Ray Dashboard#
Ray provides a web-based dashboard for monitoring and debugging Ray applications. The visual representation of the system state, allows users to track the performance of applications and troubleshoot issues.
Set up Dashboard#
To access the dashboard, use ray[default] or other installation commands that include the Ray Dashboard component. For example:
pip install -U "ray[default]"
When you start a single-node Ray Cluster on your laptop, access the dashboard with the URL that Ray prints when it initializes (the default URL is http://localhost:8265) or with the context object returned by ray.init.
import ray
context = ray.init()
print(context.dashboard_url)
127.0.0.1:8265
INFO worker.py:1487 -- Connected to Ray cluster. View the dashboard at 127.0.0.1:8265.
Note
If you start Ray in a docker container, --dashboard-host is a required parameter. For example, ray start --head --dashboard-host=0.0.0.0.
When you start a remote Ray Cluster with the VM Cluster Launcher, KubeRay operator, or manual configuration, Ray Dashboard launches on the head node but the dashboard port may not be publicly exposed. View configuring the dashboard for how to view Dashboard from outside the Head Node.
Note
When using the Ray Dashboard, it is highly recommended to also set up Prometheus and Grafana. They are necessary for critical features such as Metrics View. See Configuring and Managing the Dashboard for how to integrate Prometheus and Grafana with Ray Dashboard.
Jobs view#
The Jobs view lets you monitor the different Jobs that ran on your Ray Cluster.
A Ray Job is a Ray workload that uses Ray APIs (e.g., ray.init). It is recommended to submit your Job to Clusters via Ray Job API. You can also interactively run Ray jobs (e.g., by executing a Python script within a Head Node).
The Job view displays a list of active, finished, and failed Jobs, and clicking on an ID allows users to view detailed information about that Job. For more information on Ray Jobs, see the Ray Job Overview section.
Custom names for jobs#
The Name column in the Jobs view displays the value of the job_name key from the Job’s metadata.
You can set it when submitting a Job via the Ray Job API:
from ray.job_submission import JobSubmissionClient
client = JobSubmissionClient("http://127.0.0.1:8265")
client.submit_job(
entrypoint="echo hello",
metadata={"job_name": "my-training-job"},
)
If job_name is not provided in the metadata, it defaults to the job ID. Job names do not need to be unique.
Job Profiling#
You can profile Ray Jobs by clicking on the “Stack Trace” or “CPU Flame Graph” actions. See Profiling for more details.
Task and Actor breakdown#

The Jobs view breaks down Tasks and Actors by their states. Tasks and Actors are grouped and nested by default. You can see the nested entries by clicking the expand button.
Tasks and Actors are grouped and nested using the following criteria:
All Tasks and Actors are grouped together. View individual entries by expanding the corresponding row.
Tasks are grouped by their
nameattribute (e.g.,task.options(name="<name_here>").remote()).Child Tasks (nested Tasks) are nested under their parent Task’s row.
Actors are grouped by their class name.
Child Actors (Actors created within an Actor) are nested under their parent Actor’s row.
Actor Tasks (remote methods within an Actor) are nested under the Actor for the corresponding Actor method.
Note
Job detail page can only display or retrieve up to 10K Tasks per Job. For Jobs with more than 10K Tasks, the portion of Tasks that exceed the 10K limit are unaccounted. The number of unaccounted Tasks is available from the Task breakdown.
Task Timeline#
First, download the chrome tracing file by clicking the download button. Alternatively, you can use CLI or SDK to export the tracing file.
Second, use tools like chrome://tracing or the Perfetto UI and drop the downloaded chrome tracing file. We will use Perfetto as it is the recommended way to visualize chrome tracing files.
In the timeline visualization of Ray Tasks and Actors, there are Node rows (hardware) and Worker rows (processes). Each Worker rows display a list of Task events (e.g., Task scheduled, Task running, input/output deserialization, etc.) happening from that Worker over time.
Ray Status#
The Jobs view displays the status of the Ray Cluster. This information is the output of the ray status CLI command.
The left panel shows the autoscaling status, including pending, active, and failed nodes. The right panel displays the resource demands, which are resources that cannot be scheduled to the Cluster at the moment. This page is useful for debugging resource deadlocks or slow scheduling.
Note
The output shows the aggregated information across the Cluster (not by Job). If you run more than one Job, some of the demands may come from other Jobs.
Task, Actor, and Placement Group tables#
The Dashboard displays a table of the status of the Job’s Tasks, Actors, and Placement Groups. This information is the output of the Ray State APIs.
You can expand the table to see a list of each Task, Actor, and Placement Group.
Serve view#
See your general Serve configurations, a list of the Serve applications, and, if you configured Grafana and Prometheus, high-level metrics of your Serve applications. Click the name of a Serve application to go to the Serve Application Detail page.
Serve Application Detail page#
See the Serve application’s configurations and metadata and the list of Serve deployments and replicas. Click the expand button of a deployment to see the replicas.
Each deployment has two available actions. You can view the Deployment config and, if you configured Grafana and Prometheus, you can open a Grafana dashboard with detailed metrics about that deployment.
For each replica, there are two available actions. You can see the logs of that replica and, if you configured Grafana and Prometheus, you can open a Grafana dashboard with detailed metrics about that replica. Click on the replica name to go to the Serve Replica Detail page.
Serve Replica Detail page#
This page shows metadata about the Serve replica, high-level metrics about the replica if you configured Grafana and Prometheus, and a history of completed Tasks of that replica.
Serve metrics#
Ray Serve exports various time-series metrics to help you understand the status of your Serve application over time. Find more details about these metrics here. To store and visualize these metrics, set up Prometheus and Grafana by following the instructions here.
These metrics are available in the Ray Dashboard in the Serve page and the Serve Replica Detail page. They are also accessible as Grafana dashboards. Within the Grafana dashboard, use the dropdown filters on the top to filter metrics by route, deployment, or replica. Exact descriptions of each graph are available by hovering over the “info” icon on the top left of each graph.
Cluster view#
The Cluster view is a visualization of the hierarchical relationship of machines (nodes) and Workers (processes). Each host machine consists of many Workers, that you can see by clicking the + button. See also the assignment of GPU resources to specific Actors or Tasks.
Click the node ID to see the node detail page.
In addition, the machine view lets you see logs for a node or a Worker.
Actors view#
Use the Actors view to see the logs for an Actor and which Job created the Actor.
The information for up to 100000 dead Actors is stored.
Override this value with the RAY_maximum_gcs_destroyed_actor_cached_count environment variable
when starting Ray.
Actor profiling#
Run the profiler on a running Actor. See Dashboard Profiling for more details.
Actor Detail page#
Click the ID, to see the detail view of the Actor.
On the Actor Detail page, see the metadata, state, and all of the Actor’s Tasks that have run.
Metrics view#
Ray exports default metrics which are available from the Metrics view. Here are some available example metrics.
Tasks, Actors, and Placement Groups broken down by states
Logical resource usage across nodes
Hardware resource usage across nodes
Autoscaler status
See System Metrics Page for available metrics.
Note
The Metrics view requires the Prometheus and Grafana setup. See Configuring and managing the Dashboard to learn how to set up Prometheus and Grafana.
The Metrics view provides visualizations of the time series metrics emitted by Ray.
You can select the time range of the metrics in the top right corner. The graphs refresh automatically every 15 seconds.
There is also a convenient button to open the Grafana UI from the dashboard. The Grafana UI provides additional customizability of the charts.
Analyze the CPU and memory usage of Tasks and Actors#
The Metrics view in the Dashboard provides a “per-component CPU/memory usage graph” that displays CPU and memory usage over time for each Task and Actor in the application (as well as system components). You can identify Tasks and Actors that may be consuming more resources than expected and optimize the performance of the application.
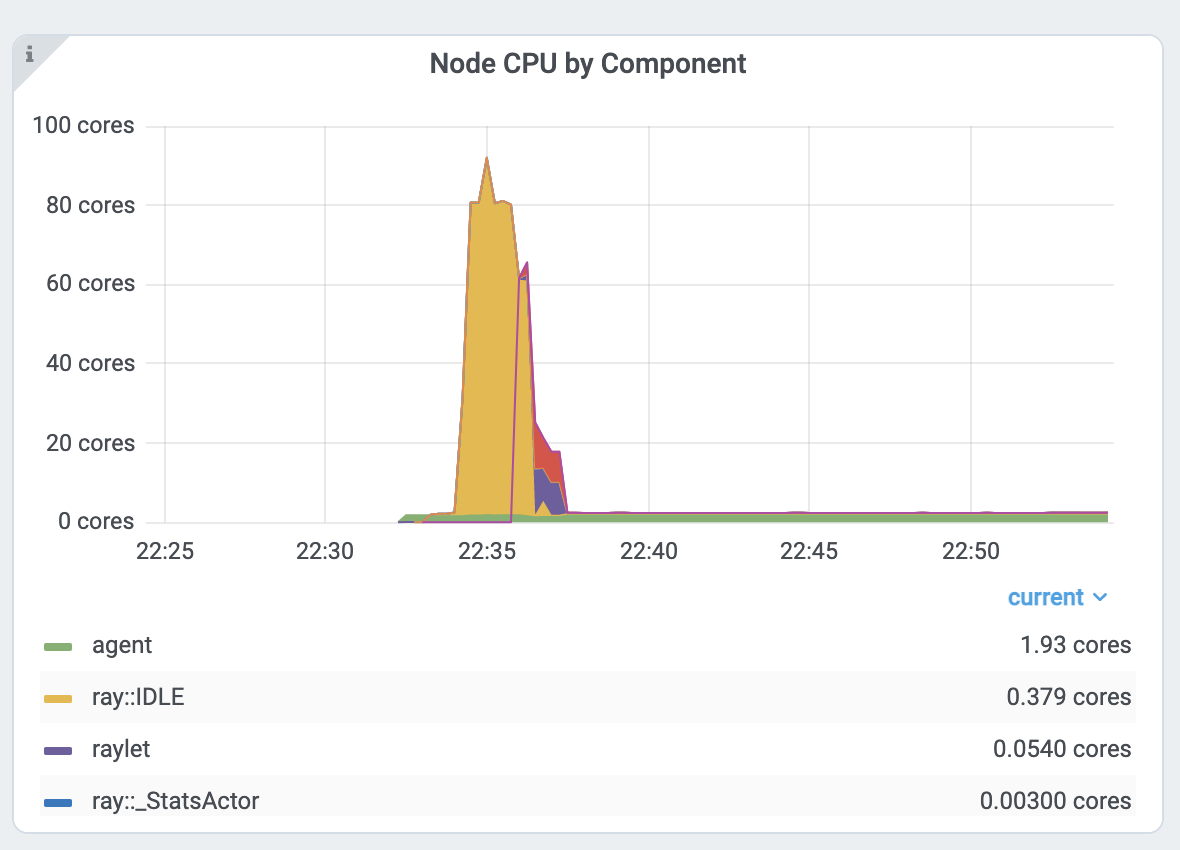
Per component CPU graph. 0.379 cores mean that it uses 40% of a single CPU core. Ray process names start with ray::. raylet, agent, dashboard, or gcs are system components.
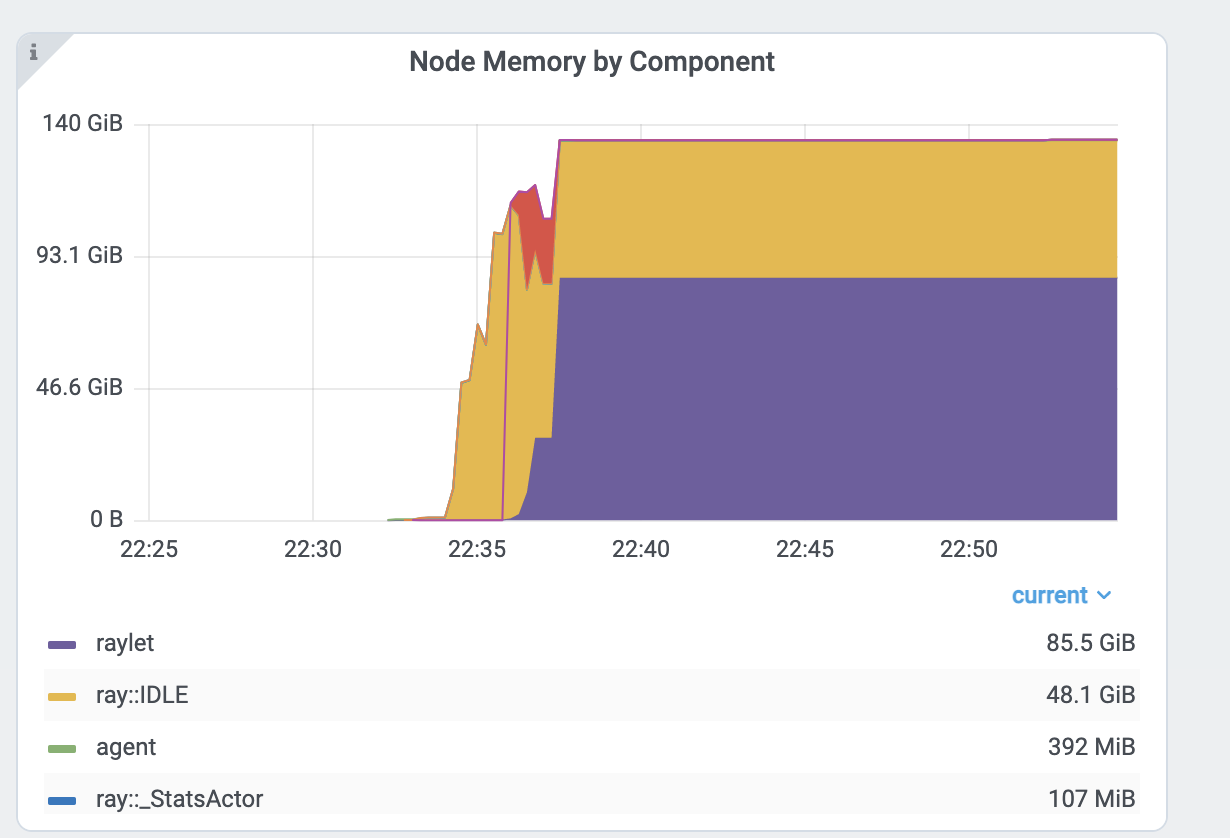
Per component memory graph. Ray process names start with ray::. raylet, agent, dashboard, or gcs are system components.
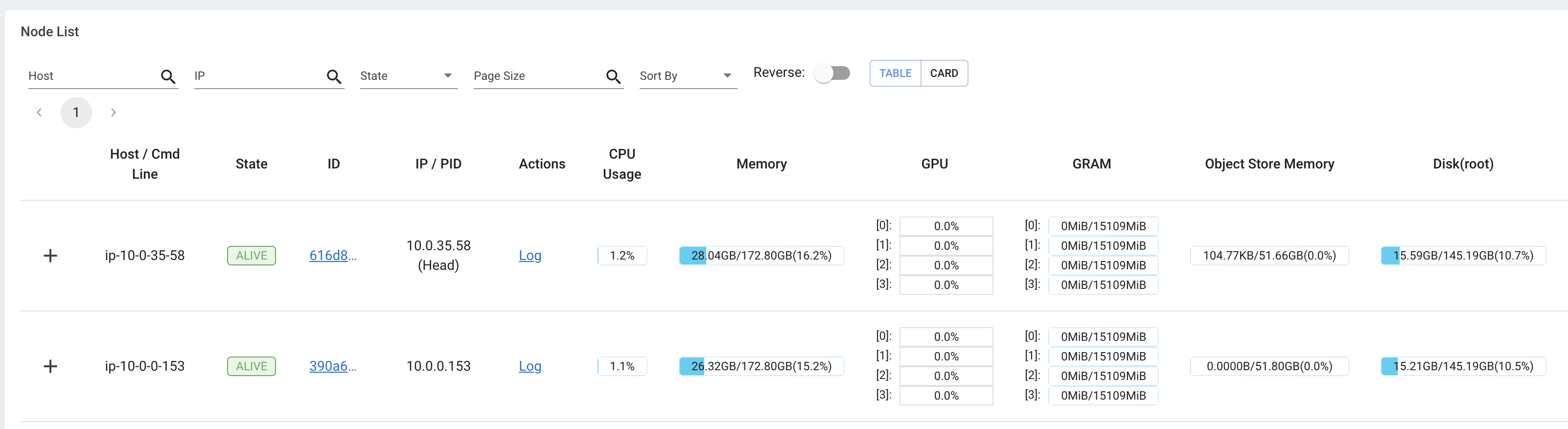
Additionally, users can see a snapshot of hardware utilization from the Cluster view, which provides an overview of resource usage across the entire Ray Cluster.
View the resource utilization#
Ray requires users to specify the number of resources their Tasks and Actors use through arguments such as num_cpus, num_gpus, memory, and resource.
These values are used for scheduling, but may not always match the actual resource utilization (physical resource utilization).
See the logical and physical resource utilization over time from the Metrics view.
The snapshot of physical resource utilization (CPU, GPU, memory, disk, network) is also available from the Cluster view.
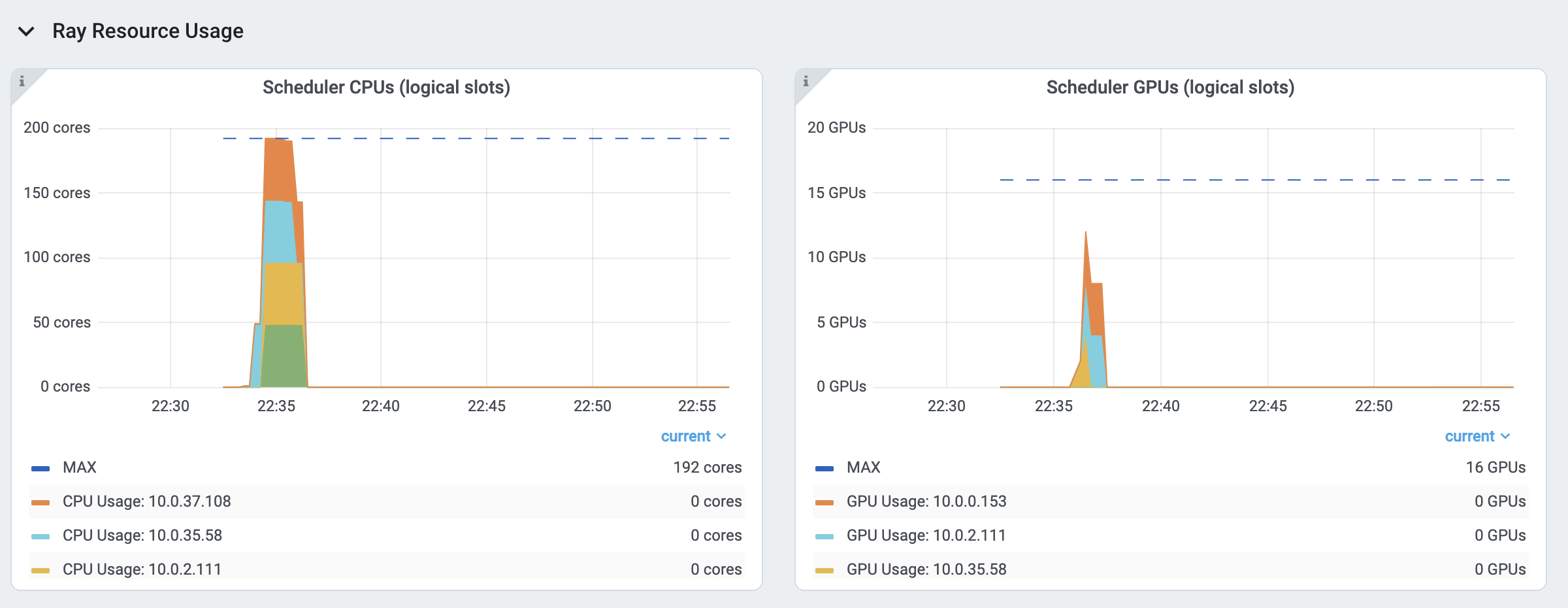
The logical resources usage.
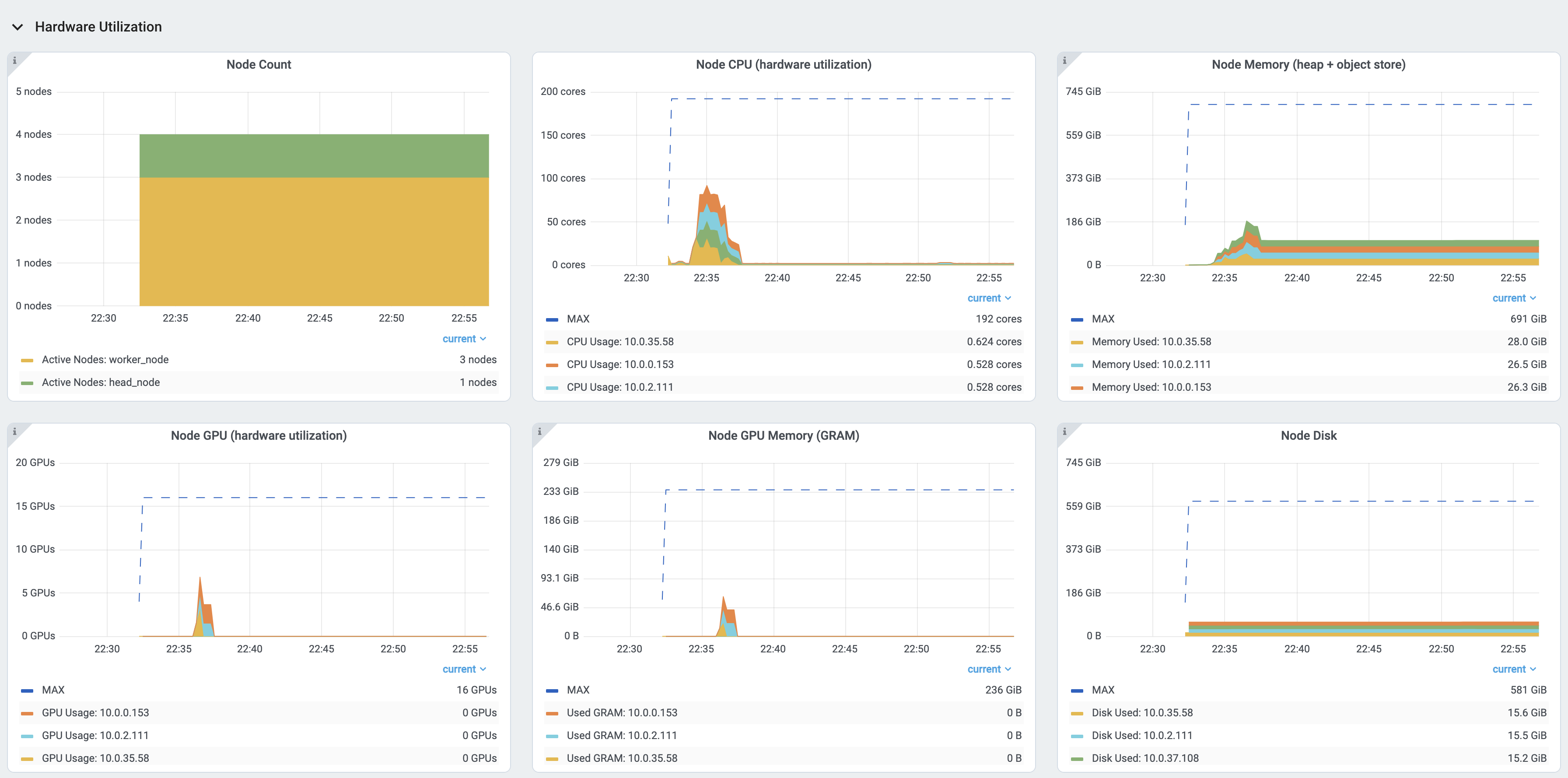
The physical resources (hardware) usage. Ray provides CPU, GPU, Memory, GRAM, disk, and network usage for each machine in a Cluster.
Logs view#
The Logs view lists the Ray logs in your Cluster. It is organized by node and log file name. Many log links in the other pages link to this view and filter the list so the relevant logs appear.
To understand the logging structure of Ray, see logging directory and file structure.
The Logs view provides search functionality to help you find specific log messages.
Driver logs
If the Ray Job is submitted by the Job API, the Job logs are available from the Dashboard. The log file follows the following format: job-driver-<job_submission_id>.log.
Note
If you execute the Driver directly on the Head Node of the Ray Cluster (without using the Job API) or run with Ray Client, the Driver logs are not accessible from the Dashboard. In this case, see the terminal or Jupyter Notebook output to view the Driver logs.
Task and Actor Logs (Worker logs)
Task and Actor logs are accessible from the Task and Actor table view. Click the “Log” button.
You can see the stdout and stderr logs that contain the output emitted from Tasks and Actors.
For Actors, you can also see the system logs for the corresponding Worker process.
Note
Logs of asynchronous Actor Tasks or threaded Actor Tasks (concurrency>1) are only available as part of the Actor logs. Follow the instruction in the Dashboard to view the Actor logs.
Task and Actor errors
You can easily identify failed Tasks or Actors by looking at the Job progress bar.
The Task and Actor tables display the name of the failed Tasks or Actors, respectively. They also provide access to their corresponding log or error messages.
Overview view#
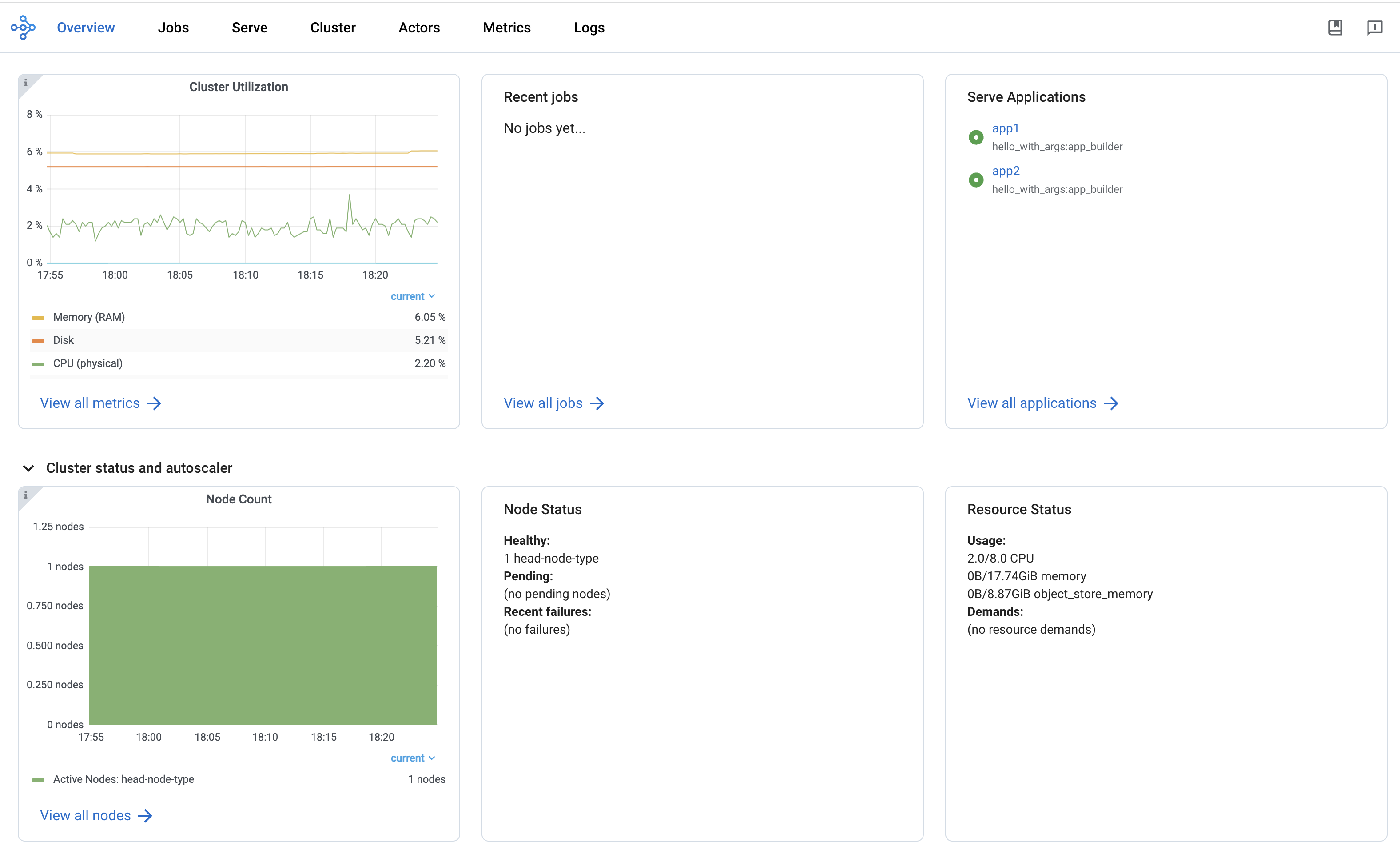
The Overview view provides a high-level status of the Ray Cluster.
Overview metrics
The Overview Metrics page provides the Cluster-level hardware utilization and autoscaling status (number of pending, active, and failed nodes).
Recent Jobs
The Recent Jobs pane provides a list of recently submitted Ray Jobs.
Serve applications
The Serve Applications pane provides a list of recently deployed Serve applications
Events view
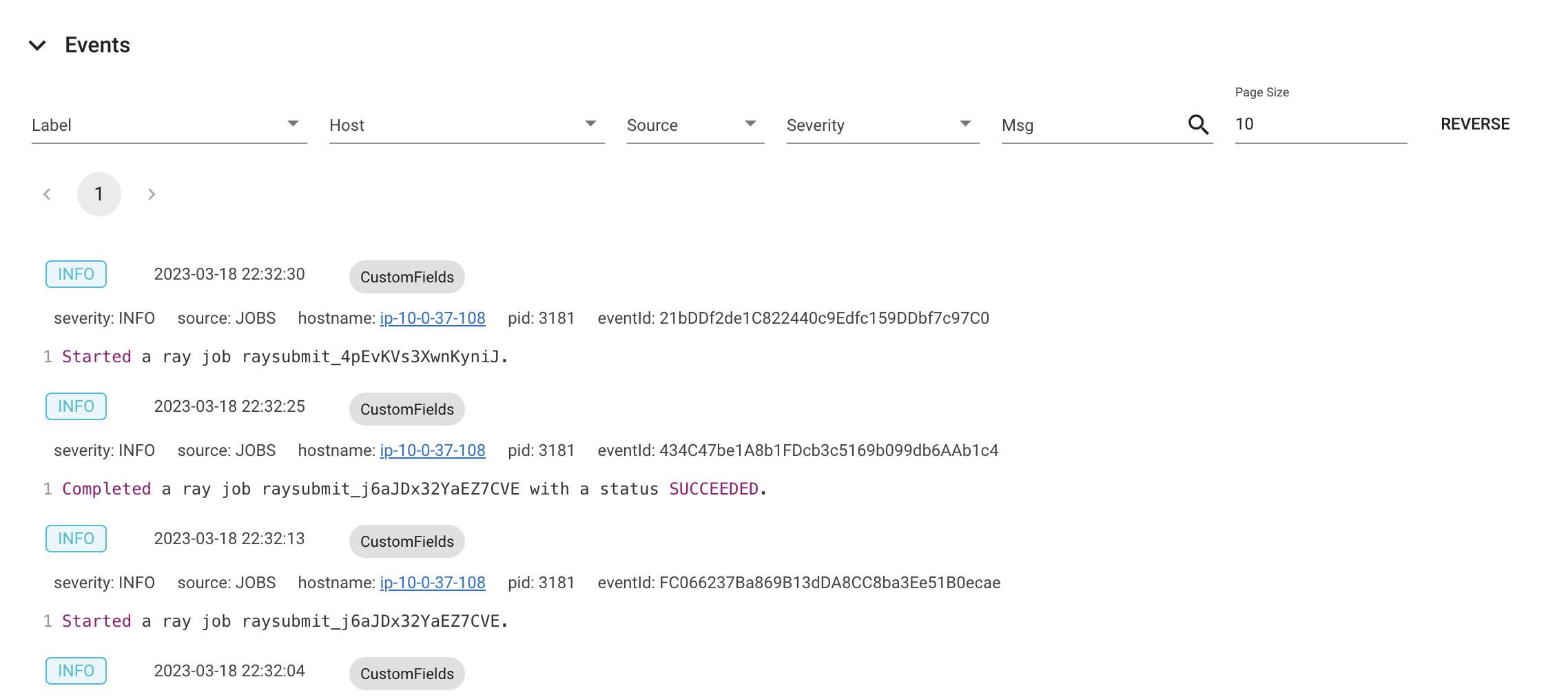
The Events view displays a list of events associated with a specific type (e.g., Autoscaler or Job) in chronological order. The same information is accessible with the ray list cluster-events (Ray state APIs) CLI commands.
Two types of events are available:
Job: Events related to Ray Jobs API.
Autoscaler: Events related to the Ray autoscaler.