Advanced Ray Serve Autoscaling#
This guide goes over more advanced autoscaling parameters in autoscaling_config and an advanced model composition example.
Autoscaling config parameters#
In this section, we go into more detail about Serve autoscaling concepts as well as how to set your autoscaling config.
[Required] Define the steady state of your system#
To define what the steady state of your deployments should be, set values for target_ongoing_requests and max_ongoing_requests.
target_ongoing_requests [default=2]#
Note
The default for target_ongoing_requests changed from 1.0 to 2.0 in Ray 2.32.0. You can continue to set it manually to override the default.
Serve scales the number of replicas for a deployment up or down based on the average number of ongoing requests per replica. Specifically, Serve compares the actual number of ongoing requests per replica with the target value you set in the autoscaling config and makes upscale or downscale decisions from that. Set the target value with target_ongoing_requests, and Serve attempts to ensure that each replica has roughly that number of requests being processed and waiting in the queue.
Always load test your workloads. For example, if the use case is latency sensitive, you can lower the target_ongoing_requests number to maintain high performance. Benchmark your application code and set this number based on an end-to-end latency objective.
Note
As an example, suppose you have two replicas of a synchronous deployment that has 100ms latency, serving a traffic load of 30 QPS. Then Serve assigns requests to replicas faster than the replicas can finish processing them; more and more requests queue up at the replica (these requests are “ongoing requests”) as time progresses, and then the average number of ongoing requests at each replica steadily increases. Latency also increases because new requests have to wait for old requests to finish processing. If you set target_ongoing_requests = 1, Serve detects a higher than desired number of ongoing requests per replica, and adds more replicas. At 3 replicas, your system would be able to process 30 QPS with 1 ongoing request per replica on average.
max_ongoing_requests [default=5]#
Note
The default for max_ongoing_requests changed from 100 to 5 in Ray 2.32.0. You can continue to set it manually to override the default.
There is also a maximum queue limit that proxies respect when assigning requests to replicas. Define the limit with max_ongoing_requests. Set max_ongoing_requests to ~20 to 50% higher than target_ongoing_requests.
Setting it too low can throttle throughput. Instead of being forwarded to replicas for concurrent execution, requests will tend to queue up at the proxy, waiting for replicas to finish processing existing requests.
Note
max_ongoing_requests should be tuned higher especially for lightweight requests, else the overall throughput will be impacted.
Setting it too high can lead to imbalanced routing. Concretely, this can lead to very high tail latencies during upscale, because when the autoscaler is scaling a deployment up due to a traffic spike, most or all of the requests might be assigned to the existing replicas before the new replicas are started.
[Required] Define upper and lower autoscaling limits#
To use autoscaling, you need to define the minimum and maximum number of resources allowed for your system.
min_replicas[default=1]: This is the minimum number of replicas for the deployment. If you want to ensure your system can deal with a certain level of traffic at all times, setmin_replicasto a positive number. On the other hand, if you anticipate periods of no traffic and want to scale to zero to save cost, setmin_replicas = 0. Note that settingmin_replicas = 0causes higher tail latencies; when you start sending traffic, the deployment scales up, and there will be a cold start time as Serve waits for replicas to be started to serve the request.max_replicas[default=1]: This is the maximum number of replicas for the deployment. This should be greater thanmin_replicas. Ray Serve Autoscaling relies on the Ray Autoscaler to scale up more nodes when the currently available cluster resources (CPUs, GPUs, etc.) are not enough to support more replicas.initial_replicas: This is the number of replicas that are started initially for the deployment. This defaults to the value formin_replicas.
[Optional] Define how the system reacts to changing traffic#
Given a steady stream of traffic and appropriately configured min_replicas and max_replicas, the steady state of your system is essentially fixed for a chosen configuration value for target_ongoing_requests. Before reaching steady state, however, your system is reacting to traffic shifts. How you want your system to react to changes in traffic determines how you want to set the remaining autoscaling configurations.
upscale_delay_s[default=30s]: This defines how long Serve waits before scaling up the number of replicas in your deployment. In other words, this parameter controls the frequency of upscale decisions. If the replicas are consistently serving more requests than desired for anupscale_delay_snumber of seconds, then Serve scales up the number of replicas based on aggregated ongoing requests metrics. For example, if your service is likely to experience bursts of traffic, you can lowerupscale_delay_sso that your application can react quickly to increases in traffic.
Ray Serve allows you to use different delays for different downscaling scenarios, providing more granular control over when replicas are removed. This is particularly useful when you want different behavior for scaling down to zero versus scaling down to a non-zero number of replicas.
downscale_delay_s[default=600s]: This defines how long Serve waits before scaling down the number of replicas in your deployment. If the replicas are consistently serving fewer requests than desired for adownscale_delay_snumber of seconds, Serve scales down the number of replicas based on aggregated ongoing requests metrics. This delay applies to all downscaling decisions except for the optional 1→0 transition (see below). For example, if your application initializes slowly, you can increasedownscale_delay_sto make downscaling happen more infrequently and avoid reinitialization costs when the application needs to upscale again.downscale_to_zero_delay_s[Optional]: This defines how long Serve waits before scaling from one replica down to zero (only applies whenmin_replicas = 0). If not specified, the 1→0 transition uses thedownscale_delay_svalue. This is useful when you want more conservative scale-to-zero behavior. For example, you might setdownscale_delay_s = 300for regular downscaling butdownscale_to_zero_delay_s = 1800to wait 30 minutes before scaling to zero, avoiding cold starts for brief periods of inactivity.upscale_smoothing_factor[default_value=1.0] (DEPRECATED): This parameter is renamed toupscaling_factor.upscale_smoothing_factorwill be removed in a future release.downscale_smoothing_factor[default_value=1.0] (DEPRECATED): This parameter is renamed todownscaling_factor.downscale_smoothing_factorwill be removed in a future release.upscaling_factor[default_value=1.0]: The multiplicative factor to amplify or moderate each upscaling decision. For example, when the application has high traffic volume in a short period of time, you can increaseupscaling_factorto scale up the resource quickly. This parameter is like a “gain” factor to amplify the response of the autoscaling algorithm.downscaling_factor[default_value=1.0]: The multiplicative factor to amplify or moderate each downscaling decision. For example, if you want your application to be less sensitive to drops in traffic and scale down more conservatively, you can decreasedownscaling_factorto slow down the pace of downscaling.metrics_interval_s[default_value=10]: In future this deployment level config will be removed in favor of cross-application level global config.
This controls how often each replica and handle sends reports on current ongoing requests to the autoscaler. ::{note} If metrics are reported infrequently, Ray Serve can take longer to notice a change in autoscaling metrics, so scaling can start later even if your delays are short. For example, if you set upscale_delay_s = 3 but metrics are pushed every 10 seconds, Ray Serve might not see a change until the next push, so scaling up can be limited to about once every 10 seconds. ::
look_back_period_s[default_value=30]: This is the window over which the average number of ongoing requests per replica is calculated.aggregation_function[default_value=“mean”]: This controls how metrics are aggregated over thelook_back_period_stime window. The aggregation function determines how Ray Serve combines multiple metric measurements into a single value for autoscaling decisions. Supported values:"mean"(default): Uses time-weighted average of metrics. This provides smooth scaling behavior that responds to sustained traffic patterns."max": Uses the maximum metric value observed. This makes autoscaling more sensitive to spikes, scaling up quickly when any replica experiences high load."min": Uses the minimum metric value observed. This results in more conservative scaling behavior.
For most workloads, the default "mean" aggregation provides the best balance. Use "max" if you need to react quickly to traffic spikes, or "min" if you prefer conservative scaling that avoids rapid fluctuations.
How autoscaling metrics work#
Understanding how metrics flow through the autoscaling system helps you configure the parameters effectively. The metrics pipeline involves several stages, each with its own timing parameters:
┌──────────────────────────────────────────────────────────────────────────┐
│ Metrics Pipeline Overview │
├──────────────────────────────────────────────────────────────────────────┤
│ │
│ Replicas/Handles Controller Autoscaling Policy │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ Record │ Push │ Receive │ Decide │ Policy │ │
│ │ Metrics │────────────>│ Metrics │──────────>│ Runs │ │
│ │ (10s) │ (10s) │ │ (0.1s) │ │ │
│ └──────────┘ │ Aggregate│ └──────────┘ │
│ │ (30s) │ │
│ └──────────┘ │
│ │
└──────────────────────────────────────────────────────────────────────────┘
Stage 1: Metric recording#
Replicas and deployment handles continuously record autoscaling metrics:
What: Number of ongoing requests (queued + running)
Frequency: Every 10s (configurable via
metrics_interval_s)Storage: Metrics are stored locally as a timeseries
Stage 2: Metric pushing#
Periodically, replicas and handles push their metrics to the controller:
Frequency: Every 10s (configurable via
RAY_SERVE_REPLICA_AUTOSCALING_METRIC_PUSH_INTERVAL_SandRAY_SERVE_HANDLE_AUTOSCALING_METRIC_PUSH_INTERVAL_S)Data sent: Both raw timeseries data and pre-aggregated metrics
Raw timeseries: Data points are clipped to the
look_back_period_swindow before sending (only recent measurements within the window are sent)Pre-aggregated metrics: A simple average computed over the
look_back_period_swindow at the replica/handle
Controller usage: The controller decides which data to use based on the
RAY_SERVE_AGGREGATE_METRICS_AT_CONTROLLERsetting (see Stage 3 below)
Stage 3: Metric aggregation#
The controller aggregates metrics to compute total ongoing requests across all replicas. Ray Serve supports two aggregation modes (controlled by RAY_SERVE_AGGREGATE_METRICS_AT_CONTROLLER):
Simple mode (default - RAY_SERVE_AGGREGATE_METRICS_AT_CONTROLLER=0):
Input: Pre-aggregated simple averages from replicas/handles (already clipped to
look_back_period_s)Method: Sums the pre-aggregated values from all sources. Each component computes a simple average (arithmetic mean) before sending.
Output: Single value representing total ongoing requests
Characteristics: Lightweight and works well for most workloads. However, because it uses simple averages rather than time-weighted averages, it can be less accurate when replicas have different metric reporting intervals or when metrics arrive at different times.
Aggregate mode (experimental - RAY_SERVE_AGGREGATE_METRICS_AT_CONTROLLER=1):
Input: Raw timeseries data from replicas/handles (already clipped to
look_back_period_s)Method: Time-weighted aggregation using the
aggregation_function(mean, max, or min). Uses an instantaneous merge approach that treats metrics as right-continuous step functions.Output: Single value representing total ongoing requests
Characteristics: Provides more mathematically accurate aggregation, especially when replicas report metrics at different intervals or you need precise time-weighted averages. The trade-off is increased controller overhead.
Note
The aggregation_function parameter only applies in aggregate mode. In simple mode, the aggregation is always a sum of the pre-computed simple averages.
Note
The long-term plan is to deprecate simple mode in favor of aggregate mode. Aggregate mode provides more accurate metrics aggregation and will become the default in a future release. Consider testing aggregate mode(RAY_SERVE_AGGREGATE_METRICS_AT_CONTROLLER=1) in your deployments to prepare for this transition.
Stage 4: Policy execution#
The autoscaling policy runs frequently to make scaling decisions, see Custom policy for deployment for details on implementing custom scaling logic:
Frequency: Every 0.1s (configurable via
RAY_SERVE_CONTROL_LOOP_INTERVAL_S)Input:
AutoscalingContextOutput: Tuple of
(target_replicas, updated_policy_state)
Timing parameter interactions#
The timing parameters interact in important ways:
Recording vs pushing intervals:
Push interval ≥ Recording interval
Recording interval (10s) determines granularity of data
Push interval (10s) determines how fresh the controller’s data is
With default values: Each push contains 1 data points (10s ÷ 10s)
Push interval vs look-back period:
look_back_period_s(30s) should be > push interval (10s)If look-back is too short, you won’t have enough data for stable decisions
If look-back is too long, autoscaling becomes less responsive
Push interval vs control loop:
Control loop (0.1s) runs much faster than metrics arrive (10s)
Most control loop iterations reuse existing metrics
New scaling decisions only happen when fresh metrics arrive
Push interval vs upscale/downscale delays:
Delays control when Ray Serve applies a scale up or scale down.
The metrics push interval controls how quickly Ray Serve receives fresh metrics.
If the push interval < delay, Ray Serve can use multiple metric updates before it scales.
Example: push every 10s with
upscale_delay_s = 20means up to 2 new metric updates before scaling
Recommendation: Keep default values unless you have specific needs. If you need faster autoscaling, decrease push intervals first, then adjust delays.
Environment variables#
Several environment variables control autoscaling behavior at a lower level. These variables affect metrics collection and the control loop timing:
Control loop and timeout settings#
RAY_SERVE_CONTROL_LOOP_INTERVAL_S(default: 0.1s): How often the Ray Serve controller runs the autoscaling control loop. Your autoscaling policy function executes at this frequency. The default value of 0.1s means policies run approximately 10 times per second.RAY_SERVE_RECORD_AUTOSCALING_STATS_TIMEOUT_S(default: 10.0s): Maximum time allowed for therecord_autoscaling_stats()method to complete in custom metrics collection. If this timeout is exceeded, the metrics collection fails and a warning is logged.RAY_SERVE_MIN_HANDLE_METRICS_TIMEOUT_S(default: 10.0s): Minimum timeout for handle metrics collection. The system uses the maximum of this value and2 *metrics_interval_sto determine when to drop stale handle metrics.
Advanced feature flags#
RAY_SERVE_AGGREGATE_METRICS_AT_CONTROLLER(default: false): Enables an experimental metrics aggregation mode where the controller aggregates raw timeseries data instead of using pre-aggregated metrics. This mode provides more accurate time-weighted averages but may increase controller overhead. See Stage 3 in “How autoscaling metrics work” for details.
Model composition example#
Determining the autoscaling configuration for a multi-model application requires understanding each deployment’s scaling requirements. Every deployment has a different latency and differing levels of concurrency. As a result, finding the right autoscaling config for a model-composition application requires experimentation.
This example is a simple application with three deployments composed together to build some intuition about multi-model autoscaling. Assume these deployments:
HeavyLoad: A mock 200ms workload with high CPU usage.LightLoad: A mock 100ms workload with high CPU usage.Driver: A driver deployment that fans out to theHeavyLoadandLightLoaddeployments and aggregates the two outputs.
Attempt 1: One Driver replica#
First consider the following deployment configurations. Because the driver deployment has low CPU usage and is only asynchronously making calls to the downstream deployments, allocating one fixed Driver replica is reasonable.
- name: Driver
num_replicas: 1
max_ongoing_requests: 200
- name: HeavyLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
- name: LightLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
import time
from ray import serve
from ray.serve.handle import DeploymentHandle
@serve.deployment
class LightLoad:
async def __call__(self) -> str:
start = time.time()
while time.time() - start < 0.1:
pass
return "light"
@serve.deployment
class HeavyLoad:
async def __call__(self) -> str:
start = time.time()
while time.time() - start < 0.2:
pass
return "heavy"
@serve.deployment
class Driver:
def __init__(self, a_handle, b_handle):
self.a_handle: DeploymentHandle = a_handle
self.b_handle: DeploymentHandle = b_handle
async def __call__(self) -> str:
a_future = self.a_handle.remote()
b_future = self.b_handle.remote()
return (await a_future), (await b_future)
app = Driver.bind(HeavyLoad.bind(), LightLoad.bind())
Running the same Locust load test from the Resnet workload generates the following results:
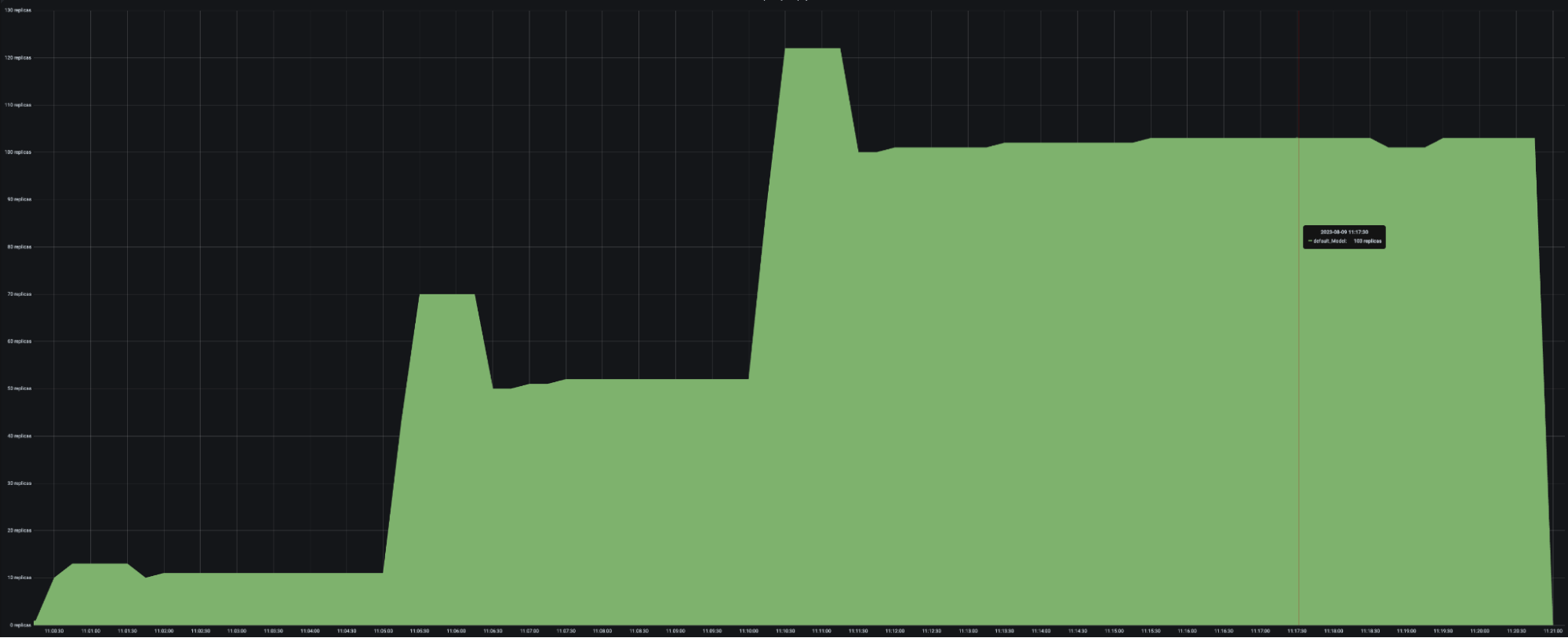
HeavyLoad and LightLoad Number Replicas |
|
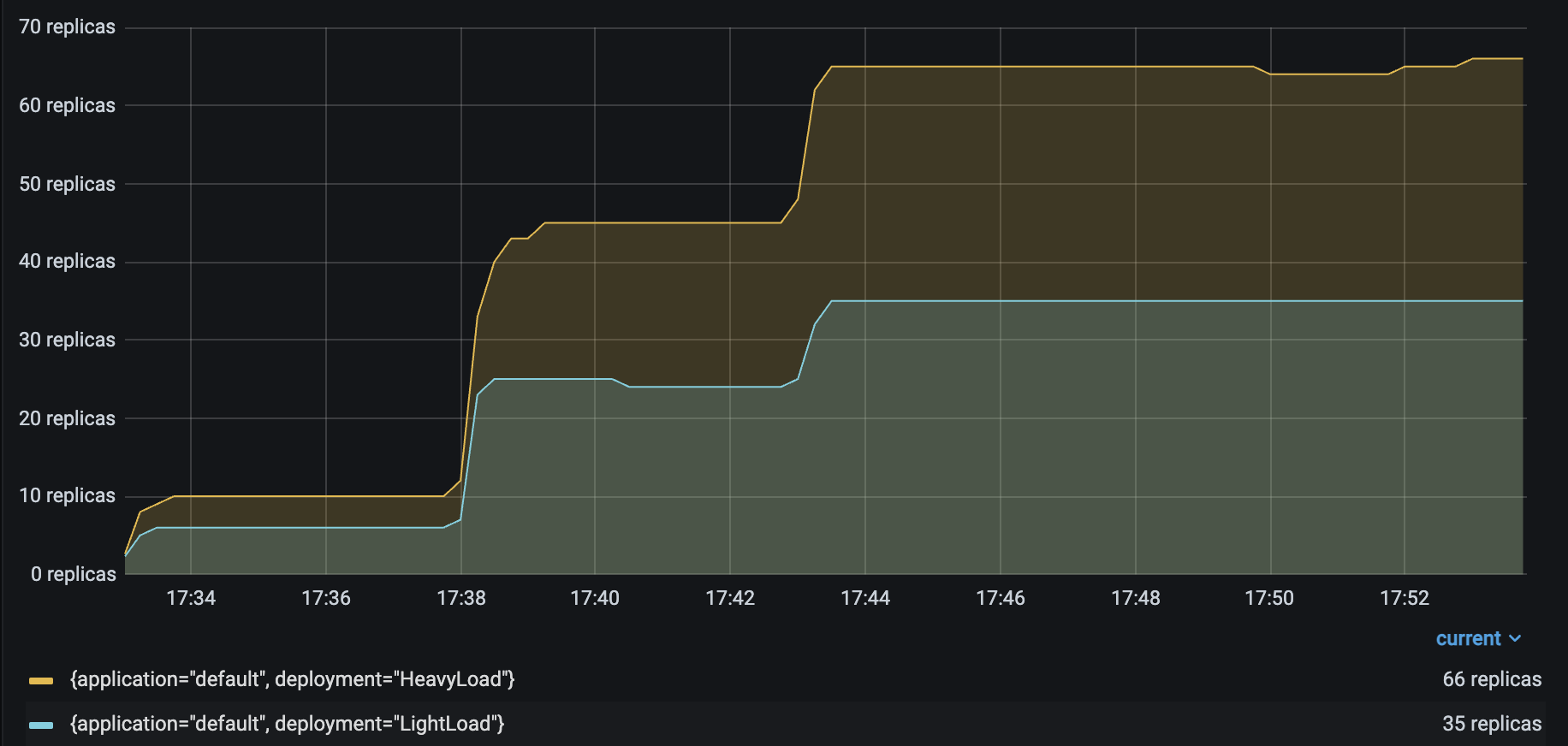
As you might expect, the number of autoscaled LightLoad replicas is roughly half that of autoscaled HeavyLoad replicas. Although the same number of requests per second are sent to both deployments, LightLoad replicas can process twice as many requests per second as HeavyLoad replicas can, so the deployment should need half as many replicas to handle the same traffic load.
Unfortunately, the service latency rises to from 230 to 400 ms when the number of Locust users increases to 100.
P50 Latency |
QPS |
|---|---|
|
|


Note that the number of HeavyLoad replicas should roughly match the number of Locust users to adequately serve the Locust traffic. However, when the number of Locust users increased to 100, the HeavyLoad deployment struggled to reach 100 replicas, and instead only reached 65 replicas. The per-deployment latencies reveal the root cause. While HeavyLoad and LightLoad latencies stayed steady at 200ms and 100ms, Driver latencies rose from 230 to 400 ms. This suggests that the high Locust workload may be overwhelming the Driver replica and impacting its asynchronous event loop’s performance.
Attempt 2: Autoscale Driver#
For this attempt, set an autoscaling configuration for Driver as well, with the setting target_ongoing_requests = 20. Now the deployment configurations are as follows:
- name: Driver
max_ongoing_requests: 200
autoscaling_config:
target_ongoing_requests: 20
min_replicas: 1
initial_replicas: 1
max_replicas: 10
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
- name: HeavyLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
- name: LightLoad
max_ongoing_requests: 3
autoscaling_config:
target_ongoing_requests: 1
min_replicas: 0
initial_replicas: 0
max_replicas: 200
upscale_delay_s: 3
downscale_delay_s: 60
upscaling_factor: 0.3
downscaling_factor: 0.3
metrics_interval_s: 2
look_back_period_s: 10
Running the same Locust load test again generates the following results:
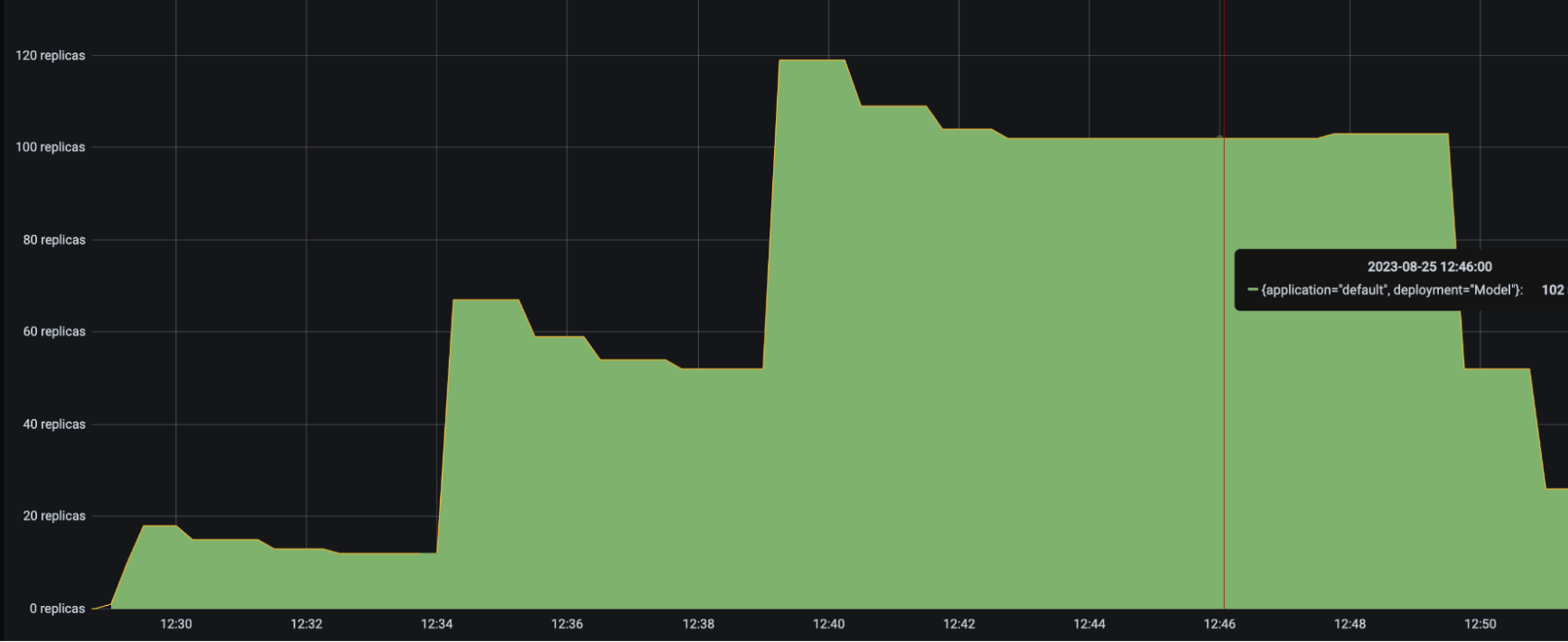
HeavyLoad and LightLoad Number Replicas |
|
Driver Number Replicas |
|
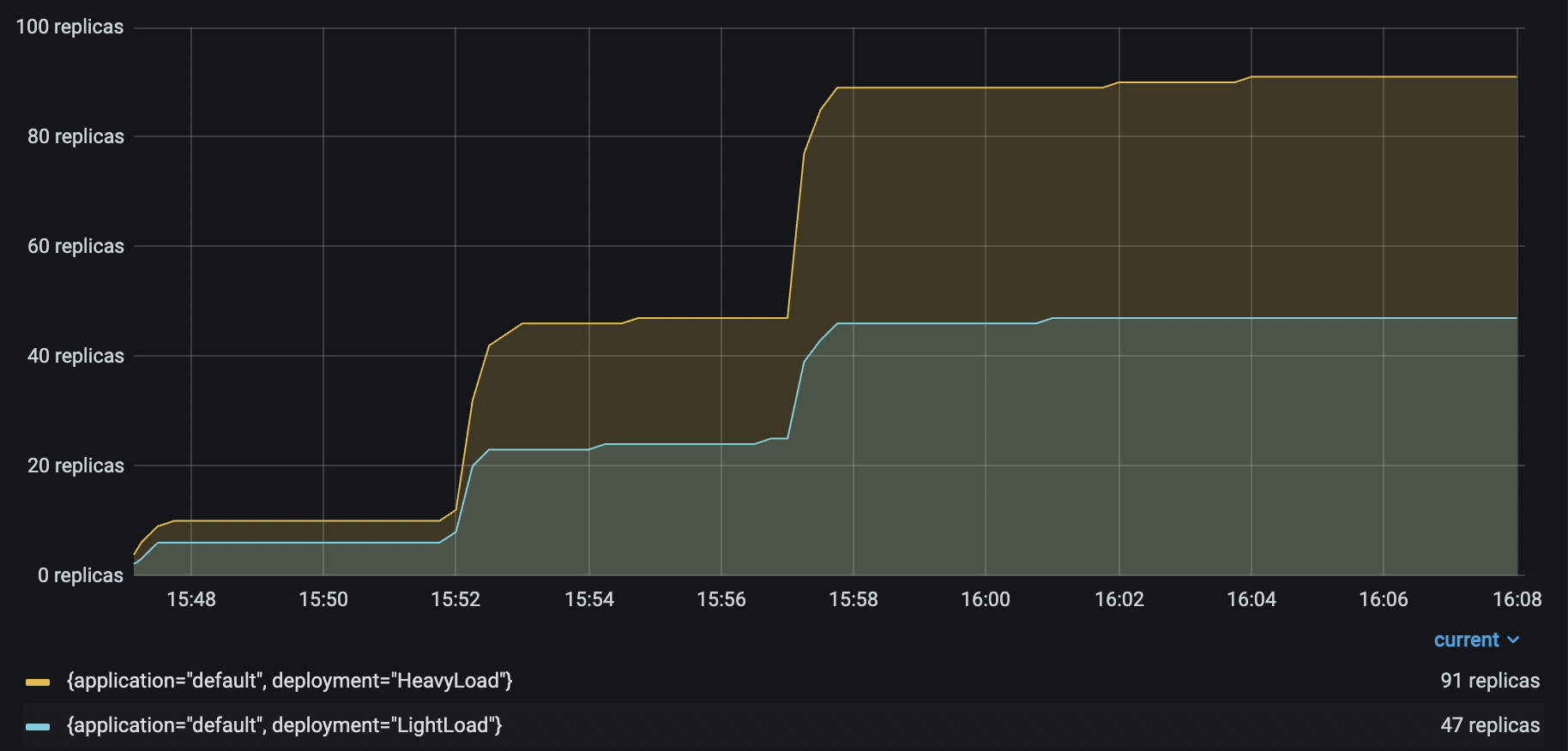
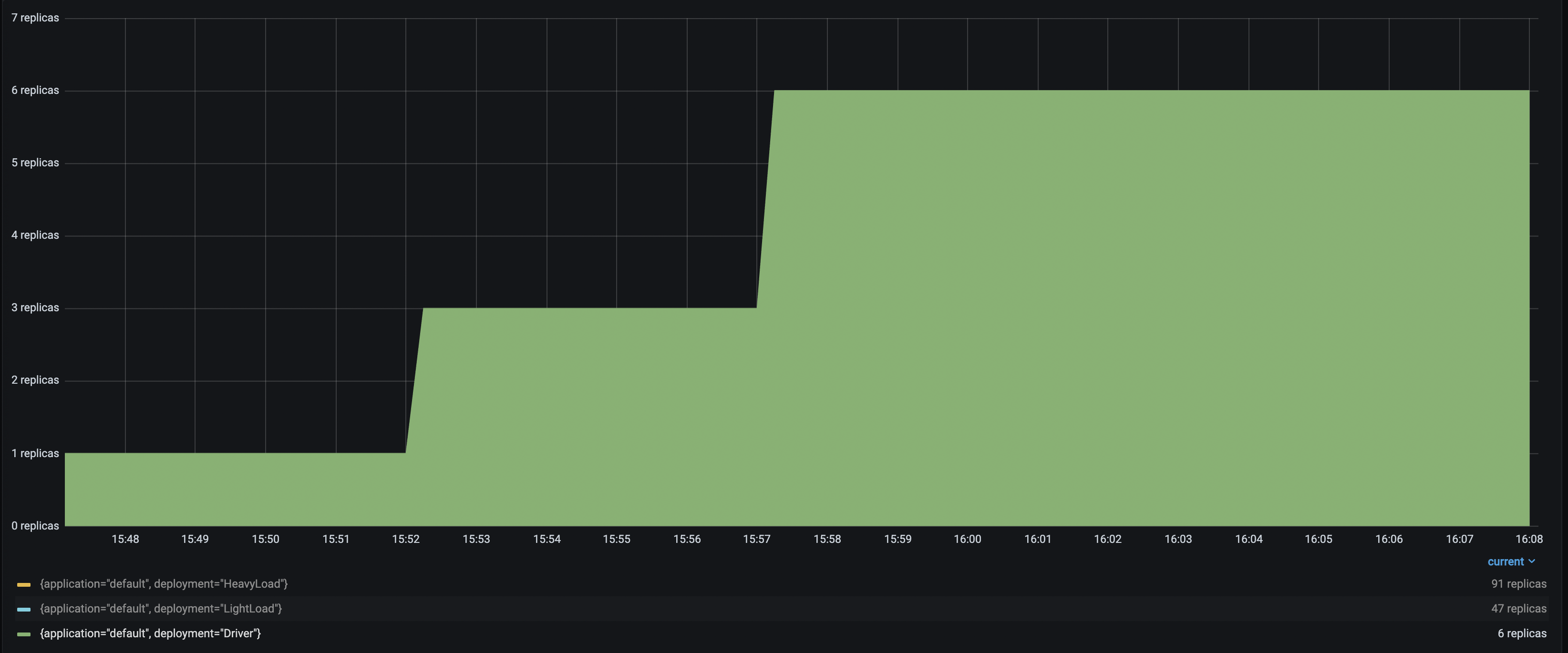
With up to 6 Driver deployments to receive and distribute the incoming requests, the HeavyLoad deployment successfully scales up to 90+ replicas, and LightLoad up to 47 replicas. This configuration helps the application latency stay consistent as the traffic load increases.
Improved P50 Latency |
Improved RPS |
|---|---|
|
|


Troubleshooting guide#
Unstable number of autoscaled replicas#
If the number of replicas in your deployment keeps oscillating even though the traffic is relatively stable, try the following:
Set a smaller
upscaling_factoranddownscaling_factor. Setting both values smaller than one helps the autoscaler make more conservative upscale and downscale decisions. It effectively smooths out the replicas graph, and there will be less “sharp edges”.Set a
look_back_period_svalue that matches the rest of the autoscaling config. For longer upscale and downscale delay values, a longer look back period can likely help stabilize the replica graph, but for shorter upscale and downscale delay values, a shorter look back period may be more appropriate. For instance, the following replica graphs show how a deployment withupscale_delay_s = 3works with a longer vs shorter look back period.
|
|
|---|---|
|
|
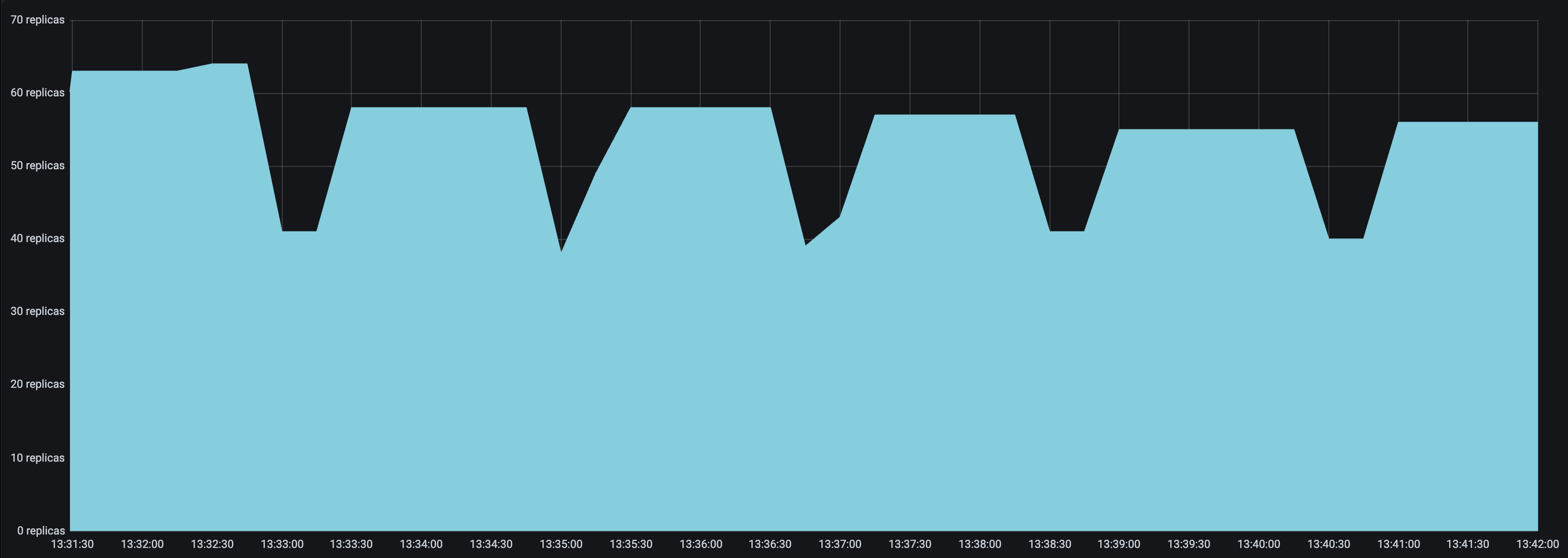
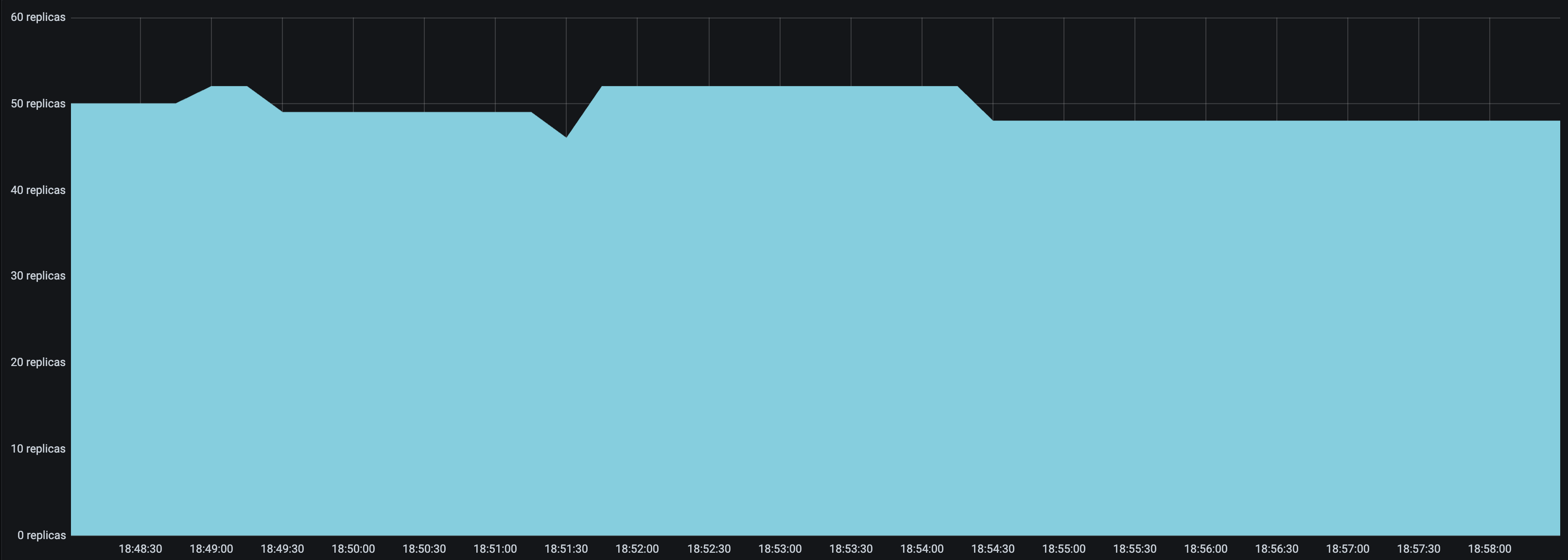
High spikes in latency during bursts of traffic#
If you expect your application to receive bursty traffic, and at the same time want the deployments to scale down in periods of inactivity, you are likely concerned about how quickly the deployment can scale up and respond to bursts of traffic. While an increase in latency initially during a burst in traffic may be unavoidable, you can try the following to improve latency during bursts of traffic.
Set a lower
upscale_delay_s. The autoscaler always waitsupscale_delay_sseconds before making a decision to upscale, so lowering this delay allows the autoscaler to react more quickly to changes, especially bursts, of traffic.Set a larger
upscaling_factor. Ifupscaling_factor > 1, then the autoscaler scales up more aggressively than normal. This setting can allow your deployment to be more sensitive to bursts of traffic.Lower the
metrics_interval_s. Always setmetrics_interval_sto be less than or equal toupscale_delay_s, otherwise upscaling is delayed because the autoscaler doesn’t receive fresh information often enough.Set a lower
max_ongoing_requests. Ifmax_ongoing_requestsis too high relative totarget_ongoing_requests, then when traffic increases, Serve might assign most or all of the requests to the existing replicas before the new replicas are started. This setting can lead to very high latencies during upscale.
Deployments scaling down too quickly#
You may observe that deployments are scaling down too quickly. Instead, you may want the downscaling to be much more conservative to maximize the availability of your service.
Set a longer
downscale_delay_s. The autoscaler always waitsdownscale_delay_sseconds before making a decision to downscale, so by increasing this number, your system has a longer “grace period” after traffic drops before the autoscaler starts to remove replicas.Set a smaller
downscaling_factor. Ifdownscaling_factor < 1, then the autoscaler removes less replicas than what it thinks it should remove to achieve the target number of ongoing requests. In other words, the autoscaler makes more conservative downscaling decisions.
|
|
|---|---|
|
|
Custom autoscaling policies#
Warning
Custom autoscaling policies are experimental and may change in future releases.
Ray Serve’s built-in, request-driven autoscaling works well for most apps. Use custom autoscaling policies when you need more control—e.g., scaling on external metrics (CloudWatch, Prometheus), anticipating predictable traffic (scheduled batch jobs), or applying business logic that goes beyond queue thresholds.
Custom policies let you implement scaling logic based on any metrics or rules you choose.
Custom policy for deployment#
A custom autoscaling policy is a user-provided Python function that takes an AutoscalingContext and returns a tuple (target_replicas, policy_state) for a single Deployment.
An AutoscalingContext object provides the following information to the custom autoscaling policy:
Current state: Current replica count and deployment metadata.
Built-in metrics: Total requests, queued requests, per-replica counts.
Custom metrics: Values your deployment reports via
record_autoscaling_stats(). (See below.)Capacity bounds:
min/maxreplica limits adjusted for current cluster capacity.Policy state: A
dictyou can use to persist arbitrary state across control-loop iterations.Timing: Timestamps of the last scale actions and “now”.
The following example showcases a policy that scales up during business hours and evening batch processing, and scales down during off-peak hours:
autoscaling_policy.py file:
from datetime import datetime
from typing import Any, Dict
from ray.serve.config import AutoscalingContext
def scheduled_batch_processing_policy(
ctx: AutoscalingContext,
) -> tuple[int, Dict[str, Any]]:
current_time = datetime.now()
current_hour = current_time.hour
# Scale up during business hours (9 AM - 5 PM)
if 9 <= current_hour < 17:
return 2, {"reason": "Business hours"}
# Scale up for evening batch processing (6 PM - 8 PM)
elif 18 <= current_hour < 20:
return 4, {"reason": "Evening batch processing"}
# Minimal scaling during off-peak hours
else:
return 1, {"reason": "Off-peak hours"}
main.py file:
import asyncio
from ray import serve
from ray.serve.config import AutoscalingConfig, AutoscalingPolicy
@serve.deployment(
autoscaling_config=AutoscalingConfig(
min_replicas=1,
max_replicas=12,
policy=AutoscalingPolicy(
policy_function="autoscaling_policy:scheduled_batch_processing_policy"
),
),
)
class BatchProcessingDeployment:
async def __call__(self) -> str:
# Simulate batch processing work
await asyncio.sleep(0.5)
return "Hello, world!"
app = BatchProcessingDeployment.bind()
Policies are defined per deployment. If you don’t provide one, Ray Serve falls back to its built-in request-based policy.
The policy function is invoked by the Ray Serve controller every RAY_SERVE_CONTROL_LOOP_INTERVAL_S seconds (default 0.1s), so your logic runs against near-real-time state.
Your policy can return an int or a float for target_replicas. If it returns a float, Ray Serve converts it to an integer replica count by rounding up to the next greatest integer.
Warning
Keep policy functions fast and lightweight. Slow logic can block the Serve controller and degrade cluster responsiveness.
Applying standard autoscaling parameters to custom policies#
Ray Serve automatically applies the following standard autoscaling parameters from your AutoscalingConfig to custom policies:
upscale_delay_s,downscale_delay_s,downscale_to_zero_delay_supscaling_factor,downscaling_factormin_replicas,max_replicas
The following example shows a custom autoscaling policy with standard autoscaling parameters applied.
from typing import Any, Dict
from ray.serve.config import AutoscalingContext
def queue_length_based_autoscaling_policy(
ctx: AutoscalingContext,
) -> tuple[int, Dict[str, Any]]:
# This policy calculates the "raw" desired replicas based on queue length.
# Ray Serve automatically applies scaling factors, delays, and bounds from
# the deployment's autoscaling_config on top of this decision.
queue_length = ctx.total_num_requests
if queue_length > 50:
return 10, {}
elif queue_length > 10:
return 5, {}
else:
return 0, {}
from ray import serve
from ray.serve.config import AutoscalingConfig, AutoscalingPolicy
@serve.deployment(
autoscaling_config=AutoscalingConfig(
min_replicas=1,
max_replicas=10,
metrics_interval_s=0.1,
upscale_delay_s=1.0,
downscale_delay_s=1.0,
policy=AutoscalingPolicy(
policy_function=queue_length_based_autoscaling_policy
)
),
max_ongoing_requests=5,
)
class MyDeployment:
def __call__(self) -> str:
return "Hello, world!"
app = MyDeployment.bind()
Note
Your policy function should return the “raw” desired number of replicas. Ray Serve applies the autoscaling_config settings (delays, factors, and bounds) on top of your decision.
Your policy can return an int or a float “raw desired” replica count. Ray Serve returns an integer decision number.
Custom metrics#
You can make richer decisions by emitting your own metrics from the deployment. Implement record_autoscaling_stats() to return a dict[str, float]. Ray Serve will surface these values in the AutoscalingContext.
This example demonstrates how deployments can provide their own metrics (CPU usage, memory usage) and how autoscaling policies can use these metrics to make scaling decisions:
autoscaling_policy.py file:
from typing import Any, Dict
from ray.serve.config import AutoscalingContext
def custom_metrics_autoscaling_policy(
ctx: AutoscalingContext,
) -> tuple[int, Dict[str, Any]]:
cpu_usage_metric = ctx.aggregated_metrics.get("cpu_usage", {})
memory_usage_metric = ctx.aggregated_metrics.get("memory_usage", {})
max_cpu_usage = list(cpu_usage_metric.values())[-1] if cpu_usage_metric else 0
max_memory_usage = (
list(memory_usage_metric.values())[-1] if memory_usage_metric else 0
)
if max_cpu_usage > 80 or max_memory_usage > 85:
return min(ctx.capacity_adjusted_max_replicas, ctx.current_num_replicas + 1), {}
elif max_cpu_usage < 30 and max_memory_usage < 40:
return max(ctx.capacity_adjusted_min_replicas, ctx.current_num_replicas - 1), {}
else:
return ctx.current_num_replicas, {}
main.py file:
import time
from typing import Dict
import psutil
from ray import serve
@serve.deployment(
autoscaling_config={
"min_replicas": 1,
"max_replicas": 5,
"metrics_interval_s": 0.1,
"policy": {
"policy_function": "autoscaling_policy:custom_metrics_autoscaling_policy"
},
},
max_ongoing_requests=5,
)
class CustomMetricsDeployment:
def __init__(self):
self.process = psutil.Process()
def __call__(self) -> str:
# Simulate some work
time.sleep(0.5)
return "Hello, world!"
def record_autoscaling_stats(self) -> Dict[str, float]:
# Get CPU usage as a percentage
cpu_usage = self.process.cpu_percent(interval=0.1)
# Get memory usage as a percentage of system memory
memory_info = self.process.memory_full_info()
system_memory = psutil.virtual_memory().total
memory_usage = (memory_info.uss / system_memory) * 100
return {
"cpu_usage": cpu_usage,
"memory_usage": memory_usage,
}
# Create the app
app = CustomMetricsDeployment.bind()
Note
The record_autoscaling_stats() method can be either synchronous or asynchronous. It must complete within the timeout specified by RAY_SERVE_RECORD_AUTOSCALING_STATS_TIMEOUT_S (default 10 seconds).
In your policy, access custom metrics via:
ctx.raw_metrics[metric_name]— A mapping of replica IDs to lists of raw metric values. The number of data points stored for each replica depends on thelook_back_period_s(the sliding window size) andmetrics_interval_s(the metric recording interval).ctx.aggregated_metrics[metric_name]— A time-weighted average computed from the raw metric values for each replica.
Class-based policies#
When your policy needs long-running setup — such as polling an external metrics service, maintaining a persistent connection, or running background computation — you can define it as a class instead of a plain function. Pass the class reference through policy_function and supply constructor arguments through policy_kwargs.
Ray Serve instantiates the class once on the controller when the deployment starts. __init__ runs one-time setup, and __call__ runs on every autoscaling tick with the current AutoscalingContext.
The following example shows a policy that reads a target replica count from a JSON file in a background loop. In production you could replace the file read with an HTTP call, a message-queue consumer, or any other async IO operation:
class_based_autoscaling_policy.py file:
import asyncio
import json
import logging
from pathlib import Path
from typing import Any, Dict, Tuple
from ray.serve.config import AutoscalingContext
logger = logging.getLogger("ray.serve")
class FileBasedAutoscalingPolicy:
"""Scale replicas based on a target written to a JSON file.
A background asyncio task re-reads the file every ``poll_interval_s``
seconds. ``__call__`` returns the latest value on every autoscaling
tick. In production you could replace the file read with an HTTP
call, a message-queue consumer, or any other async IO operation.
"""
def __init__(self, file_path: str, poll_interval_s: float = 5.0):
self._file_path = Path(file_path)
self._poll_interval_s = poll_interval_s
self._desired_replicas: int = 1
self._task: asyncio.Task = None
self._started: bool = False
def _ensure_started(self) -> None:
"""Lazily start the background poll on the controller event loop."""
if self._started:
return
self._started = True
loop = asyncio.get_running_loop()
self._task = loop.create_task(self._poll_file())
async def _poll_file(self) -> None:
"""Read the target replica count from the JSON file in a loop."""
while True:
try:
text = self._file_path.read_text()
data = json.loads(text)
self._desired_replicas = int(data["replicas"])
except Exception:
pass # Keep the last known value on failure.
await asyncio.sleep(self._poll_interval_s)
def __call__(
self, ctx: AutoscalingContext
) -> Tuple[int, Dict[str, Any]]:
self._ensure_started()
desired = self._desired_replicas
return desired, {"last_polled_value": self._desired_replicas}
main.py file:
import json
import tempfile
from ray import serve
from ray.serve.config import AutoscalingConfig, AutoscalingPolicy
# Create a JSON file with the initial target replica count.
# In production this file would be written by an external system.
scaling_file = tempfile.NamedTemporaryFile(
mode="w", suffix=".json", delete=False
)
json.dump({"replicas": 2}, scaling_file)
scaling_file.close()
@serve.deployment(
autoscaling_config=AutoscalingConfig(
min_replicas=1,
max_replicas=10,
upscale_delay_s=3,
downscale_delay_s=10,
policy=AutoscalingPolicy(
policy_function="class_based_autoscaling_policy:FileBasedAutoscalingPolicy",
policy_kwargs={
"file_path": scaling_file.name,
"poll_interval_s": 2.0,
},
),
),
max_ongoing_requests=100,
)
class MyDeployment:
async def __call__(self) -> str:
return "Hello, world!"
app = MyDeployment.bind()
Note
The instance lives only on the Serve controller and is never serialized after creation, so it’s safe to hold non-picklable state such as asyncio.Task objects, open connections, or thread pools. policy_kwargs values must be JSON-serializable because they travel through the deployment config.
Tip
If you’re using @task_consumer deployments for asynchronous inference, Ray Serve provides a built-in AsyncInferenceAutoscalingPolicy that scales based on message queue length. See Asynchronous Inference: Autoscaling for setup and configuration.
Application level autoscaling#
By default, each deployment in Ray Serve autoscales independently. When you have multiple deployments that need to scale in a coordinated way—such as deployments that share backend resources, have dependencies on each other, or need load-aware routing—you can define an application-level autoscaling policy. This policy makes scaling decisions for all deployments within an application simultaneously.
Define an application level policy#
An application-level autoscaling policy is a function that takes a dict[DeploymentID, AutoscalingContext] objects (one per deployment) and returns a tuple of (decisions, policy_state). Each context contains metrics and bounds for one deployment, and the policy returns target replica counts for all deployments.
The policy_state returned from an application-level policy must be a Dict[DeploymentID, Dict]— a dictionary mapping each deployment ID to its own state dictionary. Serve stores this per-deployment state and on the next control-loop iteration, injects each deployment’s state back into that deployment’s AutoscalingContext.policy_state. The per deployment number replicas returned from the policy can be an int or a float. If it returns a float, Ray Serve converts it to an integer replica count by rounding up to the next greatest integer.
Serve itself does not interpret the contents of policy_state. All the keys in each deployment’s state dictionary are user-controlled except for internal keys that are used when default parameters are applied to custom autoscaling policies. The following example shows a policy that scales deployments based on their relative load, ensuring that downstream deployments have enough capacity for upstream traffic:
autoscaling_policy.py file:
from typing import Dict, Tuple
from ray.serve.config import AutoscalingContext
from ray.serve._private.common import DeploymentID
from ray.serve.config import AutoscalingContext
def coordinated_scaling_policy(
contexts: Dict[DeploymentID, AutoscalingContext]
) -> Tuple[Dict[DeploymentID, int], Dict]:
"""Scale deployments based on coordinated load balancing."""
decisions = {}
# Example: Scale a preprocessing deployment
preprocessing_id = [d for d in contexts if d.name == "Preprocessor"][0]
preprocessing_ctx = contexts[preprocessing_id]
# Scale based on queue depth
preprocessing_replicas = max(
preprocessing_ctx.capacity_adjusted_min_replicas,
min(
preprocessing_ctx.capacity_adjusted_max_replicas,
preprocessing_ctx.total_num_requests // 10,
),
)
decisions[preprocessing_id] = preprocessing_replicas
# Example: Scale a model deployment proportionally
model_id = [d for d in contexts if d.name == "Model"][0]
model_ctx = contexts[model_id]
# Scale model to handle preprocessing output
# Assuming model takes 2x longer than preprocessing
model_replicas = max(
model_ctx.capacity_adjusted_min_replicas,
min(model_ctx.capacity_adjusted_max_replicas, preprocessing_replicas * 2),
)
decisions[model_id] = model_replicas
return decisions, {}
The following example shows a stateful application-level policy that persists state between control-loop iterations:
autoscaling_policy.py file:
from typing import Dict, Tuple, Any
from ray.serve.config import AutoscalingContext
from ray.serve._private.common import DeploymentID
def stateful_application_level_policy(
contexts: Dict[DeploymentID, AutoscalingContext]
) -> Tuple[Dict[DeploymentID, int], Dict[DeploymentID, Dict[str, Any]]]:
"""Example policy demonstrating per-deployment state persistence."""
decisions = {}
policy_state = {}
for deployment_id, ctx in contexts.items():
# Read previous state for this deployment (persisted from last iteration)
prev_state = ctx.policy_state or {}
scale_count = prev_state.get("scale_count", 0)
last_replicas = prev_state.get("last_replicas", ctx.current_num_replicas)
# Simple scaling logic: scale based on queue depth
desired_replicas = max(
ctx.capacity_adjusted_min_replicas,
min(
ctx.capacity_adjusted_max_replicas,
ctx.total_num_requests // 10,
),
)
decisions[deployment_id] = desired_replicas
# Store per-deployment state that persists across iterations
policy_state[deployment_id] = {
"scale_count": scale_count + 1,
"last_replicas": desired_replicas,
}
return decisions, policy_state
Configure application level autoscaling#
To use an application-level policy, you need to define your deployments:
main.py file:
import time
from ray import serve
@serve.deployment
class Preprocessor:
def __call__(self, input_data: str) -> str:
# Simulate preprocessing work
time.sleep(0.05)
return f"preprocessed_{input_data}"
@serve.deployment
class Model:
def __call__(self, preprocessed_data: str) -> str:
# Simulate model inference (takes longer than preprocessing)
time.sleep(0.1)
return f"result_{preprocessed_data}"
@serve.deployment
class Driver:
def __init__(self, preprocessor, model):
self._preprocessor = preprocessor
self._model = model
async def __call__(self, input_data: str) -> str:
# Coordinate preprocessing and model inference
preprocessed = await self._preprocessor.remote(input_data)
result = await self._model.remote(preprocessed)
return result
app = Driver.bind(Preprocessor.bind(), Model.bind())
Then specify the application-level policy in your application config:
serve.yaml file:
applications:
- name: MyApp
import_path: application_level_autoscaling:app
autoscaling_policy:
policy_function: autoscaling_policy:coordinated_scaling_policy
deployments:
- name: Preprocessor
autoscaling_config:
min_replicas: 1
max_replicas: 10
- name: Model
autoscaling_config:
min_replicas: 2
max_replicas: 20
Note
Programmatic configuration of application-level autoscaling policies through serve.run() will be supported in a future release.
Note
When you specify both a deployment-level policy and an application-level policy, the application-level policy takes precedence. Ray Serve logs a warning if you configure both.
Applying standard autoscaling parameters to application-level policies#
Ray Serve automatically applies standard autoscaling parameters (delays, factors, and min/max bounds) to application-level policies on a per-deployment basis. These parameters include:
upscale_delay_s,downscale_delay_s,downscale_to_zero_delay_supscaling_factor,downscaling_factormin_replicas,max_replicas
The YAML configuration file shows the default parameters applied to the application level policy.
applications:
- name: MyApp
import_path: application_level_autoscaling:app
autoscaling_policy:
policy_function: autoscaling_policy:coordinated_scaling_policy_with_defaults
deployments:
- name: Preprocessor
autoscaling_config:
min_replicas: 1
max_replicas: 10
target_ongoing_requests: 1
upscale_delay_s: 2
downscale_delay_s: 5
- name: Model
autoscaling_config:
min_replicas: 2
max_replicas: 20
target_ongoing_requests: 1
upscale_delay_s: 3
downscale_delay_s: 5
Your application level policy can return per deployment desired replicas as int or float values. Ray Serve applies the autoscaling config parameters per deployment and returns integer decisions.
Warning
Gotchas and limitations
When you provide a custom policy, Ray Serve can fully support it as long as it’s simple, self-contained Python code that relies only on the standard library. Once the policy becomes more complex, such as depending on other custom modules or packages, you need to bundle those modules into the Docker image or environment. This is because Ray Serve uses cloudpickle to serialize custom policies and it doesn’t vendor transitive dependencies—if your policy inherits from a superclass in another module or imports custom packages, those must exist in the target environment. Additionally, environment parity matters: differences in Python version, cloudpickle version, or library versions can affect deserialization.
Alternatives for complex policies
When your custom autoscaling policy has complex dependencies or you want better control over versioning and deployment, you have several alternatives:
Contribute to Ray Serve: If your policy is general-purpose and might benefit others, consider contributing it to Ray Serve as a built-in policy by opening a feature request or pull request on the Ray GitHub repository. The recommended location for the implementation is
python/ray/serve/autoscaling_policy.py.Ensure dependencies in your environment: Make sure that the external dependencies are installed in your Docker image or environment.
External scaling API#
Warning
This API is in alpha and may change before becoming stable.
The external scaling API provides programmatic control over the number of replicas for any deployment in your Ray Serve application. Unlike Ray Serve’s built-in autoscaling, which scales based on queue depth and ongoing requests, this API allows you to scale based on any external criteria you define.
Example: Predictive scaling#
This example shows how to implement predictive scaling based on historical patterns or forecasts. You can preemptively scale up before anticipated traffic spikes by running an external script that adjusts replica counts based on time of day.
Define the deployment#
The following example creates a simple text processing deployment that you can scale externally. Save this code to a file named external_scaler_predictive.py:
import time
from ray import serve
from typing import Any
@serve.deployment(num_replicas=3)
class TextProcessor:
"""A simple text processing deployment that can be scaled externally."""
def __init__(self):
self.request_count = 0
def __call__(self, text: Any) -> dict:
# Simulate text processing work
time.sleep(0.1)
self.request_count += 1
return {
"request_count": self.request_count,
}
app = TextProcessor.bind()
Configure external scaling#
Before using the external scaling API, enable it in your application configuration by setting external_scaler_enabled: true. Save this configuration to a file named external_scaler_config.yaml:
applications:
- name: my-app
import_path: external_scaler_predictive:app
external_scaler_enabled: true
deployments:
- name: TextProcessor
num_replicas: 1
Warning
External scaling and built-in autoscaling are mutually exclusive. You can’t use both for the same application. If you set external_scaler_enabled: true, you must not configure autoscaling_config on any deployment in that application. Attempting to use both results in an error.
Implement the scaling logic#
The following script implements predictive scaling based on time of day and historical traffic patterns. Save this script to a file named external_scaler_predictive_client.py:
import logging
import time
from datetime import datetime
import requests
APPLICATION_NAME = "my-app"
DEPLOYMENT_NAME = "TextProcessor"
SERVE_ENDPOINT = "http://localhost:8265"
SCALING_INTERVAL = 300 # Check every 5 minutes
logger = logging.getLogger(__name__)
def get_current_replicas(app_name: str, deployment_name: str) -> int:
"""Get current replica count. Returns -1 on error."""
try:
resp = requests.get(
f"{SERVE_ENDPOINT}/api/serve/applications/",
timeout=10
)
if resp.status_code != 200:
logger.error(f"Failed to get applications: {resp.status_code}")
return -1
apps = resp.json().get("applications", {})
if app_name not in apps:
logger.error(f"Application {app_name} not found")
return -1
deployments = apps[app_name].get("deployments", {})
if deployment_name in deployments:
return deployments[deployment_name]["target_num_replicas"]
logger.error(f"Deployment {deployment_name} not found")
return -1
except requests.exceptions.RequestException as e:
logger.error(f"Request failed: {e}")
return -1
def scale_deployment(app_name: str, deployment_name: str):
"""Scale deployment based on time of day."""
hour = datetime.now().hour
current = get_current_replicas(app_name, deployment_name)
# Check if we successfully retrieved the current replica count
if current == -1:
logger.error("Failed to get current replicas, skipping scaling decision")
return
target = 10 if 9 <= hour < 17 else 3 # Peak hours: 9am-5pm
delta = target - current
if delta == 0:
logger.info(f"Already at target ({current} replicas)")
return
action = "Adding" if delta > 0 else "Removing"
logger.info(f"{action} {abs(delta)} replicas ({current} -> {target})")
try:
resp = requests.post(
f"{SERVE_ENDPOINT}/api/v1/applications/{app_name}/deployments/{deployment_name}/scale",
headers={"Content-Type": "application/json"},
json={"target_num_replicas": target},
timeout=10
)
if resp.status_code == 200:
logger.info("Successfully scaled deployment")
else:
logger.error(f"Scale failed: {resp.status_code} - {resp.text}")
except requests.exceptions.RequestException as e:
logger.error(f"Request failed: {e}")
def main():
logger.info(f"Starting predictive scaling for {APPLICATION_NAME}/{DEPLOYMENT_NAME}")
while True:
scale_deployment(APPLICATION_NAME, DEPLOYMENT_NAME)
time.sleep(SCALING_INTERVAL)
The script uses the external scaling API endpoint to scale deployments:
API endpoint:
POST http://localhost:8265/api/v1/applications/{application_name}/deployments/{deployment_name}/scaleRequest body:
{"target_num_replicas": <number>}(must conform to theScaleDeploymentRequestschema)
The scaling client continuously adjusts the number of replicas based on the time of day:
Business hours (9 AM - 5 PM): 10 replicas
Off-peak hours: 3 replicas
Run the example#
Follow these steps to run the complete example:
Start the Ray Serve application with the configuration:
serve run external_scaler_config.yaml
Run the predictive scaling client in a separate terminal:
python external_scaler_predictive_client.py
The client adjusts replica counts automatically based on the time of day. You can monitor the scaling behavior in the Ray dashboard or by checking the application logs.
Important considerations#
Understanding how the external scaler interacts with your deployments helps you build reliable scaling logic:
Idempotent API calls: The scaling API is idempotent. You can safely call it multiple times with the same
target_num_replicasvalue without side effects. This makes it safe to run your scaling logic on a schedule or in response to repeated metric updates.Interaction with serve deploy: When you upgrade your service with
serve deploy, the number of replicas you set through the external scaler API stays intact. This behavior matches what you’d expect from Ray Serve’s built-in autoscaler—deployment updates don’t reset replica counts.Query current replica count: You can get the current number of replicas for any deployment by querying the GET
/applicationsAPI:curl -X GET http://localhost:8265/api/serve/applications/ \
The response follows the
ServeInstanceDetailsschema, which includes anapplicationsfield containing a dictionary with application names as keys. Each application includes detailed information about all its deployments, including current replica counts. Use this information to make informed scaling decisions. For example, you might scale up gradually by adding a percentage of existing replicas rather than jumping to a fixed number.Initial replica count: When you deploy an application for the first time, Ray Serve creates the number of replicas specified in the
num_replicasfield of your deployment configuration. The external scaler can then adjust this count dynamically based on your scaling logic.