Running Distributed Experiments with Ray Tune#
Tune is commonly used for large-scale distributed hyperparameter optimization. This page will overview how to setup and launch a distributed experiment along with commonly used commands for Tune when running distributed experiments.
Summary#
To run a distributed experiment with Tune, you need to:
First, start a Ray cluster if you have not already.
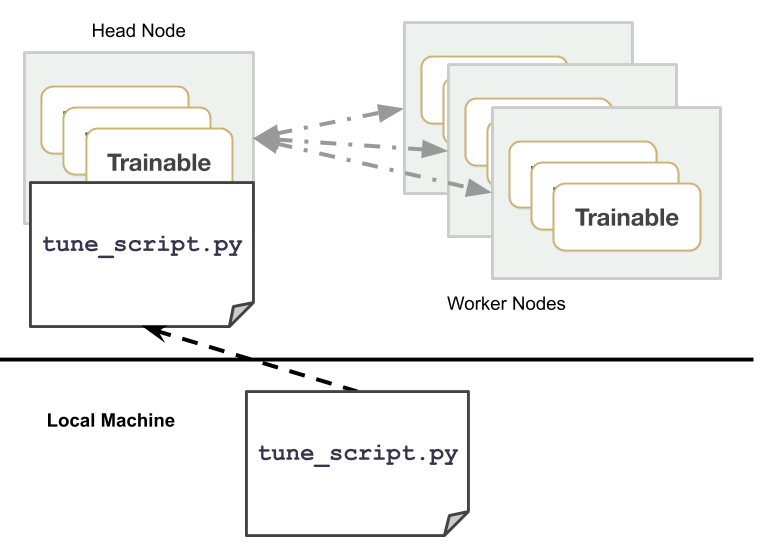
Run the script on the head node, or use ray submit, or use Ray Job Submission.
Example: Distributed Tune on AWS VMs#
Follow the instructions below to launch nodes on AWS (using the Deep Learning AMI). See the cluster setup documentation. Save the below cluster configuration (tune-default.yaml):
cluster_name: tune-default
provider: {type: aws, region: us-west-2}
auth: {ssh_user: ubuntu}
min_workers: 3
max_workers: 3
# Deep Learning AMI (Ubuntu) Version 21.0
available_node_types:
head_node:
node_config: {InstanceType: c5.xlarge, ImageId: ami-0b294f219d14e6a82}
worker_nodes:
node_config: {InstanceType: c5.xlarge, ImageId: ami-0b294f219d14e6a82}
head_node_type: head_node
setup_commands: # Set up each node.
- pip install ray torch torchvision tensorboard
ray up starts Ray on the cluster of nodes.
ray up tune-default.yaml
ray submit --start starts a cluster as specified by the given cluster configuration YAML file, uploads tune_script.py to the cluster, and runs python tune_script.py [args].
ray submit tune-default.yaml tune_script.py --start -- --ray-address=localhost:6379
Analyze your results on TensorBoard by starting TensorBoard on the remote head machine.
# Go to http://localhost:6006 to access TensorBoard.
ray exec tune-default.yaml 'tensorboard --logdir=~/ray_results/ --port 6006' --port-forward 6006
Note that you can customize the directory of results by specifying: RunConfig(storage_path=..), taken in by Tuner. You can then point TensorBoard to that directory to visualize results. You can also use awless for easy cluster management on AWS.
Running a Distributed Tune Experiment#
Running a distributed (multi-node) experiment requires Ray to be started already. You can do this on local machines or on the cloud.
Across your machines, Tune will automatically detect the number of GPUs and CPUs without you needing to manage CUDA_VISIBLE_DEVICES.
To execute a distributed experiment, call ray.init(address=XXX) before Tuner.fit(), where XXX is the Ray address, which defaults to localhost:6379. The Tune python script should be executed only on the head node of the Ray cluster.
One common approach to modifying an existing Tune experiment to go distributed is to set an argparse variable so that toggling between distributed and single-node is seamless.
import ray
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--address")
args = parser.parse_args()
ray.init(address=args.address)
tuner = tune.Tuner(...)
tuner.fit()
# On the head node, connect to an existing ray cluster
$ python tune_script.py --ray-address=localhost:XXXX
If you used a cluster configuration (starting a cluster with ray up or ray submit --start), use:
ray submit tune-default.yaml tune_script.py -- --ray-address=localhost:6379
Tip
In the examples, the Ray address commonly used is
localhost:6379.If the Ray cluster is already started, you should not need to run anything on the worker nodes.
Storage Options in a Distributed Tune Run#
In a distributed experiment, you should try to use cloud checkpointing to
reduce synchronization overhead. For this, you just have to specify a remote storage_path in the
RunConfig.
my_trainable is a user-defined Tune Trainable in the following example:
from ray import tune
from my_module import my_trainable
tuner = tune.Tuner(
my_trainable,
run_config=tune.RunConfig(
name="experiment_name",
storage_path="s3://bucket-name/sub-path/",
)
)
tuner.fit()
For more details or customization, see our guide on configuring storage in a distributed Tune experiment.
Tune Runs on preemptible instances#
Running on spot instances (or preemptible instances) can reduce the cost of your experiment. You can enable spot instances in AWS via the following configuration modification:
# Provider-specific config for worker nodes, e.g. instance type.
worker_nodes:
InstanceType: m5.large
ImageId: ami-0b294f219d14e6a82 # Deep Learning AMI (Ubuntu) Version 21.0
# Run workers on spot by default. Comment this out to use on-demand.
InstanceMarketOptions:
MarketType: spot
SpotOptions:
MaxPrice: 1.0 # Max Hourly Price
In GCP, you can use the following configuration modification:
worker_nodes:
machineType: n1-standard-2
disks:
- boot: true
autoDelete: true
type: PERSISTENT
initializeParams:
diskSizeGb: 50
# See https://cloud.google.com/compute/docs/images for more images
sourceImage: projects/deeplearning-platform-release/global/images/family/tf-1-13-cpu
# Run workers on preemtible instances.
scheduling:
- preemptible: true
Spot instances may be pre-empted suddenly while trials are still running. Tune allows you to mitigate the effects of this by preserving the progress of your model training through checkpointing.
search_space = {
"lr": tune.sample_from(lambda spec: 10 ** (-10 * np.random.rand())),
"momentum": tune.uniform(0.1, 0.9),
}
tuner = tune.Tuner(
TrainMNIST,
run_config=tune.RunConfig(stop={"training_iteration": 10}),
param_space=search_space,
)
results = tuner.fit()
Example for Using Tune with Spot instances (AWS)#
Here is an example for running Tune on spot instances. This assumes your AWS credentials have already been setup (aws configure):
Download a full example Tune experiment script here. This includes a Trainable with checkpointing:
mnist_pytorch_trainable.py. To run this example, you will need to install the following:
$ pip install ray torch torchvision filelock
Download an example cluster yaml here:
tune-default.yamlRun
ray submitas below to run Tune across them. Append[--start]if the cluster is not up yet. Append[--stop]to automatically shutdown your nodes after running.
ray submit tune-default.yaml mnist_pytorch_trainable.py --start -- --ray-address=localhost:6379
Optionally for testing on AWS or GCP, you can use the following to kill a random worker node after all the worker nodes are up
$ ray kill-random-node tune-default.yaml --hard
To summarize, here are the commands to run:
wget https://raw.githubusercontent.com/ray-project/ray/master/python/ray/tune/examples/mnist_pytorch_trainable.py
wget https://raw.githubusercontent.com/ray-project/ray/master/python/ray/tune/tune-default.yaml
ray submit tune-default.yaml mnist_pytorch_trainable.py --start -- --ray-address=localhost:6379
# wait a while until after all nodes have started
ray kill-random-node tune-default.yaml --hard
You should see Tune eventually continue the trials on a different worker node. See the Fault Tolerance section for more details.
You can also specify storage_path=..., as part of RunConfig, which is taken in by Tuner, to upload results to cloud storage like S3, allowing you to persist results in case you want to start and stop your cluster automatically.
Fault Tolerance of Tune Runs#
Tune automatically restarts trials in the case of trial failures (if max_failures != 0),
both in the single node and distributed setting.
For example, let’s say a node is pre-empted or crashes while a trial is still executing on that node. Assuming that a checkpoint for this trial exists (and in the distributed setting, some form of persistent storage is configured to access the trial’s checkpoint), Tune waits until available resources are available to begin executing the trial again from where it left off. If no checkpoint is found, the trial will restart from scratch. See here for information on checkpointing.
If the trial or actor is then placed on a different node, Tune automatically pushes the previous checkpoint file to that node and restores the remote trial actor state, allowing the trial to resume from the latest checkpoint even after failure.
Recovering From Failures#
Tune automatically persists the progress of your entire experiment (a Tuner.fit() session), so if an experiment crashes or is otherwise cancelled, it can be resumed through restore().
Common Tune Commands#
Below are some commonly used commands for submitting experiments. Please see the Clusters page to see find more comprehensive documentation of commands.
# Upload `tune_experiment.py` from your local machine onto the cluster. Then,
# run `python tune_experiment.py --address=localhost:6379` on the remote machine.
$ ray submit CLUSTER.YAML tune_experiment.py -- --address=localhost:6379
# Start a cluster and run an experiment in a detached tmux session,
# and shut down the cluster as soon as the experiment completes.
# In `tune_experiment.py`, set `RunConfig(storage_path="s3://...")`
# to persist results
$ ray submit CLUSTER.YAML --tmux --start --stop tune_experiment.py -- --address=localhost:6379
# To start or update your cluster:
$ ray up CLUSTER.YAML [-y]
# Shut-down all instances of your cluster:
$ ray down CLUSTER.YAML [-y]
# Run TensorBoard and forward the port to your own machine.
$ ray exec CLUSTER.YAML 'tensorboard --logdir ~/ray_results/ --port 6006' --port-forward 6006
# Run Jupyter Lab and forward the port to your own machine.
$ ray exec CLUSTER.YAML 'jupyter lab --port 6006' --port-forward 6006
# Get a summary of all the experiments and trials that have executed so far.
$ ray exec CLUSTER.YAML 'tune ls ~/ray_results'
# Upload and sync file_mounts up to the cluster with this command.
$ ray rsync-up CLUSTER.YAML
# Download the results directory from your cluster head node to your local machine on ``~/cluster_results``.
$ ray rsync-down CLUSTER.YAML '~/ray_results' ~/cluster_results
# Launching multiple clusters using the same configuration.
$ ray up CLUSTER.YAML -n="cluster1"
$ ray up CLUSTER.YAML -n="cluster2"
$ ray up CLUSTER.YAML -n="cluster3"
Troubleshooting#
Sometimes, your program may freeze. Run this to restart the Ray cluster without running any of the installation commands.
$ ray up CLUSTER.YAML --restart-only