS and the Ray driver processes which run Ray jobs. Ray may schedule tasks and actors on the head node just like any other worker node, which is not desired in large-scale clusters. See Configuring the head node for the best practice in large-scale clusters.
Worker Node#
Worker nodes do not run any head node management processes, and serve only to run user code in Ray tasks and actors. They participate in distributed scheduling, as well as the storage and distribution of Ray objects in cluster memory.
Autoscaler#
The Ray autoscaler is a process that runs on the head node (or as a sidecar container in the head pod if using Kubernetes). When the resource demands of the Ray workload exceed the current capacity of the cluster, the autoscaler will try to increase the number of worker nodes. When worker nodes sit idle, the autoscaler will remove worker nodes from the cluster.
It is important to understand that the autoscaler only reacts to task and actor resource requests, and not application metrics or physical resource utilization. To learn more about autoscaling, refer to the user guides for Ray clusters on VMs and Kubernetes.
Note
Version 2.10.0 introduces the alpha release of Autoscaling V2 on KubeRay. Discover the enhancements and configuration details here.
Ray Jobs#
A Ray job is a single application: it is the collection of Ray tasks, objects, and actors that originate from the same script. The worker that runs the Python script is known as the driver of the job.
There are two ways to run a Ray job on a Ray cluster:
(Recommended) Submit the job using the Ray Jobs API.
Run the driver script directly on the Ray cluster, for interactive development.
For details on these workflows, refer to the Ray Jobs API guide.
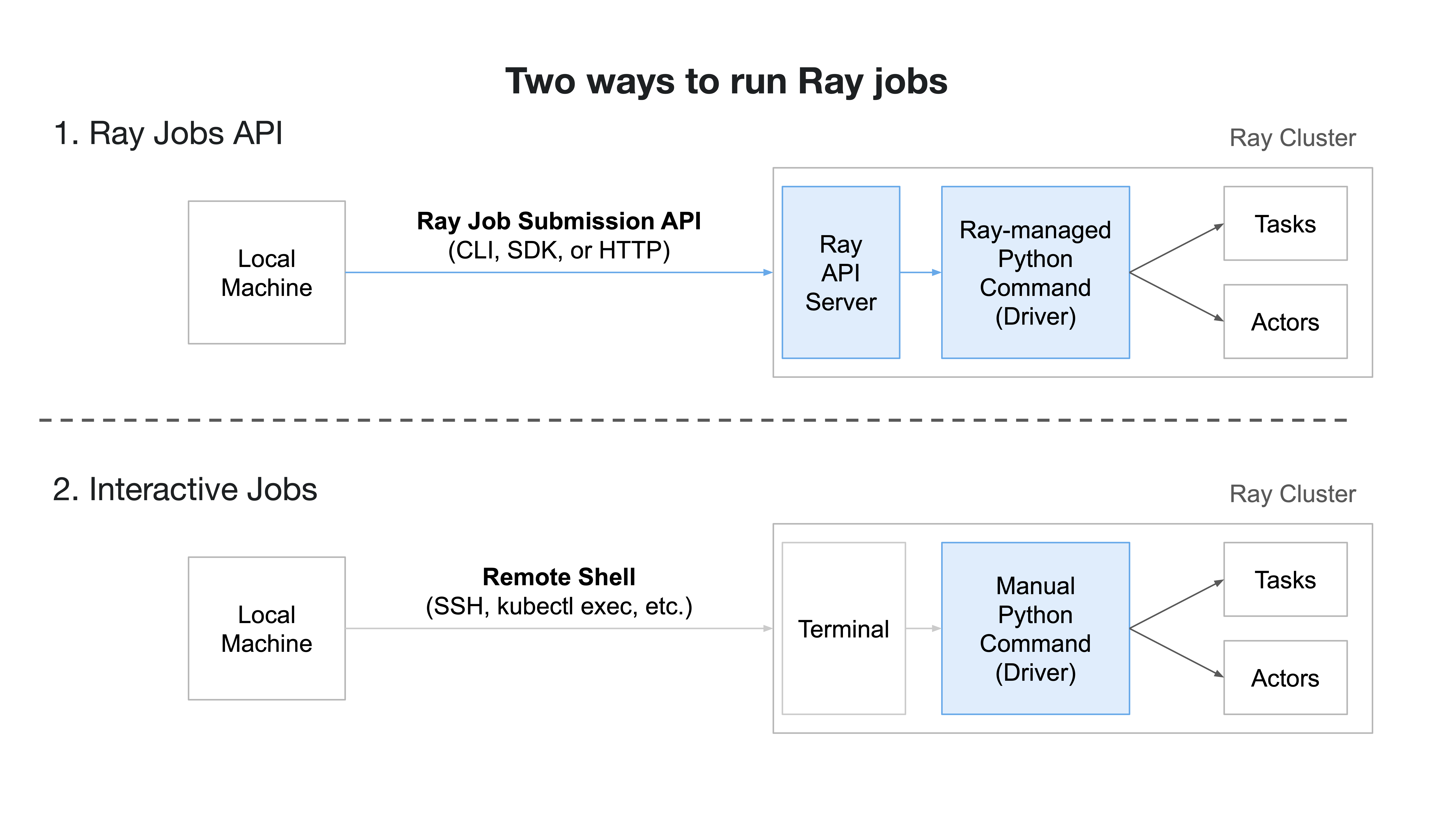
Two ways of running a job on a Ray cluster.#