Direct streaming#
Lower streaming latency by removing the ingress proxy hop and routing requests directly to model replicas.
Note
Direct streaming is experimental and may change before it becomes stable. It depends on the HAProxy ingress and supports a single model per application. Configure it through the environment variables and request_router_config described in this guide rather than the internal router deployment and endpoints.
By default, every request to a Ray Serve LLM application flows through a separate ingress deployment (OpenAiIngress) before reaching an LLMServer replica. The ingress replica proxies both the request and the streamed response, so each token in a streaming response crosses one extra deployment boundary. The ingress replica’s event loop also handles both the inbound request path (which affects TTFT) and the outbound streamed-token path (which affects TPOT), so the two contend for the same loop under load.
Direct streaming removes that hop. When enabled, the LLMServer deployment itself becomes the HTTP ingress, and HAProxy forwards client traffic straight to the replica that serves it. An ingress request router chooses the replica for each request.
Enable direct streaming#
Direct streaming runs on top of the HAProxy ingress. Set both environment variables before starting Serve:
export RAY_SERVE_ENABLE_HA_PROXY=1
export RAY_SERVE_LLM_ENABLE_DIRECT_STREAMING=1
Then build and deploy a single-model application:
from ray import serve
from ray.serve.llm import LLMConfig, build_openai_app
llm_config = LLMConfig(
model_loading_config={
"model_id": "qwen3.5-0.8b",
"model_source": "Qwen/Qwen3.5-0.8B",
},
deployment_config={
"autoscaling_config": {"min_replicas": 1, "max_replicas": 4},
},
engine_kwargs={
"trust_remote_code": True,
"tensor_parallel_size": 1,
"enable_auto_tool_choice": True,
"tool_call_parser": "qwen3_coder",
"reasoning_parser": "qwen3",
},
)
app = build_openai_app({"llm_configs": [llm_config]})
serve.run(app)
# config.yaml
applications:
- name: llm-direct-streaming
route_prefix: /
import_path: ray.serve.llm:build_openai_app
args:
llm_configs:
- model_loading_config:
model_id: qwen3.5-0.8b
model_source: Qwen/Qwen3.5-0.8B
deployment_config:
autoscaling_config:
min_replicas: 1
max_replicas: 4
engine_kwargs:
trust_remote_code: true
tensor_parallel_size: 1
enable_auto_tool_choice: true
tool_call_parser: qwen3_coder
reasoning_parser: qwen3
Run serve run from a shell where both environment variables are still exported, so the controller enables HAProxy and direct streaming when it builds the application:
serve run config.yaml
The deployed application is OpenAI-compatible and exposes the engine’s native routes, including /v1/chat/completions, /v1/completions, and /v1/models.
To confirm direct streaming is active, check that the application runs two deployments: your model deployment (LLMServer:<model_id>) and an LLMRouter deployment. LLMRouter is the ingress request router. It replaces the standalone OpenAiIngress deployment that fronts a non-direct-streaming app.
Run serve status:
serve status
applications:
default:
status: RUNNING
deployments:
LLMServer:qwen3_5-0_8b:
status: HEALTHY
replica_states:
RUNNING: 1
LLMRouter:
status: HEALTHY
replica_states:
RUNNING: 1
The Serve dashboard shows the same two deployments:
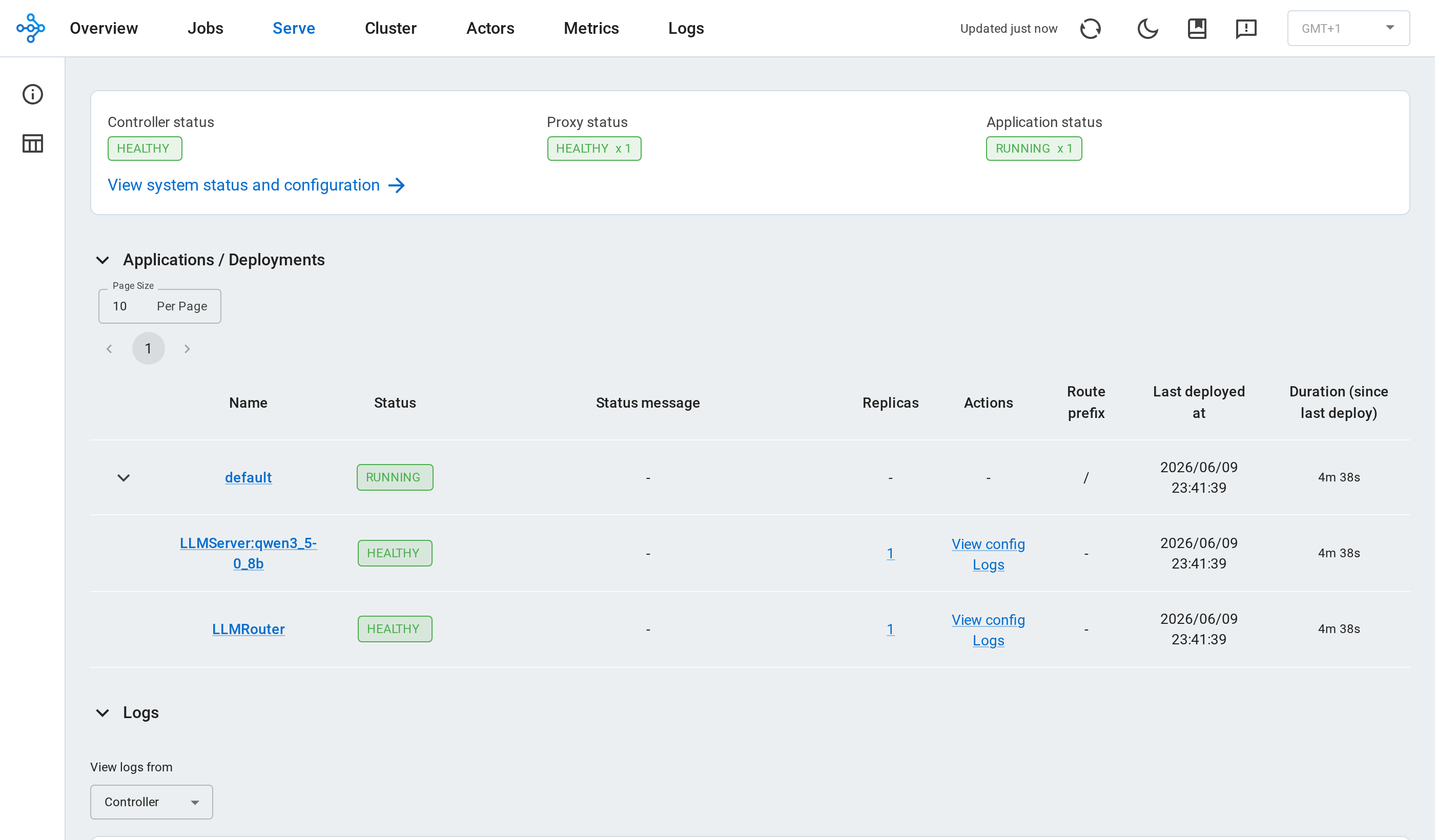
Both deployments appear healthy: the LLMServer model deployment and the LLMRouter ingress request router.#
Tip
Ray Serve sets TCP_NODELAY by default (RAY_SERVE_HAPROXY_TCP_NODELAY=1) so the first streamed chunk isn’t held back by Nagle’s algorithm. Keep it enabled for streaming workloads.
When to use direct streaming#
Direct streaming is an experimental serving path for Ray Serve LLM. Removing the ingress proxy hop cuts per-token overhead on streaming responses, which matters most for long generations and latency-sensitive, high-throughput deployments. Ray intends it to become the default serving path as it matures.
How it works#
Without direct streaming, the request and every streamed token pass through the ingress deployment: Client → HAProxy → OpenAiIngress replica → LLMServer replica → engine.
With direct streaming, the LLMServer deployment is the ingress. HAProxy calls /internal/route on the LLMRouter deployment to choose an LLMServer replica, then sends the request and the streamed response directly to that replica. The replica serves the engine’s own OpenAI-compatible FastAPI app, such as vLLM’s API server, so no separate ingress deployment sits on the response path.
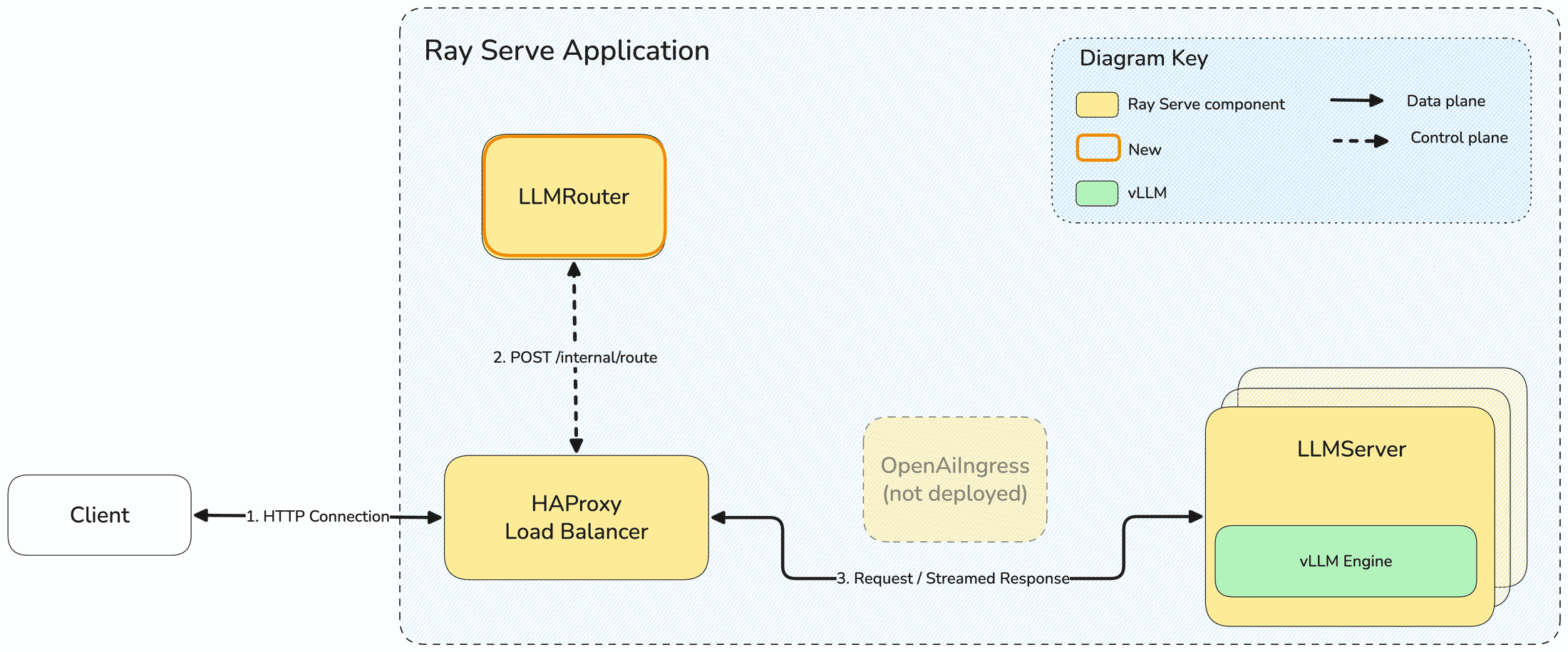
Direct streaming request path.#
Ingress request router#
Ray Serve adds an internal router deployment that answers HAProxy’s routing calls. For each request, HAProxy asks the router which replica to use over an internal endpoint, and the router returns that replica’s backend host and port.
Replica selection reuses the LLMServer deployment’s configured request router, so the same routing policies you would use for any deployment apply here. When you do not configure one, direct streaming defaults to RoundRobinRouter. This differs from Serve’s general default of Power of Two Choices. You control it through the public request_router_config, described in Customize replica selection. The router deployment and its endpoint are internal and may change.
Supported serving patterns#
Direct streaming works with the single-model builders for the OpenAI, data parallel attention, and prefill/decode patterns:
Standard serving (
build_openai_app): theLLMServerdeployment serves the engine app directly.Data parallel attention (
build_dp_openai_app): theDPServerdeployment serves the engine app directly. Use this for wide expert parallelism. See Data parallel attention.Prefill/decode disaggregation (
build_pd_openai_app): the decode server serves the engine app directly. See Prefill/decode disaggregation.
Customize replica selection#
Direct streaming uses the deployment’s request_router_config, so you select a routing policy the same way you would for any LLM deployment. Set it on the model’s deployment_config:
from ray.serve.config import RequestRouterConfig
from ray.serve.llm import LLMConfig
llm_config = LLMConfig(
model_loading_config={
"model_id": "qwen3.5-0.8b",
"model_source": "Qwen/Qwen3.5-0.8B",
},
deployment_config={
"request_router_config": RequestRouterConfig(
request_router_class="ray.serve.experimental.consistent_hash_router.ConsistentHashRouter",
),
},
engine_kwargs={
"trust_remote_code": True,
"tensor_parallel_size": 1,
"enable_auto_tool_choice": True,
"tool_call_parser": "qwen3_coder",
"reasoning_parser": "qwen3",
},
)
If you set request_router_config, direct streaming uses it as-is. Otherwise it falls back to RoundRobinRouter. For the available policies and how to write your own, see Request routing and Use Custom Algorithm for Request Routing.
Body-aware routers#
Some policies score replicas using the request body, for example prefix-aware routing, which keys on the prompt or messages. By default HAProxy doesn’t forward the request body to the router, because buffering and re-emitting large bodies adds time to first token (TTFT). Body-independent policies are unaffected. Round-robin and power of two ignore the body, and session-aware policies key on the header instead.
If your policy needs the body, enable forwarding:
export RAY_SERVE_INGRESS_REQUEST_ROUTER_FORWARD_BODY=1
With forwarding on, HAProxy has to receive and buffer the request body before it can route. That wait adds to TTFT. The more of the body it waits for, the longer routing is delayed and the more memory HAProxy holds. To bound that cost, HAProxy buffers only up to RAY_SERVE_HAPROXY_INGRESS_REQUEST_ROUTER_BUFSIZE bytes. When a request body is larger than that cap, HAProxy stops waiting and routes on the leading bytes it already has. It flags the routing call as carrying a truncated body, so the policy knows it’s scoring against a prefix rather than the full payload.
Truncation affects only the copy sent to the router, not the request forwarded to the replica or the response to the client. The captured portion is always the head of the body, which is what prefix-based policies match on. To tune the cap against real traffic, watch the serve_haproxy_ingress_router_truncations_total metric. Enable the ingress request router metrics with RAY_SERVE_INGRESS_REQUEST_ROUTER_METRICS_ENABLED=1. A high truncation rate means body-aware policies are routing on clipped prompts and may warrant a larger buffer. See HAProxy ingress request router metrics for the full set.
Session affinity#
To pin all turns of a conversation to the same replica, send a session-id header with each request. HAProxy forwards the header to the ingress request router, which passes the session id to the configured policy. Session-aware policies such as ConsistentHashRouter then route every request with the same session id to one replica.
The header name defaults to x-session-id and is configurable with RAY_SERVE_SESSION_ID_HEADER_KEY. Matching is case-insensitive and tolerant of the -/_ substitutions some proxies make.
Limitations#
Single model per application.
build_openai_appraises if you pass more than oneLLMConfigwhile direct streaming is enabled. To serve multiple models, deploy each as its own single-model direct streaming application on a distinct route prefix. Clients then target the per-model endpoint directly instead of selecting the model by themodelfield on one shared endpoint.No LoRA- or multiplex-aware routing. The ingress request router doesn’t forward the requested model or adapter id to the routing policy, so requests aren’t steered to replicas that already have a given LoRA adapter loaded. The default
RoundRobinRouteris multiplex-unaware. A single base model with adapters still serves, but without adapter affinity. If you need adapter-affinity routing, use the default ingress instead, which routes multiplex-aware. See Multi-LoRA deployment. LoRA- and multiplex-aware routing for direct streaming is planned for a future release.
See also#
Request routing - request routing concepts and available policies
Prefix-aware routing - cache-locality routing policy
Use Custom Algorithm for Request Routing - implement a custom request router