Best Practices for Storage and Dependencies#
This document contains recommendations for setting up storage and handling application dependencies for your Ray deployment on Kubernetes.
When you set up Ray on Kubernetes, the KubeRay documentation provides an overview of how to configure the operator to execute and manage the Ray cluster lifecycle. However, as administrators you may still have questions with respect to actual user workflows. For example:
How do you ship or run code on the Ray cluster?
What type of storage system should you set up for artifacts?
How do you handle package dependencies for your application?
The answers to these questions vary between development and production. This table summarizes the recommended setup for each situation:
Interactive Development |
Production |
|
|---|---|---|
Cluster Configuration |
KubeRay YAML |
KubeRay YAML |
Code |
Run driver or Jupyter notebook on head node |
Bake code into Docker image |
Artifact Storage |
Set up an EFS |
Set up an EFS |
Package Dependencies |
Install onto NFS |
Bake into Docker image |
Table 1: Table comparing recommended setup for development and production.
Interactive development#
To provide an interactive development environment for data scientists and ML practitioners, we recommend setting up the code, storage, and dependencies in a way that reduces context switches for developers and shortens iteration times.
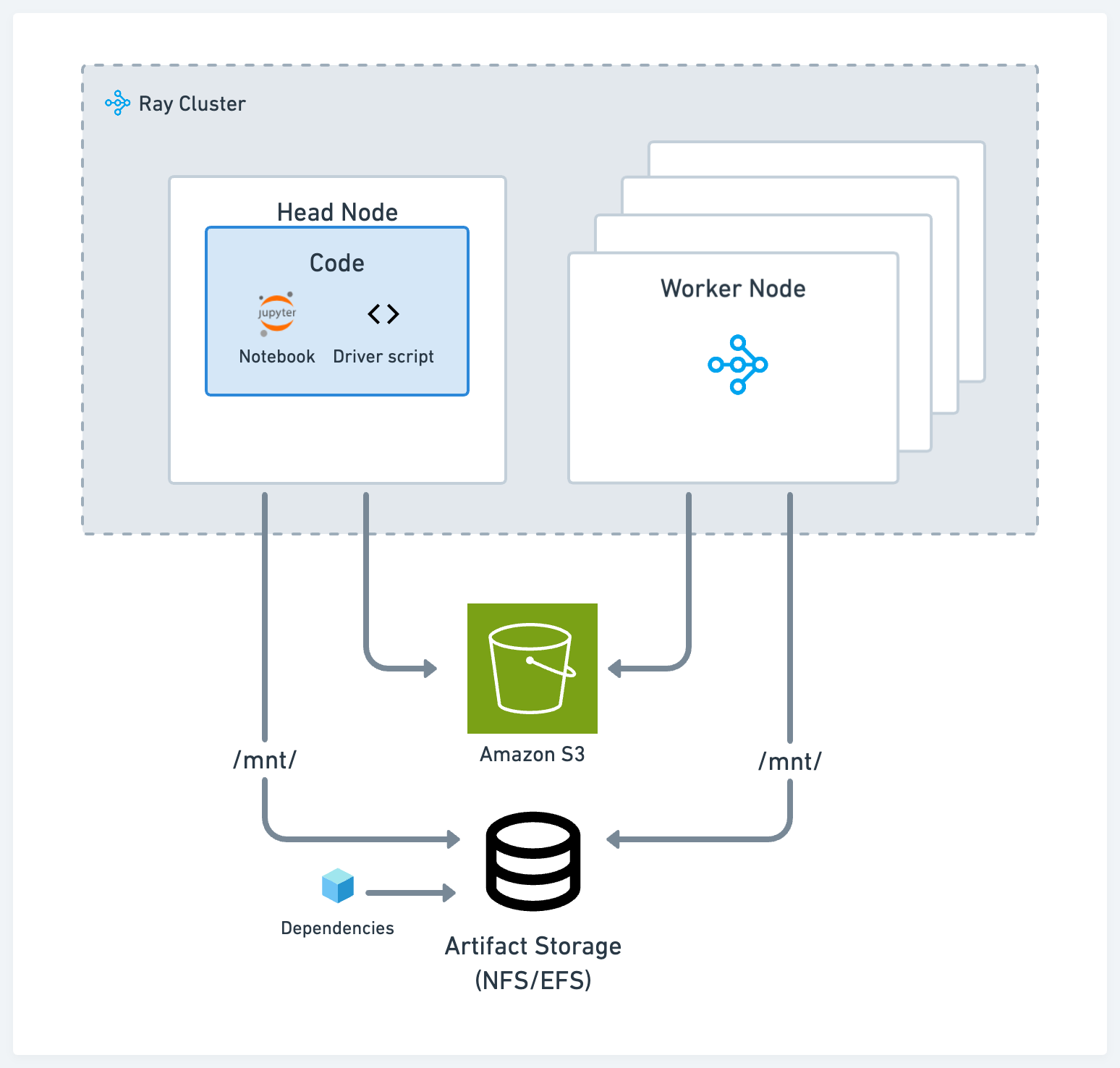
Storage#
Use one of these two standard solutions for artifact and log storage during the development process, depending on your use case:
POSIX-compliant network file storage, like Network File System (NFS) and Elastic File Service (EFS): This approach is useful when you want to have artifacts or dependencies accessible across different nodes with low latency. For example, experiment logs of different models trained on different Ray tasks.
Cloud storage, like AWS Simple Storage Service (S3) or GCP Google Storage (GS): This approach is useful for large artifacts or datasets that you need to access with high throughput.
Ray’s AI libraries such as Ray Data, Ray Train, and Ray Tune come with out-of-the-box capabilities to read and write from cloud storage and local or networked storage.
Driver script#
Run the main, or driver, script on the head node of the cluster. Ray Core and library programs often assume that the driver is on the head node and take advantage of the local storage. For example, Ray Tune generates log files on the head node by default.
A typical workflow can look like this:
Start a Jupyter server on the head node
SSH onto the head node and run the driver script or application there
Use the Ray Job Submission client to submit code from a local machine onto a cluster
Dependencies#
For local dependencies, for example, if you’re working in a mono-repo, or external dependencies, like a pip package, use one of the following options:
Put the code and install the packages onto your NFS. The benefit is that you can quickly interact with the rest of the codebase and dependencies without shipping it across a cluster every time.
Use the runtime env with the Ray Job Submission Client, which can pull down code from S3 or ship code from your local working directory onto the remote cluster.
Bake remote and local dependencies into a published Docker image for all nodes to use. See Custom Docker Images. This approach is the most common way to deploy applications onto Kubernetes, but it’s also the highest friction option.
Production#
The recommendations for production align with standard Kubernetes best practices. See the configuration in the following image:
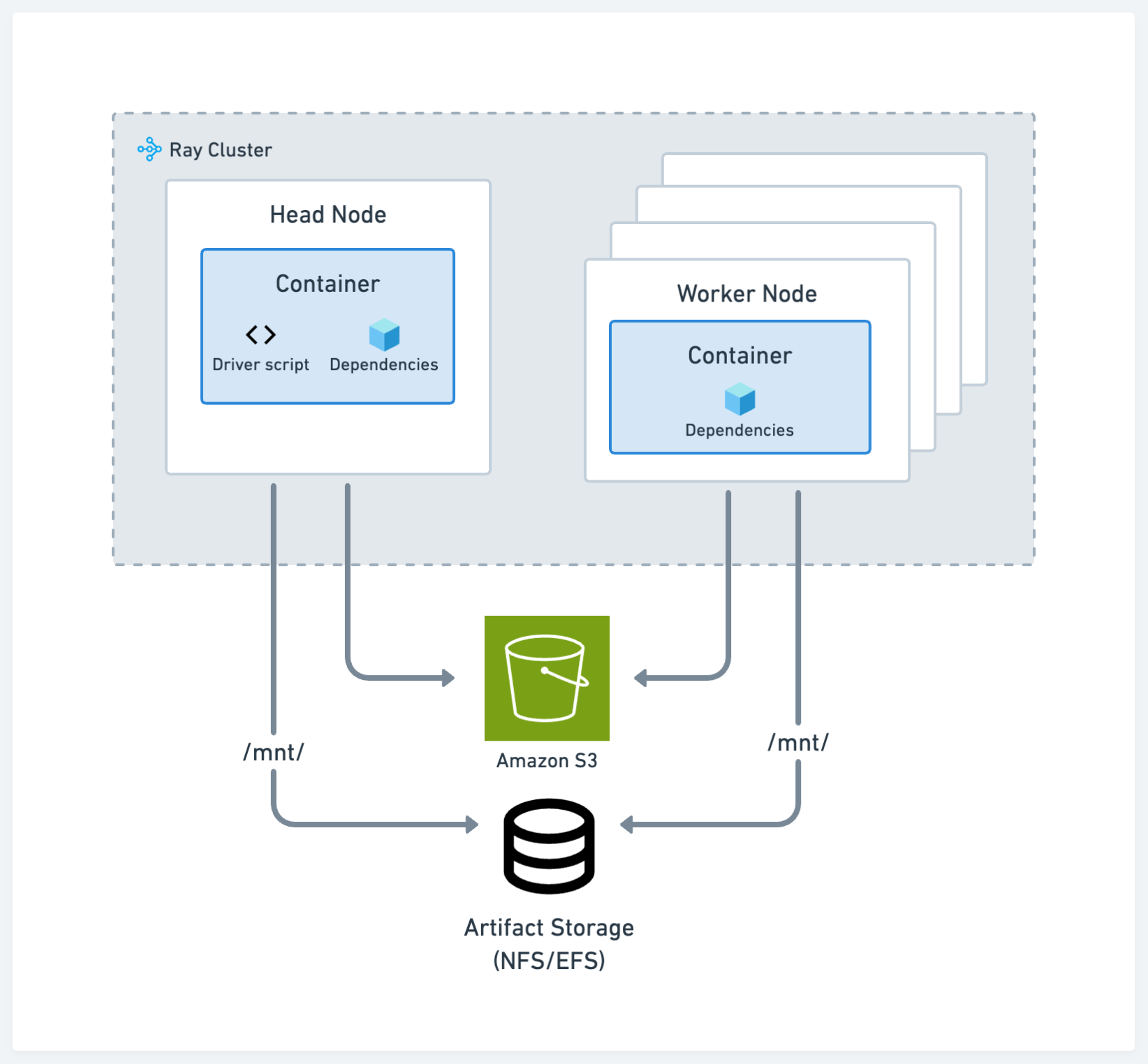
Storage#
The choice of storage system remains the same across development and production.
Code and dependencies#
Bake your code, remote, and local dependencies into a published Docker image for all nodes in the cluster. This approach is the most common way to deploy applications onto Kubernetes. See Custom Docker Images.
Using cloud storage and the runtime env is a less preferred method as it may not be as reproducible as the container path, but it’s still viable. In this case, use the runtime environment option to download zip files containing code and other private modules from cloud storage, in addition to specifying the pip packages needed to run your application.