Parameter Server#

Tip
For a production-grade implementation of distributed training, use Ray Train.
The parameter server is a framework for distributed machine learning training.
In the parameter server framework, a centralized server (or group of server nodes) maintains global shared parameters of a machine-learning model (e.g., a neural network) while the data and computation of calculating updates (i.e., gradient descent updates) are distributed over worker nodes.
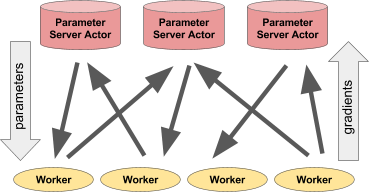
Parameter servers are a core part of many machine learning applications. This document walks through how to implement simple synchronous and asynchronous parameter servers using Ray actors.
To run the application, first install some dependencies.
pip install torch torchvision filelock
Let’s first define some helper functions and import some dependencies.
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import datasets, transforms
from filelock import FileLock
import numpy as np
import ray
def get_data_loader():
"""Safely downloads data. Returns training/validation set dataloader."""
mnist_transforms = transforms.Compose(
[transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]
)
# We add FileLock here because multiple workers will want to
# download data, and this may cause overwrites since
# DataLoader is not threadsafe.
with FileLock(os.path.expanduser("~/data.lock")):
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(
"~/data", train=True, download=True, transform=mnist_transforms
),
batch_size=128,
shuffle=True,
)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST("~/data", train=False, transform=mnist_transforms),
batch_size=128,
shuffle=True,
)
return train_loader, test_loader
def evaluate(model, test_loader):
"""Evaluates the accuracy of the model on a validation dataset."""
model.eval()
correct = 0
total = 0
with torch.no_grad():
for batch_idx, (data, target) in enumerate(test_loader):
# This is only set to finish evaluation faster.
if batch_idx * len(data) > 1024:
break
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
return 100.0 * correct / total
Setup: Defining the Neural Network#
We define a small neural network to use in training. We provide some helper functions for obtaining data, including getter/setter methods for gradients and weights.
class ConvNet(nn.Module):
"""Small ConvNet for MNIST."""
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 3, kernel_size=3)
self.fc = nn.Linear(192, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 3))
x = x.view(-1, 192)
x = self.fc(x)
return F.log_softmax(x, dim=1)
def get_weights(self):
return {k: v.cpu() for k, v in self.state_dict().items()}
def set_weights(self, weights):
self.load_state_dict(weights)
def get_gradients(self):
grads = []
for p in self.parameters():
grad = None if p.grad is None else p.grad.data.cpu().numpy()
grads.append(grad)
return grads
def set_gradients(self, gradients):
for g, p in zip(gradients, self.parameters()):
if g is not None:
p.grad = torch.from_numpy(g)
Defining the Parameter Server#
The parameter server will hold a copy of the model. During training, it will:
Receive gradients and apply them to its model.
Send the updated model back to the workers.
The @ray.remote decorator defines a remote process. It wraps the
ParameterServer class and allows users to instantiate it as a
remote actor.
@ray.remote
class ParameterServer(object):
def __init__(self, lr):
self.model = ConvNet()
self.optimizer = torch.optim.SGD(self.model.parameters(), lr=lr)
def apply_gradients(self, *gradients):
summed_gradients = [
np.stack(gradient_zip).sum(axis=0) for gradient_zip in zip(*gradients)
]
self.optimizer.zero_grad()
self.model.set_gradients(summed_gradients)
self.optimizer.step()
return self.model.get_weights()
def get_weights(self):
return self.model.get_weights()
Defining the Worker#
The worker will also hold a copy of the model. During training. it will continuously evaluate data and send gradients to the parameter server. The worker will synchronize its model with the Parameter Server model weights.
@ray.remote
class DataWorker(object):
def __init__(self):
self.model = ConvNet()
self.data_iterator = iter(get_data_loader()[0])
def compute_gradients(self, weights):
self.model.set_weights(weights)
try:
data, target = next(self.data_iterator)
except StopIteration: # When the epoch ends, start a new epoch.
self.data_iterator = iter(get_data_loader()[0])
data, target = next(self.data_iterator)
self.model.zero_grad()
output = self.model(data)
loss = F.nll_loss(output, target)
loss.backward()
return self.model.get_gradients()
Synchronous Parameter Server Training#
We’ll now create a synchronous parameter server training scheme. We’ll first instantiate a process for the parameter server, along with multiple workers.
iterations = 200
num_workers = 2
ray.init(ignore_reinit_error=True)
ps = ParameterServer.remote(1e-2)
workers = [DataWorker.remote() for i in range(num_workers)]
We’ll also instantiate a model on the driver process to evaluate the test accuracy during training.
model = ConvNet()
test_loader = get_data_loader()[1]
Training alternates between:
Computing the gradients given the current weights from the server
Updating the parameter server’s weights with the gradients.
print("Running synchronous parameter server training.")
current_weights = ps.get_weights.remote()
for i in range(iterations):
gradients = [worker.compute_gradients.remote(current_weights) for worker in workers]
# Calculate update after all gradients are available.
current_weights = ps.apply_gradients.remote(*gradients)
if i % 10 == 0:
# Evaluate the current model.
model.set_weights(ray.get(current_weights))
accuracy = evaluate(model, test_loader)
print("Iter {}: \taccuracy is {:.1f}".format(i, accuracy))
print("Final accuracy is {:.1f}.".format(accuracy))
# Clean up Ray resources and processes before the next example.
ray.shutdown()
Asynchronous Parameter Server Training#
We’ll now create an asynchronous parameter server training scheme. We’ll first instantiate a process for the parameter server, along with multiple workers.
print("Running Asynchronous Parameter Server Training.")
ray.init(ignore_reinit_error=True)
ps = ParameterServer.remote(1e-2)
workers = [DataWorker.remote() for i in range(num_workers)]
Here, workers will asynchronously compute the gradients given its current weights and send these gradients to the parameter server as soon as they are ready. When the Parameter server finishes applying the new gradient, the server will send back a copy of the current weights to the worker. The worker will then update the weights and repeat.
current_weights = ps.get_weights.remote()
gradients = {}
for worker in workers:
gradients[worker.compute_gradients.remote(current_weights)] = worker
for i in range(iterations * num_workers):
ready_gradient_list, _ = ray.wait(list(gradients))
ready_gradient_id = ready_gradient_list[0]
worker = gradients.pop(ready_gradient_id)
# Compute and apply gradients.
current_weights = ps.apply_gradients.remote(*[ready_gradient_id])
gradients[worker.compute_gradients.remote(current_weights)] = worker
if i % 10 == 0:
# Evaluate the current model after every 10 updates.
model.set_weights(ray.get(current_weights))
accuracy = evaluate(model, test_loader)
print("Iter {}: \taccuracy is {:.1f}".format(i, accuracy))
print("Final accuracy is {:.1f}.".format(accuracy))
Final Thoughts#
This approach is powerful because it enables you to implement a parameter server with a few lines of code as part of a Python application. As a result, this simplifies the deployment of applications that use parameter servers and to modify the behavior of the parameter server.
For example, sharding the parameter server, changing the update rule, switching between asynchronous and synchronous updates, ignoring straggler workers, or any number of other customizations, will only require a few extra lines of code.