Scale a Gradio App with Ray Serve#
This guide shows how to scale up your Gradio application using Ray Serve. Keep the internal architecture of your Gradio app intact, with no code changes. Simply wrap the app within Ray Serve as a deployment and scale it to access more resources.
This tutorial uses Gradio apps that run text summarization and generation models and use Hugging Face’s Pipelines to access these models.
Note
Remember you can substitute this app with your own Gradio app if you want to try scaling up your own Gradio app.
Dependencies#
To follow this tutorial, you need Ray Serve, Gradio, and transformers. If you haven’t already, install them by running:
$ pip install "ray[serve]" gradio==3.50.2 torch transformers
Example 1: Scaling up your Gradio app with GradioServer#
The first example summarizes text using the T5 Small model and uses Hugging Face’s Pipelines to access that model. It demonstrates one easy way to deploy Gradio apps onto Ray Serve: using the simple GradioServer wrapper. Example 2 shows how to use GradioIngress for more customized use-cases.
First, create a new Python file named demo.py. Second, import GradioServer from Ray Serve to deploy your Gradio app later, gradio, and transformers.pipeline to load text summarization models.
from ray.serve.gradio_integrations import GradioServer
import gradio as gr
from transformers import pipeline
Then, write a builder function that constructs the Gradio app io.
example_input = (
"HOUSTON -- Men have landed and walked on the moon. "
"Two Americans, astronauts of Apollo 11, steered their fragile "
"four-legged lunar module safely and smoothly to the historic landing "
"yesterday at 4:17:40 P.M., Eastern daylight time. Neil A. Armstrong, the "
"38-year-old commander, radioed to earth and the mission control room "
'here: "Houston, Tranquility Base here. The Eagle has landed." The '
"first men to reach the moon -- Armstrong and his co-pilot, Col. Edwin E. "
"Aldrin Jr. of the Air Force -- brought their ship to rest on a level, "
"rock-strewn plain near the southwestern shore of the arid Sea of "
"Tranquility. About six and a half hours later, Armstrong opened the "
"landing craft's hatch, stepped slowly down the ladder and declared as "
"he planted the first human footprint on the lunar crust: \"That's one "
'small step for man, one giant leap for mankind." His first step on the '
"moon came at 10:56:20 P.M., as a television camera outside the craft "
"transmitted his every move to an awed and excited audience of hundreds "
"of millions of people on earth."
)
def gradio_summarizer_builder():
summarizer = pipeline("summarization", model="t5-small")
def model(text):
summary_list = summarizer(text)
summary = summary_list[0]["summary_text"]
return summary
return gr.Interface(
fn=model,
inputs=[gr.Textbox(value=example_input, label="Input prompt")],
outputs=[gr.Textbox(label="Model output")],
api_name="predict",
)
Deploying Gradio Server#
To deploy your Gradio app onto Ray Serve, you need to wrap the Gradio app in a Serve deployment. GradioServer acts as that wrapper. It serves your Gradio app remotely on Ray Serve so that it can process and respond to HTTP requests.
By wrapping your application in GradioServer, you can increase the number of CPUs and/or GPUs available to the application.
Note
Ray Serve doesn’t support routing requests to multiple replicas of GradioServer, so you should only have a single replica.
Note
GradioServer is simply GradioIngress but wrapped in a Serve deployment. You can use GradioServer for the simple wrap-and-deploy use case, but in the next section, you can use GradioIngress to define your own Gradio Server for more customized use cases.
Note
Ray can’t pickle Gradio. Instead, pass a builder function that constructs the Gradio interface.
Using either the Gradio app io, which the builder function constructed, or your own Gradio app of type Interface, Block, Parallel, etc., wrap the app in your Gradio Server. Pass the builder function as input to your Gradio Server. Ray Serves uses the builder function to construct your Gradio app on the Ray cluster.
app = GradioServer.options(ray_actor_options={"num_cpus": 4}).bind(
gradio_summarizer_builder
)
Finally, deploy your Gradio Server. Run the following in your terminal, assuming that you saved the file as demo.py:
$ serve run demo:app
Access your Gradio app at http://localhost:8000 The output should look like the following image:
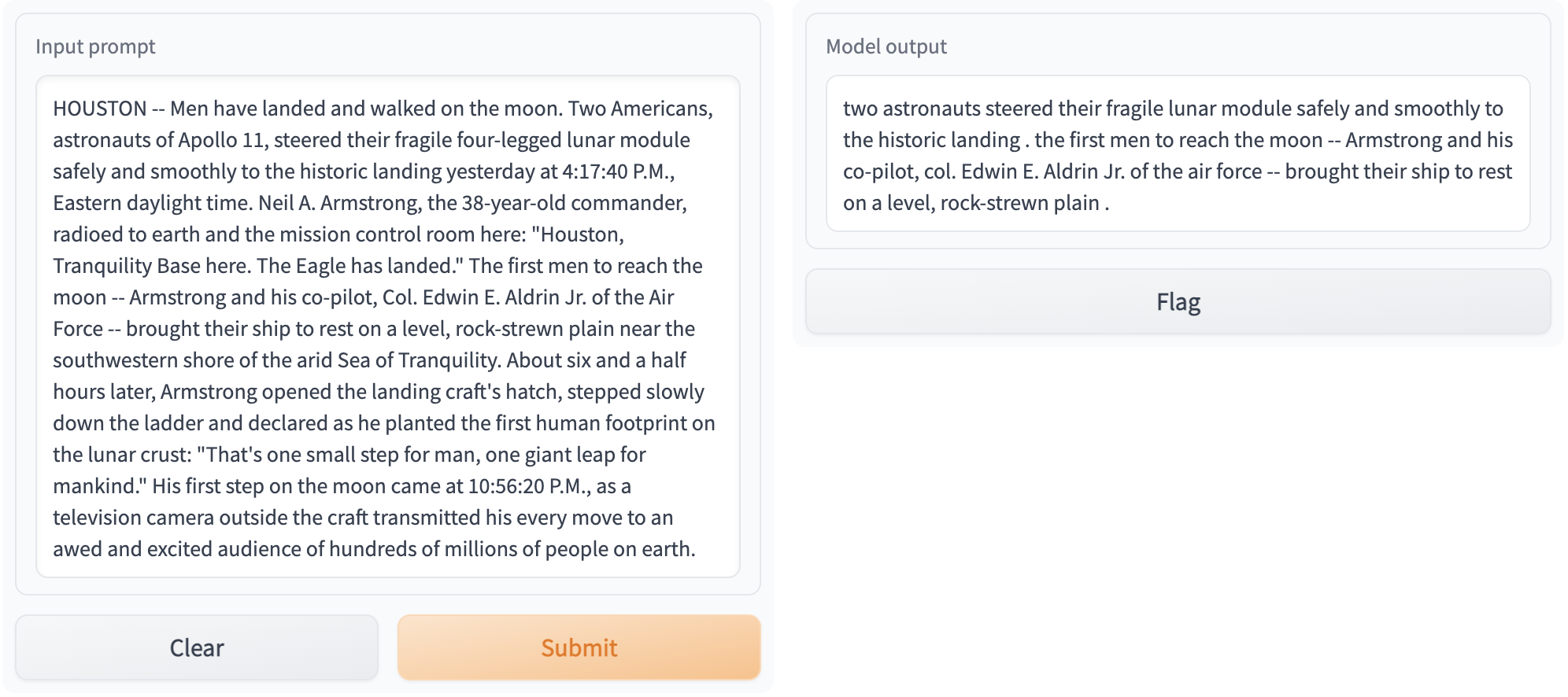
See the Production Guide for more information on how to deploy your app in production.
Example 2: Parallelizing models with Ray Serve#
You can run multiple models in parallel with Ray Serve by using model composition in Ray Serve.
Suppose you want to run the following program.
Take two text generation models,
gpt2anddistilgpt2.Run the two models on the same input text, so that the generated text has a minimum length of 20 and maximum length of 100.
Display the outputs of both models using Gradio.
The following is a comparison of an unparallelized approach using vanilla Gradio to a parallelized approach using Ray Serve.
Vanilla Gradio#
This code is a typical implementation:
generator1 = pipeline("text-generation", model="gpt2")
generator2 = pipeline("text-generation", model="distilgpt2")
def model1(text):
generated_list = generator1(text, do_sample=True, min_length=20, max_length=100)
generated = generated_list[0]["generated_text"]
return generated
def model2(text):
generated_list = generator2(text, do_sample=True, min_length=20, max_length=100)
generated = generated_list[0]["generated_text"]
return generated
demo = gr.Interface(
lambda text: f"{model1(text)}\n------------\n{model2(text)}",
"textbox",
"textbox",
api_name="predict",
)
Launch the Gradio app with this command:
demo.launch()
Parallelize using Ray Serve#
With Ray Serve, you can parallelize the two text generation models by wrapping each model in a separate Ray Serve deployment. You can define deployments by decorating a Python class or function with @serve.deployment. The deployments usually wrap the models that you want to deploy on Ray Serve to handle incoming requests.
Follow these steps to achieve parallelism. First, import the dependencies. Note that you need to import GradioIngress instead of GradioServer like before because in this case, you’re building a customized MyGradioServer that can run models in parallel.
from ray import serve
from ray.serve.handle import DeploymentHandle
from ray.serve.gradio_integrations import GradioIngress
import gradio as gr
import asyncio
from transformers import pipeline
Then, wrap the gpt2 and distilgpt2 models in Serve deployments, named TextGenerationModel.
@serve.deployment
class TextGenerationModel:
def __init__(self, model_name):
self.generator = pipeline("text-generation", model=model_name)
def __call__(self, text):
generated_list = self.generator(
text, do_sample=True, min_length=20, max_length=100
)
generated = generated_list[0]["generated_text"]
return generated
app1 = TextGenerationModel.bind("gpt2")
app2 = TextGenerationModel.bind("distilgpt2")
Next, instead of simply wrapping the Gradio app in a GradioServer deployment, build your own MyGradioServer that reroutes the Gradio app so that it runs the TextGenerationModel deployments.
@serve.deployment
class MyGradioServer(GradioIngress):
def __init__(
self, downstream_model_1: DeploymentHandle, downstream_model_2: DeploymentHandle
):
self._d1 = downstream_model_1
self._d2 = downstream_model_2
super().__init__(
lambda: gr.Interface(
self.fanout, "textbox", "textbox", api_name="predict"
)
)
async def fanout(self, text):
[result1, result2] = await asyncio.gather(
self._d1.remote(text), self._d2.remote(text)
)
return (
f"[Generated text version 1]\n{result1}\n\n"
f"[Generated text version 2]\n{result2}"
)
Lastly, link everything together:
app = MyGradioServer.bind(app1, app2)
Note
This step binds the two text generation models, which you wrapped in Serve deployments, to MyGradioServer._d1 and MyGradioServer._d2, forming a model composition. In the example, the Gradio Interface io calls MyGradioServer.fanout(), which sends requests to the two text generation models that you deployed on Ray Serve.
Now, you can run your scalable app, to serve the two text generation models in parallel on Ray Serve. Run your Gradio app with the following command:
$ serve run demo:app
Access your Gradio app at http://localhost:8000, and you should see the following interactive interface:
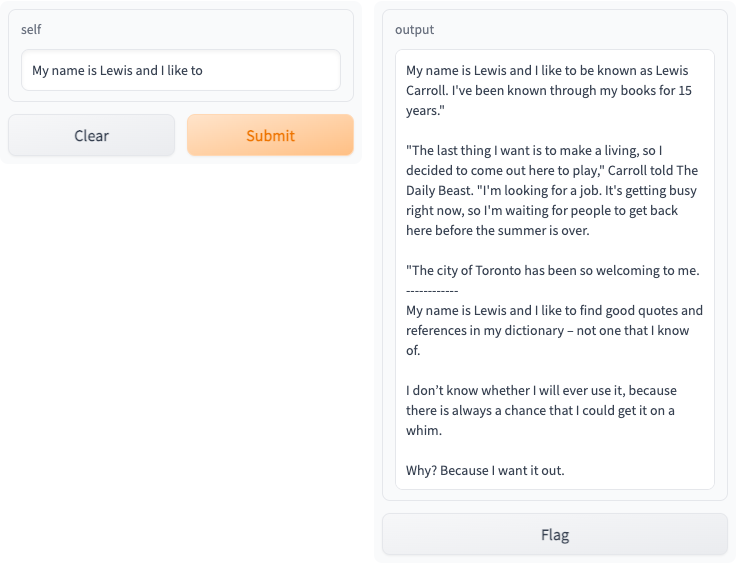
See the Production Guide for more information on how to deploy your app in production.