Data parallel attention#
Data parallel attention (DP) is a serving pattern that creates multiple inference engine instances to process requests in parallel. This pattern is most useful when you combine it with expert parallelism for sparse MoE models. In this case, the experts are parallelized across multiple machines and attention (QKV) layers are replicated across GPUs, providing an opportunity to shard across requests.
In this serving pattern, engine replicas aren’t isolated. In fact, they need to run in sync with each other to serve a large number of requests concurrently.
Architecture overview#
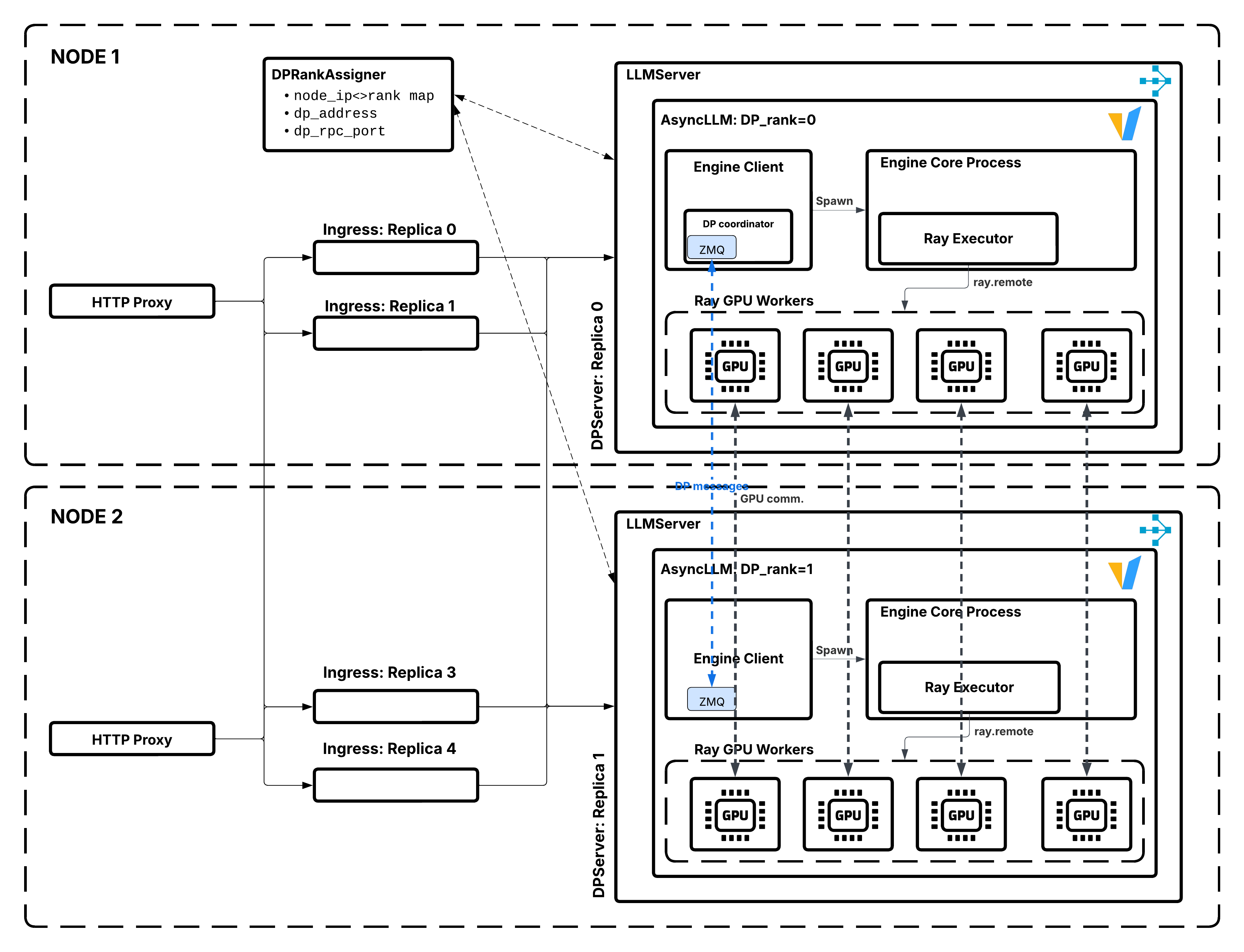
Data parallel attention architecture showing LLMServer replicas coordination.#
In data parallel attention serving:
Ray Serve’s controller creates
data_parallel_sizereplicas as a cohesive gang (i.e. data parallel group), assigning each data parallel replica a unique rank (0 todata_parallel_size-1).Each data parallel replica runs an independent vLLM inference engine with its assigned data parallel rank.
Requests are distributed across replicas through Ray Serve’s routing.
All data parallel replicas carry out GPU collective operations (e.g. dispatch-combine) as a cohesive unit, i.e. data parallel group.
If any data parallel replica fails, the entire data parallel group is restarted atomically.
When to use DP#
Data parallel attention serving works best when:
Large sparse MoE with MLA: Allows reaching larger batch sizes by utilizing the sparsity of the experts more efficiently. MLA (Multi-head Latent Attention) reduces KV cache memory requirements.
High throughput required: You need to serve many concurrent requests.
KV-cache limited: Adding more KV cache capacity increases throughput, so that parallelization of experts could effectively increase the capacity of KV-cache for handling concurrent requests.
When not to use DP#
Consider alternatives when:
Low to medium throughput: If you can’t saturate the MoE layers, don’t use DP.
Non-MLA Attention with sufficient TP: DP is most beneficial with MLA (Multi-head Latent Attention), where KV cache can’t be sharded along the head dimension. For models with GQA (Grouped Query Attention), you can use TP to shard the KV cache up to the degree where
TP_size <= num_kv_heads. Beyond that point, TP requires KV cache replication, which wastes memory—DP becomes a better choice to avoid duplication. For example, for Qwen-235B, usingDP=2, TP=4, EP=8makes more sense thanDP=8, EP=8because you can still shard the KV cache with TP=4 before needing to replicate it. Benchmark these configurations with your workload to determine the optimal setup.Non-MoE models: The main reason for using DP at the cost of this complexity is to lift the effective batch size during decoding for saturating the experts.
Components#
The following are the main components of DP deployments:
DPServer#
DPServer extends LLMServer with data parallel attention coordination. DPServer utilizes Ray Serve’s gang scheduling capability to ensure that all replicas in a DP group start and fail together atomically. In the following sections, we will use “gang” and “DP group” interchangeably. The following pseudocode shows the structure:
from ray import serve
class DPServer(LLMServer):
"""LLM server with data parallel attention coordination."""
async def __init__(self, llm_config: LLMConfig):
# Get rank and gang info from Ray Serve's gang context.
gang_context = serve.get_replica_context().gang_context
self.dp_rank = gang_context.rank
self.gang_id = gang_context.gang_id
# Register and obtain master address / port
if self.dp_rank == 0:
address, rpc_port = get_address_and_port()
GangMasterInfoRegistry.register(self.gang_id, address, rpc_port)
else:
address, rpc_port = await GangMasterInfoRegistry.get(self.gang_id)
# Pass DP metadata to the engine
llm_config.engine_kwargs["data_parallel_rank"] = self.dp_rank
llm_config.engine_kwargs["data_parallel_address"] = address
llm_config.engine_kwargs["data_parallel_rpc_port"] = rpc_port
await super().__init__(llm_config)
@classmethod
def get_deployment_options(cls, llm_config):
options = super().get_deployment_options(llm_config)
dp_size = llm_config.engine_kwargs.get("data_parallel_size", 1)
# Configure gang scheduling for the DP group.
# This tells Ray Serve controller to treat data parallel replicas within a DP group as a cohesive unit.
options["gang_scheduling_config"] = GangSchedulingConfig(
gang_size=dp_size,
gang_placement_strategy=GangPlacementStrategy.PACK,
runtime_failure_policy=GangRuntimeFailurePolicy.RESTART_GANG,
)
return options
Key responsibilities:
Obtain rank and gang identity from Ray Serve’s gang context.
Exchange DP master address/port through
GangMasterInfoRegistry.Coordinate with other replicas for collective operations.
Gracefully handle failures and re-registration.
GangMasterInfoRegistry#
GangMasterInfoRegistry is a GCS-backed KV store, persisting the DP master address and port. The following pseudocode shows the structure:
class GangMasterInfoRegistry:
"""Registry for gang DP master info using GCS KV store."""
@classmethod
def register(cls, gang_id: str, address: str, port: int):
"""Persists address and port associated with a DP group (gang) in the KV store."""
...
@classmethod
async def get(cls, gang_id: str, timeout: float) -> Tuple[str, int]:
"""Polls for address and port for a given DP group."""
...
@classmethod
def unregister(cls, gang_id: str):
"""Remove the DP master info on shutdown."""
...
Key responsibilities:
Store DP master info in GCS KV store.
Provide async polling for non-zero ranks to discover the master.
Clean up entries on shutdown.
Request flow#
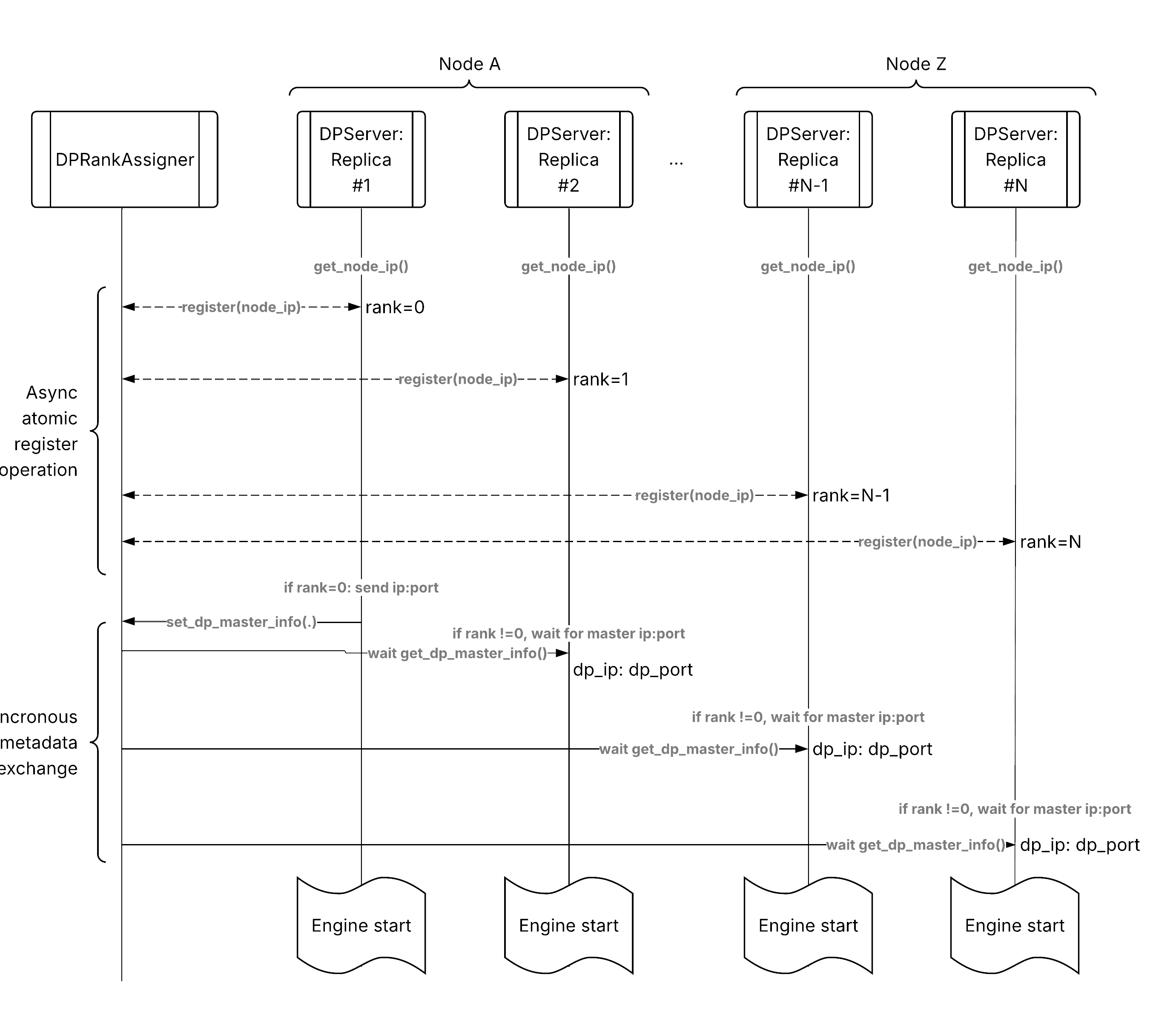
Data parallel attention request flow from client to distributed replicas.#
The following is the request flow through a data parallel attention deployment:
Client request: HTTP request arrives at ingress.
Ingress routing: Ingress uses deployment handle to call
DPServer.Ray Serve routing: Ray Serve’s request router selects a replica.
Default: Power of Two Choices (load balancing).
Custom: Prefix-aware, session-aware, etc.
Replica processing: Selected
DPServerreplica processes request.Engine inference: vLLM engine generates response.
Streaming response: Tokens stream back to client.
The key difference from basic serving is that all the dp_size replicas coordinate with each other rather than in isolation.
Autoscaling#
Autoscaling behavior#
Data parallel attention deployments support autoscaling based on request queue length. Specify min_replicas, max_replicas, and initial_replicas to configure the autoscaling bounds and starting point. All three refer to the number of DP groups, where each group has dp_size engine instances.
config = LLMConfig(
model_loading_config={
"model_id": "microsoft/Phi-tiny-MoE-instruct"
},
deployment_config={
"num_replicas": "auto",
"autoscaling_config": {
"min_replicas": 1, # Min number of DP groups
"max_replicas": 2, # Max number of DP groups
"initial_replicas": 1, # Initial number of DP groups
# Other Ray Serve autoscaling knobs still apply
"upscale_delay_s": 0.1,
"downscale_delay_s": 2,
},
},
engine_kwargs={
"data_parallel_size": 2, # Number of DP replicas
"tensor_parallel_size": 1, # TP size per replica
"max_model_len": 1024,
"max_num_seqs": 32,
},
)
app = build_dp_openai_app({
"llm_config": config
})
Design considerations#
Placement strategy#
DPServer always uses the PACK strategy to place each replica’s resources together:
Tensor parallel workers for one replica pack on the same node when possible.
Different replicas can be on different nodes.
This minimizes inter-node communication within each replica.
Fault tolerance#
If any DP replica in a DP group fails, Ray Serve controller restarts the entire DP group atomically. This ensures all replicas in a group are always in a consistent state, which is critical because DP replicas perform collective operations together.
Combining with other patterns#
DP + Prefill-decode disaggregation#
You can run data parallel attention on both prefill and decode phases:

Combined DP + PD architecture: each phase has its own gang-scheduled DP group.#
Each phase can have an independent data_parallel_size. PDDecodeServer orchestrates remote prefill then runs decode locally.
See also#
Architecture overview - High-level architecture overview
Core components - Core components and protocols
Prefill-decode disaggregation - Prefill-decode disaggregation architecture
Request routing - Request routing architecture