Configuring Persistent Storage#
A Ray Train run produces checkpoints that can be saved to a persistent storage location.
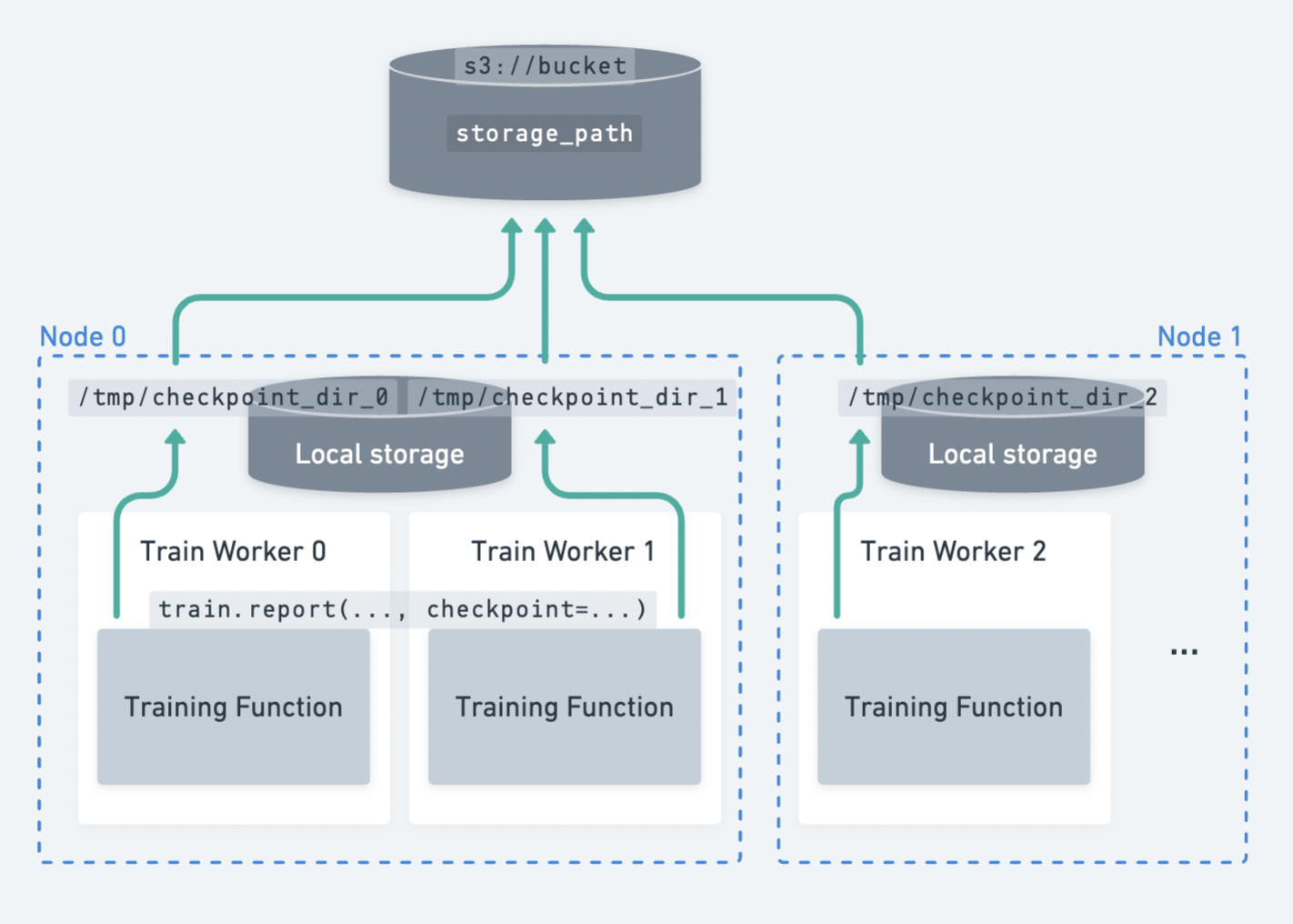
An example of multiple workers spread across multiple nodes uploading checkpoints to persistent storage.#
Ray Train expects all workers to be able to write files to the same persistent storage location. Therefore, Ray Train requires some form of external persistent storage such as cloud object storage (for example, S3, GCS, or Azure Blob Storage) or a shared filesystem (for example, AWS EFS, Google Cloud Filestore, Azure Files, or HDFS) for multi-node training.
Here are some capabilities that persistent storage enables:
Checkpointing and fault tolerance: Saving checkpoints to a persistent storage location allows you to resume training from the last checkpoint in case of a node failure. See Saving and Loading Checkpoints for a detailed guide on how to set up checkpointing.
Post-experiment analysis: A consolidated location storing data such as the best checkpoints and hyperparameter configs after the Ray cluster has already been terminated.
Bridge training/fine-tuning with downstream serving and batch inference tasks: You can easily access the models and artifacts to share them with others or use them in downstream tasks.
Cloud object storage#
The Ray team recommends using cloud object storage such as S3, GCS, or Azure Blob Storage to persist Ray Train checkpoint files.
Use cloud object storage by specifying a storage container URI as the RunConfig(storage_path):
Specify a URI with the s3:// scheme. Ray Train uses pyarrow’s default
S3FileSystem for upload and download.
from ray import train
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_path="s3://bucket-name/sub-path/",
name="experiment_name",
)
)
Specify a URI with the gs:// scheme. Ray Train uses pyarrow’s default
GcsFileSystem for upload and download.
from ray import train
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_path="gs://bucket-name/sub-path/",
name="experiment_name",
)
)
Ray Train uses pyarrow.fs for storage I/O, so wrap
adlfs.AzureBlobFileSystem in a pyarrow.fs.PyFileSystem and pass
it as RunConfig(storage_filesystem).
Use the abfss:// scheme (TLS-enforced) for the URI:
import adlfs
from pyarrow.fs import FSSpecHandler, PyFileSystem
from ray import train
from ray.train.torch import TorchTrainer
azure_fs = PyFileSystem(
FSSpecHandler(adlfs.AzureBlobFileSystem(account_name="account-name"))
)
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_filesystem=azure_fs,
storage_path="abfss://container@account.dfs.core.windows.net/sub-path/",
name="experiment_name",
)
)
See Custom storage for more on storage_filesystem.
Ensure that all nodes in the Ray cluster have access to the storage container, so outputs from workers can be uploaded to a shared location.
In the AWS S3 example above, all files are uploaded to shared storage at s3://bucket-name/sub-path/experiment_name for further processing.
Local storage#
Using local storage for a single-node cluster#
If you’re just running an experiment on a single node (e.g., on a laptop), Ray Train will use the
local filesystem as the storage location for checkpoints and other artifacts.
Results are saved to ~/ray_results in a sub-directory with a unique auto-generated name by default,
unless you customize this with storage_path and name in RunConfig.
from ray import train
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_path="/tmp/custom/storage/path",
name="experiment_name",
)
)
In this example, all experiment results can found locally at /tmp/custom/storage/path/experiment_name for further processing.
Using local storage for a multi-node cluster#
Warning
When running on multiple nodes, using the local filesystem of the head node as the persistent storage location is no longer supported.
If you save checkpoints with ray.train.report(..., checkpoint=...)
and run on a multi-node cluster, Ray Train will raise an error if NFS or cloud storage is not setup.
This is because Ray Train expects all workers to be able to write the checkpoint to
the same persistent storage location.
If your training loop does not save checkpoints, the reported metrics will still be aggregated to the local storage path on the head node.
See this issue for more information.
Custom storage#
If the cases above don’t suit your needs, Ray Train can support custom filesystems and perform custom logic.
Ray Train standardizes on the pyarrow.fs.FileSystem interface to interact with storage
(see the API reference here).
By default, passing storage_path=s3://bucket-name/sub-path/ will use pyarrow’s
default S3 filesystem implementation
to upload files. (See the other default implementations.)
Implement custom storage upload and download logic by providing an implementation of
pyarrow.fs.FileSystem to RunConfig(storage_filesystem).
Warning
When providing a custom filesystem, the associated storage_path is expected
to be a qualified filesystem path without the protocol prefix.
For example, if you provide a custom S3 filesystem for s3://bucket-name/sub-path/,
then the storage_path should be bucket-name/sub-path/ with the s3:// stripped.
See the example below for example usage.
import pyarrow.fs
from ray import train
from ray.train.torch import TorchTrainer
fs = pyarrow.fs.S3FileSystem(
endpoint_override="http://localhost:9000",
access_key=...,
secret_key=...
)
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
storage_filesystem=fs,
storage_path="bucket-name/sub-path",
name="unique-run-id",
)
)
fsspec filesystems#
fsspec offers many filesystem implementations,
such as s3fs, gcsfs, etc.
You can use any of these implementations by wrapping the fsspec filesystem with a pyarrow.fs utility:
# Make sure to install: `pip install -U s3fs`
import s3fs
import pyarrow.fs
s3_fs = s3fs.S3FileSystem(
key='miniokey...',
secret='asecretkey...',
endpoint_url='https://...'
)
custom_fs = pyarrow.fs.PyFileSystem(pyarrow.fs.FSSpecHandler(s3_fs))
run_config = RunConfig(storage_path="minio_bucket", storage_filesystem=custom_fs)
See also
See the API references to the pyarrow.fs wrapper utilities:
S3-compatible storage (Backblaze B2, MinIO, etc.)#
For S3-compatible stores like Backblaze B2
or MinIO, follow the
custom-filesystem examples above, or pass
the endpoint as a query parameter in the storage_path URI:
from ray import train
from ray.train.torch import TorchTrainer
trainer = TorchTrainer(
...,
run_config=train.RunConfig(
# Backblaze B2 (substitute your bucket's region):
storage_path="s3://bucket-name/sub-path?endpoint_override=https://s3.us-west-001.backblazeb2.com",
# MinIO running locally:
# storage_path="s3://bucket-name/sub-path?endpoint_override=http://localhost:9000",
name="unique-run-id",
)
)
Alternatively, configure the endpoint and credentials through the environment
variables Arrow reads (see
Arrow’s S3 environment variables)
and use a plain storage_path="s3://bucket/path". For Backblaze B2, set
AWS_ENDPOINT_URL_S3 to your bucket’s endpoint, and AWS_ACCESS_KEY_ID /
AWS_SECRET_ACCESS_KEY to your B2 application key ID and key.
See this end-to-end notebook for a worked Backblaze B2 example.
Overview of Ray Train outputs#
So far, we covered how to configure the storage location for Ray Train outputs. Let’s walk through a concrete example to see what exactly these outputs are, and how they’re structured in storage.
See also
This example includes checkpointing, which is covered in detail in Saving and Loading Checkpoints.
import os
import tempfile
import ray.train
from ray.train import Checkpoint
from ray.train.torch import TorchTrainer
def train_fn(config):
for i in range(10):
# Training logic here
metrics = {"loss": ...}
with tempfile.TemporaryDirectory() as temp_checkpoint_dir:
torch.save(..., os.path.join(temp_checkpoint_dir, "checkpoint.pt"))
train.report(
metrics,
checkpoint=Checkpoint.from_directory(temp_checkpoint_dir)
)
trainer = TorchTrainer(
train_fn,
scaling_config=ray.train.ScalingConfig(num_workers=2),
run_config=ray.train.RunConfig(
storage_path="s3://bucket-name/sub-path/",
name="unique-run-id",
)
)
result: train.Result = trainer.fit()
last_checkpoint: Checkpoint = result.checkpoint
Here’s a rundown of all files that will be persisted to storage:
{RunConfig.storage_path} (ex: "s3://bucket-name/sub-path/")
└── {RunConfig.name} (ex: "unique-run-id") <- Train run output directory
├── *_snapshot.json <- Train run metadata files (DeveloperAPI)
├── checkpoint_epoch=0/ <- Checkpoints
├── checkpoint_epoch=1/
└── ...
The Result and Checkpoint objects returned by
trainer.fit are the easiest way to access the data in these files:
result.filesystem, result.path
# S3FileSystem, "bucket-name/sub-path/unique-run-id"
result.checkpoint.filesystem, result.checkpoint.path
# S3FileSystem, "bucket-name/sub-path/unique-run-id/checkpoint_epoch=0"
See Inspecting Training Results for a full guide on interacting with training Results.
Advanced configuration#
Keep the original current working directory#
Ray Train changes the current working directory of each worker to the same path.
By default, this path is a sub-directory of the Ray session directory (e.g., /tmp/ray/session_latest),
which is also where other Ray logs and temporary files are dumped.
The location of the Ray session directory can be customized.
To disable the default behavior of Ray Train changing the current working directory,
set the RAY_CHDIR_TO_TRIAL_DIR=0 environment variable.
This is useful if you want your training workers to access relative paths from the directory you launched the training script from.
Tip
When running in a distributed cluster, you will need to make sure that all workers have a mirrored working directory to access the same relative paths.
One way to achieve this is setting the working directory in the Ray runtime environment.
import os
import ray
import ray.train
from ray.train.torch import TorchTrainer
os.environ["RAY_CHDIR_TO_TRIAL_DIR"] = "0"
# Write some file in the current working directory
with open("./data.txt", "w") as f:
f.write("some data")
# Set the working directory in the Ray runtime environment
ray.init(runtime_env={"working_dir": "."})
def train_fn_per_worker(config):
# Check that each worker can access the working directory
# NOTE: The working directory is copied to each worker and is read only.
assert os.path.exists("./data.txt"), os.getcwd()
trainer = TorchTrainer(
train_fn_per_worker,
scaling_config=ray.train.ScalingConfig(num_workers=2),
run_config=ray.train.RunConfig(
# storage_path=...,
),
)
trainer.fit()
Deprecated#
The following sections describe behavior that is deprecated as of Ray 2.43 and will not be supported in Ray Train V2, which is an overhaul of Ray Train’s implementation and select APIs.
See the following resources for more information:
Train V2 REP: Technical details about the API change
Train V2 Migration Guide: Full migration guide for Train V2
(Deprecated) Persisting training artifacts#
Note
This feature of persisting training worker artifacts is deprecated as of Ray 2.43. The feature relied on Ray Tune’s local working directory abstraction, where the local files of each worker would be copied to storage. Ray Train V2 decouples the two libraries, so this API, which already provided limited value, has been deprecated.
In the example above, we saved some artifacts within the training loop to the worker’s current working directory. If you were training a stable diffusion model, you could save some sample generated images every so often as a training artifact.
By default, Ray Train changes the current working directory of each worker to be inside the run’s local staging directory. This way, all distributed training workers share the same absolute path as the working directory. See below for how to disable this default behavior, which is useful if you want your training workers to keep their original working directories.
If RunConfig(SyncConfig(sync_artifacts=True)), then
all artifacts saved in this directory will be persisted to storage.
The frequency of artifact syncing can be configured via SyncConfig.
Note that this behavior is off by default.
Here’s an example of what the Train run output directory looks like, with the worker artifacts:
s3://bucket-name/sub-path (RunConfig.storage_path)
└── experiment_name (RunConfig.name) <- The "experiment directory"
├── experiment_state-*.json
├── basic-variant-state-*.json
├── trainer.pkl
├── tuner.pkl
└── TorchTrainer_46367_00000_0_... <- The "trial directory"
├── events.out.tfevents... <- Tensorboard logs of reported metrics
├── result.json <- JSON log file of reported metrics
├── checkpoint_000000/ <- Checkpoints
├── checkpoint_000001/
├── ...
├── artifact-rank=0-iter=0.txt <- Worker artifacts
├── artifact-rank=1-iter=0.txt
└── ...
Warning
Artifacts saved by every worker will be synced to storage. If you have multiple workers co-located on the same node, make sure that workers don’t delete files within their shared working directory.
A best practice is to only write artifacts from a single worker unless you really need artifacts from multiple.
from ray import train
if train.get_context().get_world_rank() == 0:
# Only the global rank 0 worker saves artifacts.
...
if train.get_context().get_local_rank() == 0:
# Every local rank 0 worker saves artifacts.
...
(Deprecated) Setting the local staging directory#
Note
This section describes behavior depending on Ray Tune implementation details that no longer applies to Ray Train V2.
Warning
Prior to 2.10, the RAY_AIR_LOCAL_CACHE_DIR environment variable and RunConfig(local_dir)
were ways to configure the local staging directory to be outside of the home directory (~/ray_results).
These configurations are no longer used to configure the local staging directory.
Please instead use RunConfig(storage_path) to configure where your
run’s outputs go.
Apart from files such as checkpoints written directly to the storage_path,
Ray Train also writes some logfiles and metadata files to an intermediate
local staging directory before they get persisted (copied/uploaded) to the storage_path.
The current working directory of each worker is set within this local staging directory.
By default, the local staging directory is a sub-directory of the Ray session
directory (e.g., /tmp/ray/session_latest), which is also where other temporary Ray files are dumped.
Customize the location of the staging directory by setting the location of the temporary Ray session directory.
Here’s an example of what the local staging directory looks like:
/tmp/ray/session_latest/artifacts/<ray-train-job-timestamp>/
└── experiment_name
├── driver_artifacts <- These are all uploaded to storage periodically
│ ├── Experiment state snapshot files needed for resuming training
│ └── Metrics logfiles
└── working_dirs <- These are uploaded to storage if `SyncConfig(sync_artifacts=True)`
└── Current working directory of training workers, which contains worker artifacts
Warning
You should not need to look into the local staging directory.
The storage_path should be the only path that you need to interact with.
The structure of the local staging directory is subject to change in future versions of Ray Train – do not rely on these local staging files in your application.