Distributed Data Processing in Data-Juicer#

Data-Juicer supports large-scale distributed data processing based on Ray and Platform for AI of Alibaba Cloud.
With a dedicated design, you can seamlessly execute almost all operators that Data-Juicer implements in standalone mode, in Ray distributed mode. The Data-Juicer team continuously conducts engine-specific optimizations for large-scale scenarios, such as data subset splitting strategies that balance the number of files and workers, and streaming I/O patches for JSON files to Ray and Apache Arrow.
For reference, in experiments with 25 to 100 Alibaba Cloud nodes, Data-Juicer in Ray mode processes datasets containing 70 billion samples on 6400 CPU cores in 2 hours and 7 billion samples on 3200 CPU cores in 0.45 hours. Additionally, a MinHash-LSH-based deduplication operator in Ray mode can deduplicate terabyte-sized datasets on 8 nodes with 1280 CPU cores in 3 hours.
See the Data-Juicer 2.0: Cloud-Scale Adaptive Data Processing for Foundation Models paper for more details.
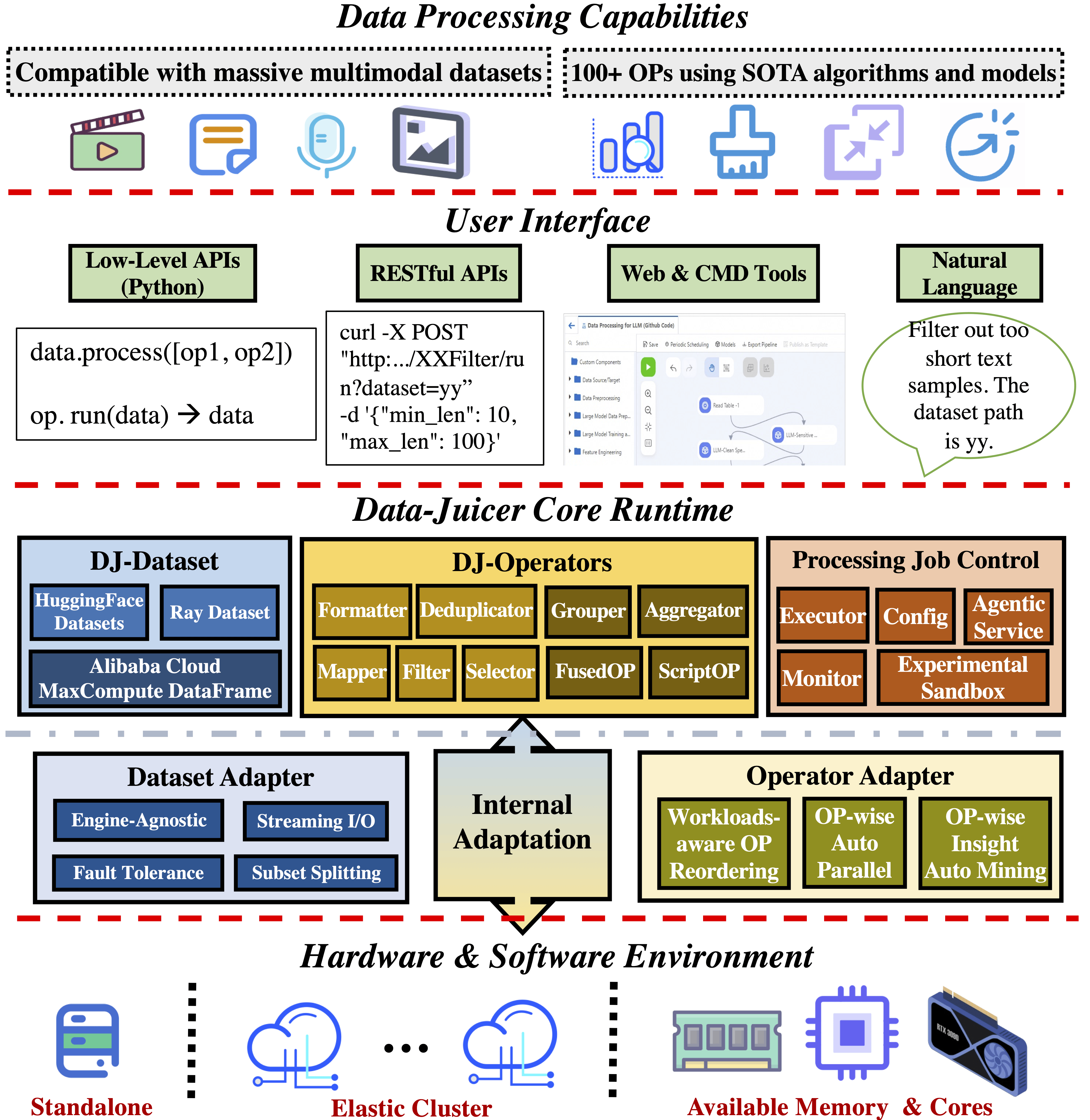
Implementation and optimizations#
Ray mode in Data-Juicer#
For most implementations of Data-Juicer operators, the core processing functions are engine-agnostic. Operators manage interoperability is primarily in RayDataset and RayExecutor, which are subclasses of the base
DJDatasetandBaseExecutor, respectively, and support both Ray Tasks and Actors.The exception is the deduplication operators, which are challenging to scale in standalone mode. The names of these operators follow the pattern of
ray_xx_deduplicator.
Subset splitting#
When a cluster has tens of thousands of nodes but only a few dataset files, Ray splits the dataset files according to available resources and distribute the blocks across all nodes, incurring high network communication costs and reduced CPU utilization. For more details, see Ray’s _autodetect_parallelism function and tuning output blocks for Ray.
This default execution plan can be quite inefficient especially for scenarios with a large number of nodes. To optimize performance for such cases, Data-Juicer automatically splits the original dataset into smaller files in advance, taking into consideration the features of Ray and Arrow. When you encounter such performance issues, you can use this feature or split the dataset according to your own preferences. In this auto-split strategy, the single file size is about 128 MB, and the result should ensure that the number of sub-files after splitting is at least twice the total number of CPU cores available in the cluster.
Streaming reading of JSON files#
Streaming reading of JSON files is a common requirement in data processing for foundation models, as many datasets are in JSONL format and large in size. However, the current implementation in Ray Datasets, which depends on the underlying Arrow library (up to Ray version 2.40 and Arrow version 18.1.0), doesn’t support streaming reading of JSON files.
To address the lack of native support for streaming JSON data, the Data-Juicer team developed a streaming loading interface and contributed an in-house patch for Apache Arrow (PR to the repository). This patch helps alleviate Out-of-Memory issues. With this patch, Data-Juicer in Ray mode, by default, uses the streaming loading interface to load JSON files. In addition, streaming-read support for CSV and Parquet files is already enabled.
Deduplication#
Data-Juicer provides an optimized MinHash-LSH-based deduplication operator in Ray mode. It’s a multiprocessing Union-Find set in Ray Actors and a load-balanced distributed algorithm, BTS, to complete equivalence class merging. This operator can deduplicate terabyte-sized datasets on 1280 CPU cores in 3 hours. The Data-Juicer team’s ablation study shows 2x to 3x speedups with their dedicated optimizations for Ray mode compared to the vanilla version of this deduplication operator.
Performance results#
Data Processing with Varied Scales#
Data-Juicer team conducted experiments on datasets with billions of samples. They prepared a 560k-sample multimodal dataset and expanded it by different factors (1x to 125000x) to create datasets of varying sizes. The experimental results, shown in the figure below, demonstrate good scalability.
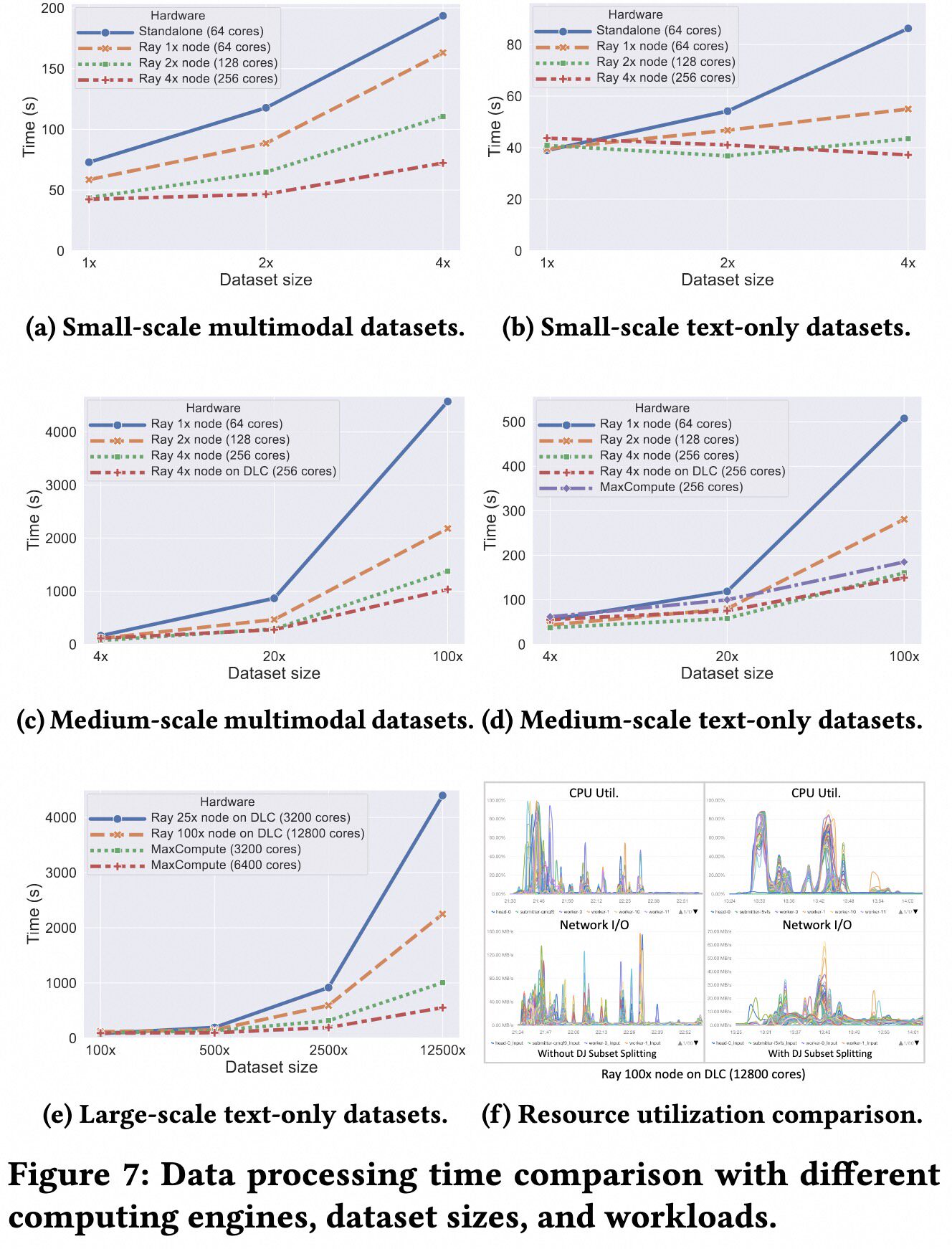
Distributed Deduplication on Large-Scale Datasets#
Data-Juicer team tested the MinHash-based RayDeduplicator on datasets sized at 200 GB, 1 TB, and 5 TB, using CPU counts ranging from 640 to 1280 cores. As the table below shows, when the data size increases by 5x, the processing time increases by 4.02x to 5.62x. When the number of CPU cores doubles, the processing time decreases to 58.9% to 67.1% of the original time.
# CPU |
200 GB Time |
1 TB Time |
5 TB Time |
|---|---|---|---|
4 * 160 |
11.13 min |
50.83 min |
285.43 min |
8 * 160 |
7.47 min |
30.08 min |
168.10 min |
Quick Start#
Before starting, you should install Data-Juicer and its dist requirements:
pip install -v -e . # Install the minimal requirements of Data-Juicer
pip install -v -e ".[dist]" # Include dependencies on Ray and other distributed libraries
Then start a Ray cluster (ref to the Ray doc for more details):
# Start a cluster as the head node
ray start --head
# (Optional) Connect to the cluster on other nodes/machines.
ray start --address='{head_ip}:6379'
Data-Juicer provides simple demos in the directory demos/process_on_ray/, which includes two config files and two test datasets.
demos/process_on_ray
├── configs
│ ├── demo.yaml
│ └── dedup.yaml
└── data
├── demo-dataset.json
└── demo-dataset.jsonl
Important: If you run these demos on multiple nodes, you need to put the demo dataset to a shared disk (for example, Network-attached storage) and export the result dataset to it as well by modifying the
dataset_pathandexport_pathin the config files.
Running Example of Ray Mode#
In the demo.yaml config file, it sets the executor type to “ray” and specify an automatic Ray address.
...
dataset_path: './demos/process_on_ray/data/demo-dataset.jsonl'
export_path: './outputs/demo/demo-processed'
executor_type: 'ray' # Set the executor type to "ray"
ray_address: 'auto' # Set an automatic Ray address
...
Run the demo to process the dataset with 12 regular OPs:
# Run the tool from source
python tools/process_data.py --config demos/process_on_ray/configs/demo.yaml
# Use the command-line tool
dj-process --config demos/process_on_ray/configs/demo.yaml
Data-Juicer processes the demo dataset with the demo config file and export the result datasets to the directory specified by the export_path argument in the config file.
Running Example of Distributed Deduplication#
In the dedup.yaml config file, it sets the executor type to “ray” and specify an automatic Ray address.
And it uses a dedicated distributed version of MinHash deduplication operator to deduplicate the dataset.
project_name: 'demo-dedup'
dataset_path: './demos/process_on_ray/data/'
export_path: './outputs/demo-dedup/demo-ray-bts-dedup-processed'
executor_type: 'ray' # Set the executor type to "ray"
ray_address: 'auto' # Set an automatic Ray address
# process schedule
# a list of several process operators with their arguments
process:
- ray_bts_minhash_deduplicator: # a distributed version of minhash deduplicator
tokenization: 'character'
Run the demo to deduplicate the dataset:
# Run the tool from source
python tools/process_data.py --config demos/process_on_ray/configs/dedup.yaml
# Use the command-line tool
dj-process --config demos/process_on_ray/configs/dedup.yaml
Data-Juicer deduplicates the demo dataset with the demo config file and export the result datasets to the directory specified by the export_path argument in the config file.