Deploying on YARN#
Warning
Running Ray on YARN is still a work in progress. If you have a suggestion for how to improve this documentation or want to request a missing feature, please feel free to create a pull request or get in touch using one of the channels in the Questions or Issues? section below.
This document assumes that you have access to a YARN cluster and will walk you through using Skein to deploy a YARN job that starts a Ray cluster and runs an example script on it.
Skein uses a declarative specification (either written as a yaml file or using the Python API) and allows users to launch jobs and scale applications without the need to write Java code.
You will first need to install Skein: pip install skein.
The Skein yaml file and example Ray program used here are provided in the
Ray repository to get you started. Refer to the provided yaml
files to be sure that you maintain important configuration options for Ray to
function properly.
Skein Configuration#
A Ray job is configured to run as two Skein services:
The
ray-headservice that starts the Ray head node and then runs the application.The
ray-workerservice that starts worker nodes that join the Ray cluster. You can change the number of instances in this configuration or at runtime usingskein container scaleto scale the cluster up/down.
The specification for each service consists of necessary files and commands that will be run to start the service.
services:
ray-head:
# There should only be one instance of the head node per cluster.
instances: 1
resources:
# The resources for the worker node.
vcores: 1
memory: 2048
files:
...
script:
...
ray-worker:
# Number of ray worker nodes to start initially.
# This can be scaled using 'skein container scale'.
instances: 3
resources:
# The resources for the worker node.
vcores: 1
memory: 2048
files:
...
script:
...
Packaging Dependencies#
Use the files option to specify files that will be copied into the YARN container for the application to use. See the Skein file distribution page for more information.
services:
ray-head:
# There should only be one instance of the head node per cluster.
instances: 1
resources:
# The resources for the head node.
vcores: 1
memory: 2048
files:
# ray/doc/yarn/example.py
example.py: example.py
# ray/doc/yarn/dashboard.py
dashboard.py: dashboard.py
# # A packaged python environment using `conda-pack`. Note that Skein
# # doesn't require any specific way of distributing files, but this
# # is a good one for python projects. This is optional.
# # See https://jcrist.github.io/skein/distributing-files.html
# environment: environment.tar.gz
Ray Setup in YARN#
Below is a walkthrough of the bash commands used to start the ray-head and ray-worker services. Note that this configuration will launch a new Ray cluster for each application, not reuse the same cluster.
Head node commands#
Start by activating a pre-existing environment for dependency management.
source environment/bin/activate
Register the Ray head address needed by the workers in the Skein key-value store.
skein kv put --key=RAY_HEAD_ADDRESS --value=$(hostname -i) current
Start all the processes needed on the ray head node. By default, we set object store memory and heap memory to roughly 200 MB. This is conservative and should be set according to application needs.
ray start --head --port=6379 --object-store-memory=200000000 --memory 200000000 --num-cpus=1
Register the ray dashboard to Skein. This exposes the dashboard link on the Skein application page.
python dashboard.py "http://$(hostname -i):8265"
Execute the user script containing the Ray program.
python example.py
Clean up all started processes even if the application fails or is killed.
ray stop
skein application shutdown current
Putting things together, we have:
ray-head:
# There should only be one instance of the head node per cluster.
instances: 1
resources:
# The resources for the head node.
vcores: 1
memory: 2048
files:
# ray/doc/source/cluster/doc_code/yarn/example.py
example.py: example.py
# ray/doc/source/cluster/doc_code/yarn/dashboard.py
dashboard.py: dashboard.py
# # A packaged python environment using `conda-pack`. Note that Skein
# # doesn't require any specific way of distributing files, but this
# # is a good one for python projects. This is optional.
# # See https://jcrist.github.io/skein/distributing-files.html
# environment: environment.tar.gz
script: |
# Activate the packaged conda environment
# - source environment/bin/activate
# This gets the IP address of the head node.
RAY_HEAD_ADDRESS=$(hostname -i)
# This stores the Ray head address in the Skein key-value store so that the workers can retrieve it later.
skein kv put current --key=RAY_HEAD_ADDRESS --value=$RAY_HEAD_ADDRESS
# This command starts all the processes needed on the ray head node.
# By default, we set object store memory and heap memory to roughly 200 MB. This is conservative
# and should be set according to application needs.
#
ray start --head --port=6379 --object-store-memory=200000000 --memory 200000000 --num-cpus=1 --dashboard-host=$RAY_HEAD_ADDRESS
# This registers the Ray dashboard on Skein, which can be accessed on Skein's web UI.
python dashboard.py "http://$RAY_HEAD_ADDRESS:8265"
# This executes the user script.
python example.py
# After the user script has executed, all started processes should also die.
ray stop
skein application shutdown current
Worker node commands#
Fetch the address of the head node from the Skein key-value store.
RAY_HEAD_ADDRESS=$(skein kv get current --key=RAY_HEAD_ADDRESS)
Start all of the processes needed on a ray worker node, blocking until killed by Skein/YARN via SIGTERM. After receiving SIGTERM, all started processes should also die (ray stop).
ray start --object-store-memory=200000000 --memory 200000000 --num-cpus=1 --address=$RAY_HEAD_ADDRESS:6379 --block; ray stop
Putting things together, we have:
ray-worker:
# The number of instances to start initially. This can be scaled
# dynamically later.
instances: 4
resources:
# The resources for the worker node
vcores: 1
memory: 2048
# files:
# environment: environment.tar.gz
depends:
# Don't start any worker nodes until the head node is started
- ray-head
script: |
# Activate the packaged conda environment
# - source environment/bin/activate
# This command gets any addresses it needs (e.g. the head node) from
# the skein key-value store.
RAY_HEAD_ADDRESS=$(skein kv get --key=RAY_HEAD_ADDRESS current)
# The below command starts all the processes needed on a ray worker node, blocking until killed with sigterm.
# After sigterm, all started processes should also die (ray stop).
ray start --object-store-memory=200000000 --memory 200000000 --num-cpus=1 --address=$RAY_HEAD_ADDRESS:6379 --block; ray stop
Running a Job#
Within your Ray script, use the following to connect to the started Ray cluster:
ray.init(address="localhost:6379")
main()
You can use the following command to launch the application as specified by the Skein YAML file.
skein application submit [TEST.YAML]
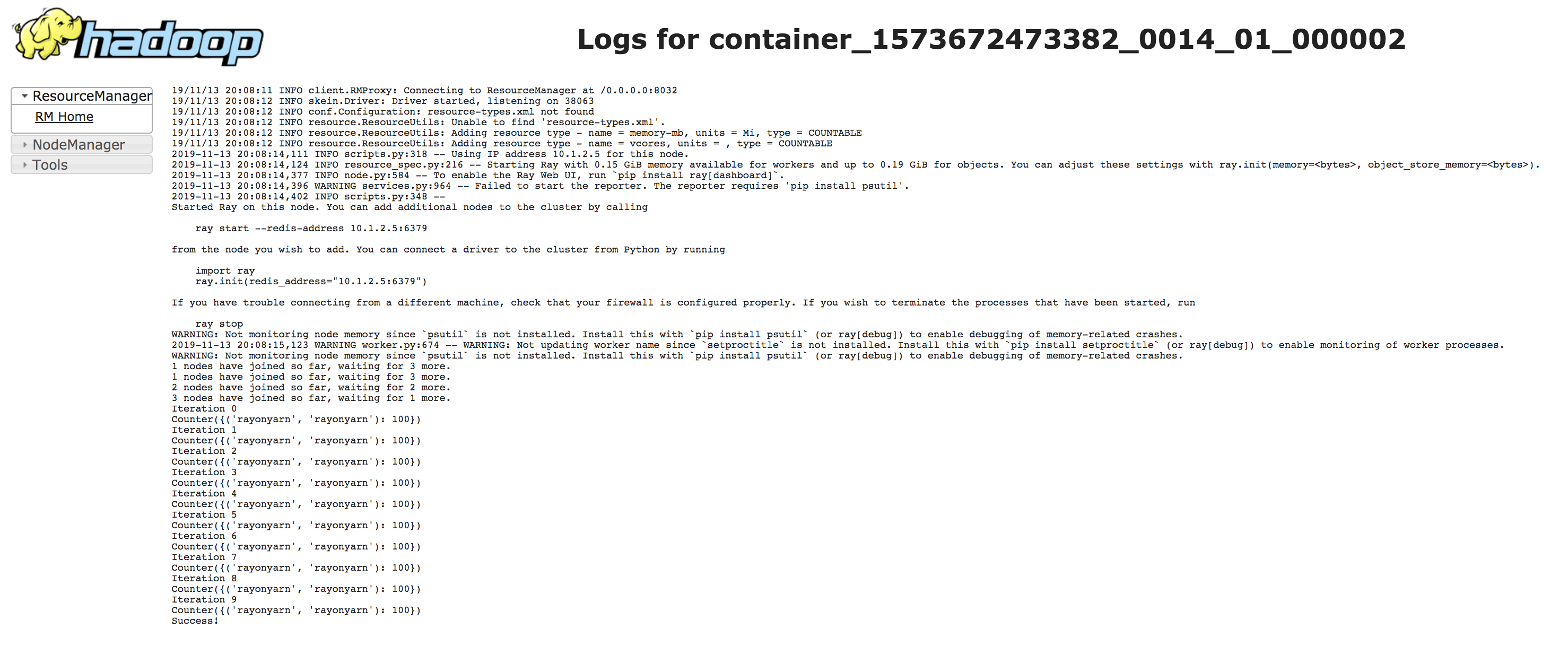
Once it has been submitted, you can see the job running on the YARN dashboard.
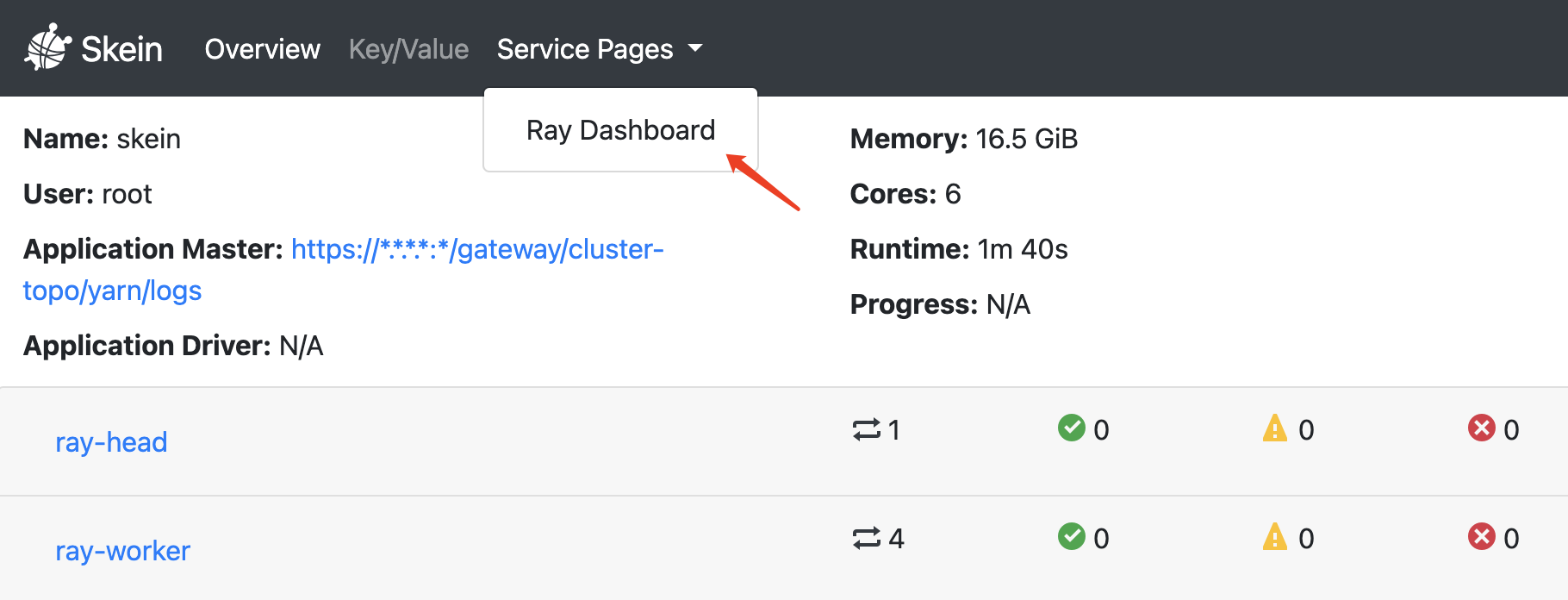
If you have registered the Ray dashboard address in the Skein as shown above, you can retrieve it on Skein’s application page:
Cleaning Up#
To clean up a running job, use the following (using the application ID):
skein application shutdown $appid
Questions or Issues?#
You can post questions or issues or feedback through the following channels:
Discussion Board: For questions about Ray usage or feature requests.
GitHub Issues: For bug reports.
Ray Slack: For getting in touch with Ray maintainers.
StackOverflow: Use the [ray] tag for questions about Ray.