{
"cells": [
{
"cell_type": "markdown",
"metadata": {},
"source": [
"# Fine-tune `dolly-v2-7b` with Ray Train, PyTorch Lightning and FSDP\n",
"\n",
"\n",
"  \n",
"\n",
"
\n",
"\n",
"
"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this example, we demonstrate how to use Ray Train to fine-tune a [`dolly-v2-7b`](https://huggingface.co/databricks/dolly-v2-7b) model. `dolly-v2-7b` is a 7 billion parameter causal language model created by Databricks, derived from EleutherAI’s [Pythia-6.9b](https://huggingface.co/EleutherAI/pythia-6.9b), and fine-tuned on a [~15K record instruction corpus](https://github.com/databrickslabs/dolly/tree/master/data).\n",
"\n",
"We load the pre-trained model from the HuggingFace model hub into a LightningModule and launch an FSDP fine-tuning job across 16 T4 GPUs with the help of {class}`Ray TorchTrainer `. It is also straightforward to fine-tune other similar large language models in a similar manner as shown in this example.\n",
"\n",
"Before starting this example, we highly recommend reading [Ray Train Key Concepts](train-key-concepts) and [Ray Data Quickstart](data_quickstart)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"In this , we demonstrate how to use Ray Train to fine-tune a [`dolly-v2-7b`](https://huggingface.co/databricks/dolly-v2-7b) model. `dolly-v2-7b` is a 7 billion parameter causal language model created by Databricks, derived from EleutherAI’s [Pythia-6.9b](https://huggingface.co/EleutherAI/pythia-6.9b), and fine-tuned on a [~15K record instruction corpus](https://github.com/databrickslabs/dolly/tree/master/data).\n",
"\n",
"We load the pre-trained model from the HuggingFace model hub into a LightningModule and launch an FSDP fine-tuning job across 16 T4 GPUs with the help of {class}`Ray TorchTrainer `. It is also straightforward to fine-tune other similar large language models in a similar manner as shown in this example.\n",
"\n",
"Before starting this example, we highly recommend reading [Ray Train Key Concepts](train-key-concepts) and [Ray Data Quickstart](data_quickstart)."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Set up ray cluster \n",
"In this example, we are using a Ray cluster with a `m5.2xlarge` head node and 4 `g4dn.12xlarge` worker nodes. Each `g4dn.12xlarge has four Tesla T4 GPUs. "
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import ray\n",
"ray.init()"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We then install the necessary dependencies on each node:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {},
"outputs": [],
"source": [
"%%bash\n",
"pip install datasets\n",
"pip install evaluate\n",
"pip install \"transformers>=4.26.0\"\n",
"pip install \"torch>=1.12.0\"\n",
"pip install \"lightning>=2.0\"\n",
"pip install \"pydantic>=2,<3\""
]
},
{
"cell_type": "code",
"execution_count": 4,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"MODEL_NAME = \"databricks/dolly-v2-7b\""
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Prepare your data \n",
"We are using tiny_shakespeare for fine-tuning, which contains 40,000 lines of Shakespeare from a variety of Shakespeare's plays. Featured in Andrej Karpathy's blog post ['The Unreasonable Effectiveness of Recurrent Neural Networks'](http://karpathy.github.io/2015/05/21/rnn-effectiveness/). \n",
"\n",
"Dataset samples:\n",
"```\n",
"BAPTISTA:\n",
"I know him well: you are welcome for his sake.\n",
"\n",
"GREMIO:\n",
"Saving your tale, Petruchio, I pray,\n",
"Let us, that are poor petitioners, speak too:\n",
"Baccare! you are marvellous forward.\n",
"\n",
"PETRUCHIO:\n",
"O, pardon me, Signior Gremio; I would fain be doing.\n",
"```\n",
"\n",
"Here, we have adopted similar pre-processing logic from another demo: {doc}`GPT-J-6B Fine-Tuning with Ray Train and DeepSpeed <../deepspeed/gptj_deepspeed_fine_tuning>`."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import ray\n",
"import pandas as pd\n",
"from datasets import load_dataset\n",
"from transformers import AutoTokenizer, AutoModelForCausalLM\n",
"\n",
"def split_text(batch: pd.DataFrame) -> pd.DataFrame:\n",
" text = list(batch[\"text\"])\n",
" flat_text = \"\".join(text)\n",
" split_text = [\n",
" x.strip()\n",
" for x in flat_text.split(\"\\n\")\n",
" if x.strip() and not x.strip()[-1] == \":\"\n",
" ]\n",
" return pd.DataFrame(split_text, columns=[\"text\"])\n",
"\n",
"\n",
"def tokenize(batch: pd.DataFrame) -> dict:\n",
" tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, padding_side=\"left\")\n",
" tokenizer.pad_token = tokenizer.eos_token\n",
" ret = tokenizer(\n",
" list(batch[\"text\"]),\n",
" truncation=True,\n",
" max_length=256,\n",
" padding=\"max_length\",\n",
" return_tensors=\"np\",\n",
" )\n",
" ret[\"labels\"] = ret[\"input_ids\"].copy()\n",
" return dict(ret)\n",
"\n",
"hf_dataset = load_dataset(\"tiny_shakespeare\", trust_remote_code=True)\n",
"train_ds = ray.data.from_huggingface(hf_dataset[\"train\"])"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We first split the original paragraphs into multiple sentences, then tokenize them. Here are some samples:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"# First split the dataset into multiple sentences.\n",
"train_ds = train_ds.map_batches(split_text, batch_format=\"pandas\")\n",
"train_ds.take(10)"
]
},
{
"cell_type": "code",
"execution_count": 7,
"metadata": {},
"outputs": [],
"source": [
"# Then tokenize the dataset.\n",
"train_ds = train_ds.map_batches(tokenize, batch_format=\"pandas\")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Define your lightning model\n",
"\n",
"In this example, we use the [dolly-v2-7b](https://huggingface.co/databricks/dolly-v2-7b) model for finetuning. It is an instruction-following large language model trained on the Databricks machine learning platform that is licensed for commercial use. We load the model weights from Huggingface Model Hub and encapsulate it into a `pl.LightningModule`.\n",
"\n",
":::{note}\n",
"Make sure you pass the FSDP wrapped model parameters `self.trainer.model.parameters()` into the optimizer, instead of `self.model.parameters()`. \n",
":::\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import torch\n",
"import lightning.pytorch as pl\n",
"\n",
"class DollyV2Model(pl.LightningModule):\n",
" def __init__(self, lr=2e-5, eps=1e-8):\n",
" super().__init__()\n",
" self.save_hyperparameters()\n",
" self.lr = lr\n",
" self.eps = eps\n",
" self.model = AutoModelForCausalLM.from_pretrained(MODEL_NAME)\n",
"\n",
" def forward(self, batch):\n",
" outputs = self.model(\n",
" batch[\"input_ids\"], \n",
" attention_mask=batch[\"attention_mask\"], \n",
" labels=batch[\"labels\"]\n",
" )\n",
" return outputs.loss\n",
"\n",
" def training_step(self, batch, batch_idx):\n",
" loss = self.forward(batch)\n",
" self.log(\"train_loss\", loss, prog_bar=True, on_step=True)\n",
" return loss\n",
"\n",
" def configure_optimizers(self):\n",
" if self.global_rank == 0:\n",
" print(self.trainer.model)\n",
" return torch.optim.AdamW(self.trainer.model.parameters(), lr=self.lr, eps=self.eps)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Configure your FSDP strategy\n",
"As `dolly-v2-7b` is a relatively large model, it cannot be properly fit into a single commercial GPU. In this example, we use the FSDP strategy to shard model parameters across multiple workers. This allows us to avoid GPU out-of-memory issues and support a larger global batch size.\n",
"\n",
"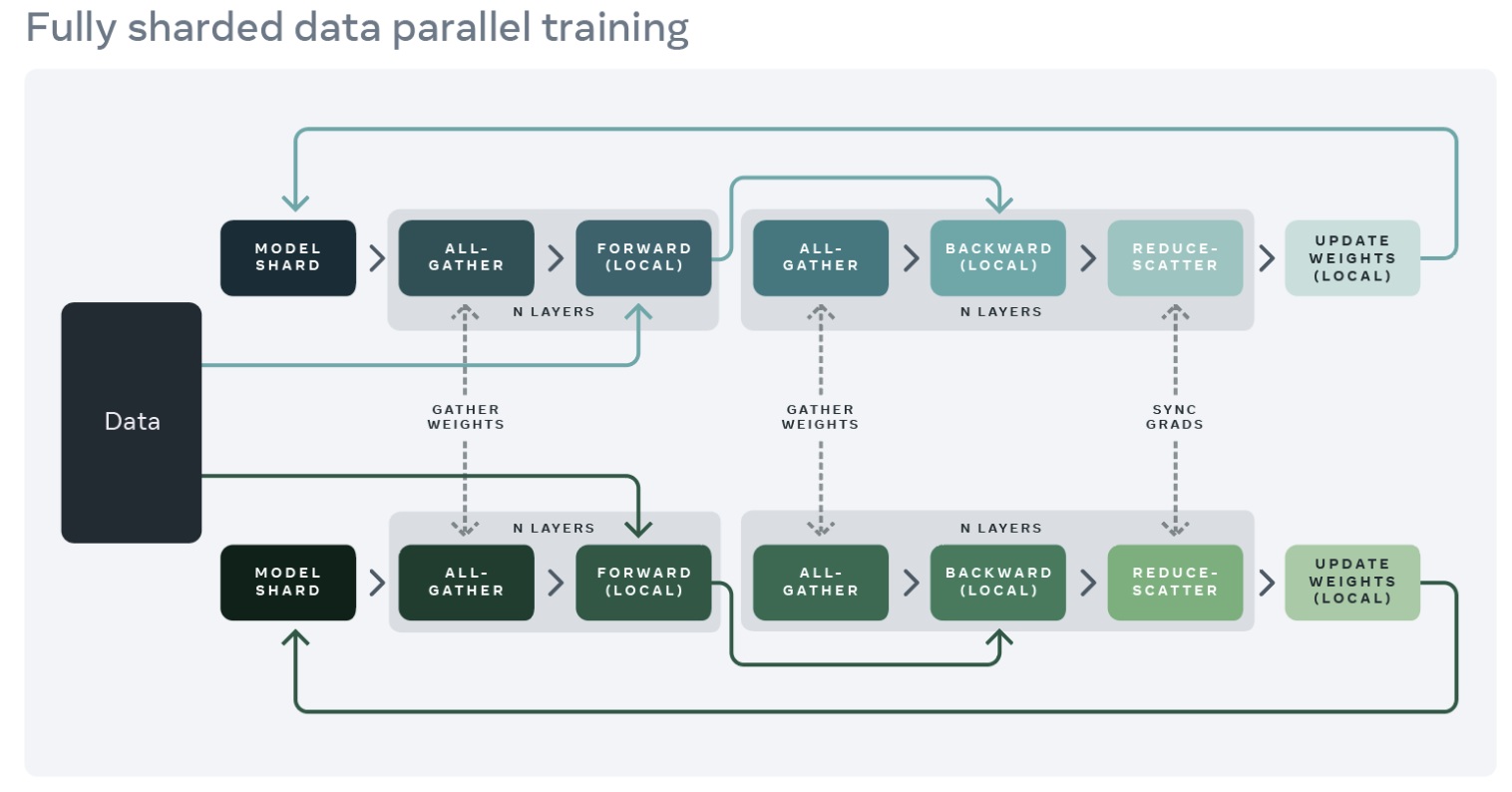\n",
"Image source: [Fully Sharded Data Parallel: faster AI training with fewer GPUs](https://engineering.fb.com/2021/07/15/open-source/fsdp/)\n",
"\n",
":::{note}\n",
"FSDP is a type of data parallelism that shards model parameters, optimizer states and gradients across DDP ranks. This was inspired by Xu et al. as well as the ZeRO Stage 3 from DeepSpeed. You may refer to these blogs for more information:\n",
"\n",
"- [Fully Sharded Data Parallel: faster AI training with fewer GPUs](https://engineering.fb.com/2021/07/15/open-source/fsdp/)\n",
"- [Getting Started with Fully Sharded Data Parallel(FSDP)](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html#:~:text=FSDP%20is%20a%20type%20of,sizes%20for%20our%20training%20job.)\n",
"- [PyTorch FSDP Tutorial](https://www.youtube.com/watch?v=8_k76AHu__s&list=PL_lsbAsL_o2BT6aerEKgIoufVD_fodnuT)\n",
":::\n",
"\n",
"To start training with Lightning's [FSDPStrategy](https://lightning.ai/docs/pytorch/stable/api/lightning.pytorch.strategies.FSDPStrategy.html#lightning.pytorch.strategies.FSDPStrategy), you only need to create a {class}`~ray.train.lightning.RayFSDPStrategy` with the same initialization arguments.\n"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import functools\n",
"import lightning.pytorch as pl \n",
"\n",
"from torch.distributed.fsdp.wrap import transformer_auto_wrap_policy\n",
"from torch.distributed.fsdp import ShardingStrategy, BackwardPrefetch\n",
"from transformers.models.gpt_neox.modeling_gpt_neox import GPTNeoXLayer\n",
"\n",
"from ray.train.lightning import RayFSDPStrategy\n",
"\n",
"\n",
"# Define the model sharding policy:\n",
"# Wrap every GPTNeoXLayer as its own FSDP instance\n",
"auto_wrap_policy = functools.partial(\n",
" transformer_auto_wrap_policy,\n",
" transformer_layer_cls = {GPTNeoXLayer}\n",
")\n",
"\n",
"fsdp_strategy = RayFSDPStrategy(\n",
" sharding_strategy=ShardingStrategy.FULL_SHARD,\n",
" backward_prefetch=BackwardPrefetch.BACKWARD_PRE,\n",
" forward_prefetch=True,\n",
" auto_wrap_policy=auto_wrap_policy,\n",
" limit_all_gathers=True,\n",
" activation_checkpointing=[GPTNeoXLayer],\n",
" cpu_offload=True\n",
")"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
":::{tip}\n",
"\n",
"Some tips for FSDP configuration:\n",
"- `sharding_strategy`:\n",
" - `ShardingStrategy.NO_SHARD`: Parameters, gradients, and optimizer states are not sharded. Similar to DDP.\n",
" - `ShardingStrategy.SHARD_GRAD_OP`: Gradients and optimizer states are sharded during computation, and additionally, parameters are sharded outside computation. Similar to ZeRO stage-2.\n",
" - `ShardingStrategy.FULL_SHARD`: Parameters, gradients, and optimizer states are sharded. It has minimal GRAM usage among the 3 options. Similar to ZeRO stage-3.\n",
"- `auto_wrap_policy`:\n",
" - Model layers are often wrapped with FSDP in a layered fashion. This means that only the layers in a single FSDP instance are required to aggregate all parameters to a single device during forwarding or backward calculations.\n",
" - Use `transformer_auto_wrap_policy` to automatically wrap each Transformer Block into a single FSDP instance. \n",
"- `backward_prefetch` and `forward_prefetch`:\n",
" - Overlap the upcoming all-gather while executing the current forward/backward pass. It can improve throughput but may slightly increase peak memory usage.\n",
":::"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Fine-tune with Ray TorchTrainer\n",
"\n",
"Ray TorchTrainer allows you to scale your PyTorch Lightning training workload over multiple nodes. See {ref}`Configuring Scale and GPUs ` for more details."
]
},
{
"cell_type": "code",
"execution_count": 10,
"metadata": {},
"outputs": [],
"source": [
"num_workers = 16\n",
"batch_size_per_worker = 5"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": [
"remove-cell"
]
},
"outputs": [],
"source": [
"# To accelerate release tests\n",
"train_ds = train_ds.limit(num_workers * batch_size_per_worker * 5) # each worker has 5 batches"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"Additionally, remember to define a Lightning callback that saves and reports checkpoints. Ray Train offers a simple implementation, {meth}`~ray.train.lightning.RayTrainReportCallback`, which persists your checkpoint and metrics in remote storage at the end of each training epoch. \n",
"\n",
"Note you can also implement your own report callback with customized logics, such as saving customized checkpoint files or reporting at a different frequency."
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": [
"remove-cell"
]
},
"outputs": [],
"source": [
"from lightning.pytorch.callbacks import TQDMProgressBar\n",
"\n",
"# Create a customized progress bar for Ray Data Iterable Dataset\n",
"class DollyV2ProgressBar(TQDMProgressBar):\n",
" def __init__(self, num_iters_per_epoch, *args, **kwargs):\n",
" super().__init__(*args, **kwargs)\n",
" self.num_iters_per_epoch = num_iters_per_epoch\n",
" \n",
" def on_train_epoch_start(self, trainer, *_):\n",
" super().on_train_epoch_start(trainer, *_)\n",
" self.train_progress_bar.reset(self.num_iters_per_epoch)\n",
"\n",
"num_iters_per_epoch = train_ds.count() // (num_workers * batch_size_per_worker)\n",
"prog_bar = DollyV2ProgressBar(num_iters_per_epoch)"
]
},
{
"cell_type": "code",
"execution_count": 13,
"metadata": {},
"outputs": [],
"source": [
"from ray.train import Checkpoint\n",
"from ray.train.lightning import RayLightningEnvironment, RayTrainReportCallback, prepare_trainer\n",
"\n",
"# Training function for each worker\n",
"def train_func(config):\n",
" lr = config[\"lr\"]\n",
" eps = config[\"eps\"]\n",
" strategy = config[\"strategy\"]\n",
" batch_size_per_worker = config[\"batch_size_per_worker\"]\n",
"\n",
" # Model\n",
" model = DollyV2Model(lr=lr, eps=eps)\n",
"\n",
" # Ray Data Ingestion\n",
" train_ds = ray.train.get_dataset_shard(\"train\")\n",
" train_dataloader = train_ds.iter_torch_batches(batch_size=batch_size_per_worker)\n",
"\n",
" # Lightning Trainer\n",
" trainer = pl.Trainer(\n",
" max_epochs=1, \n",
" devices=\"auto\",\n",
" accelerator=\"auto\", \n",
" precision=\"16-mixed\",\n",
" strategy=strategy,\n",
" plugins=[RayLightningEnvironment()],\n",
" callbacks=[RayTrainReportCallback()],\n",
" enable_checkpointing=False,\n",
" )\n",
"\n",
" trainer = prepare_trainer(trainer)\n",
"\n",
" trainer.fit(model, train_dataloaders=train_dataloader)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"```{note}\n",
"Since this example runs with multiple nodes, we need to persist checkpoints\n",
"and other outputs to some external storage for access after training has completed.\n",
"**You should set up cloud storage or NFS, then replace `storage_path` with your own cloud bucket URI or NFS path.**\n",
"\n",
"See the [storage guide](tune-storage-options) for more details.\n",
"```"
]
},
{
"cell_type": "code",
"execution_count": 14,
"metadata": {},
"outputs": [],
"source": [
"storage_path=\"s3://your-bucket-here\" # TODO: Set up cloud storage\n",
"# storage_path=\"/mnt/path/to/nfs\" # TODO: Alternatively, set up NFS"
]
},
{
"cell_type": "code",
"execution_count": 15,
"metadata": {
"tags": [
"remove-cell"
]
},
"outputs": [],
"source": [
"storage_path = \"/mnt/cluster_storage\""
]
},
{
"cell_type": "code",
"execution_count": 16,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stderr",
"output_type": "stream",
"text": [
"\u001b[36m(TrainController pid=6878)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m _torch_pytree._register_pytree_node(\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/transformers/utils/generic.py:309: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m _torch_pytree._register_pytree_node(\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m [State Transition] INITIALIZING -> SCHEDULING.\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m Attempting to start training worker group of size 16 with the following resources: [{'GPU': 1}] * 16\n",
"\u001b[36m(RayTrainWorker pid=4349, ip=10.0.157.249)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.\n",
"\u001b[36m(RayTrainWorker pid=4349, ip=10.0.157.249)\u001b[0m _torch_pytree._register_pytree_node(\n",
"\u001b[36m(RayTrainWorker pid=4350, ip=10.0.157.249)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.\n",
"\u001b[36m(RayTrainWorker pid=4350, ip=10.0.157.249)\u001b[0m _torch_pytree._register_pytree_node(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m Setting up process group for: env:// [rank=0, world_size=16]\n",
"\u001b[36m(RayTrainWorker pid=4349, ip=10.0.157.249)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/huggingface_hub/file_download.py:795: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
"\u001b[36m(RayTrainWorker pid=4349, ip=10.0.157.249)\u001b[0m warnings.warn(\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m Started training worker group of size 16: \n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.163.141, pid=4088) world_rank=0, local_rank=0, node_rank=0\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.163.141, pid=4089) world_rank=1, local_rank=1, node_rank=0\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.163.141, pid=4090) world_rank=2, local_rank=2, node_rank=0\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.163.141, pid=4091) world_rank=3, local_rank=3, node_rank=0\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.166.248, pid=4338) world_rank=4, local_rank=0, node_rank=1\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.166.248, pid=4337) world_rank=5, local_rank=1, node_rank=1\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.166.248, pid=4340) world_rank=6, local_rank=2, node_rank=1\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.166.248, pid=4339) world_rank=7, local_rank=3, node_rank=1\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.191.43, pid=4090) world_rank=8, local_rank=0, node_rank=2\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.191.43, pid=4248) world_rank=9, local_rank=1, node_rank=2\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.191.43, pid=4246) world_rank=10, local_rank=2, node_rank=2\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.191.43, pid=4247) world_rank=11, local_rank=3, node_rank=2\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.157.249, pid=4349) world_rank=12, local_rank=0, node_rank=3\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.157.249, pid=4350) world_rank=13, local_rank=1, node_rank=3\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.157.249, pid=4347) world_rank=14, local_rank=2, node_rank=3\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m - (ip=10.0.157.249, pid=4348) world_rank=15, local_rank=3, node_rank=3\n",
"\u001b[36m(TrainController pid=6878)\u001b[0m [State Transition] SCHEDULING -> RUNNING.\n",
"\u001b[36m(RayTrainWorker pid=4246, ip=10.0.191.43)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/transformers/utils/generic.py:309: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.\u001b[32m [repeated 31x across cluster] (Ray deduplicates logs by default. Set RAY_DEDUP_LOGS=0 to disable log deduplication, or see https://docs.ray.io/en/master/ray-observability/user-guides/configure-logging.html#log-deduplication for more options.)\u001b[0m\n",
"\u001b[36m(RayTrainWorker pid=4246, ip=10.0.191.43)\u001b[0m _torch_pytree._register_pytree_node(\u001b[32m [repeated 31x across cluster]\u001b[0m\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"\u001b[33m(raylet)\u001b[0m WARNING: 4 PYTHON worker processes have been started on node: 3ffdd02cd1be6b69a64a97e08f75fc0a80eddcf0caa627f3f4266c95 with address: 10.0.150.21. This could be a result of using a large number of actors, or due to tasks blocked in ray.get() calls (see https://github.com/ray-project/ray/issues/3644 for some discussion of workarounds).\n"
]
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m GPU available: True (cuda), used: True\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m TPU available: False, using: 0 TPU cores\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m HPU available: False, using: 0 HPUs\n",
"\u001b[36m(RayTrainWorker pid=4246, ip=10.0.191.43)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/huggingface_hub/file_download.py:795: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\u001b[32m [repeated 15x across cluster]\u001b[0m\n",
"\u001b[36m(RayTrainWorker pid=4246, ip=10.0.191.43)\u001b[0m warnings.warn(\u001b[32m [repeated 15x across cluster]\u001b[0m\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 2025-09-30 14:20:07.970624: I tensorflow/core/util/port.cc:113] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 2025-09-30 14:20:08.208262: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 2025-09-30 14:20:08.208291: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 2025-09-30 14:20:08.231782: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 2025-09-30 14:20:08.277889: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m To enable the following instructions: AVX2 AVX512F AVX512_VNNI FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m _torch_pytree._register_pytree_node(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 2025-09-30 14:20:10.134645: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0,1,2,3]\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m FullyShardedDataParallel(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (_fsdp_wrapped_module): DollyV2Model(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (model): GPTNeoXForCausalLM(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (gpt_neox): GPTNeoXModel(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (embed_in): Embedding(50280, 4096)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (emb_dropout): Dropout(p=0.0, inplace=False)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (layers): ModuleList(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (0-31): 32 x FullyShardedDataParallel(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (_fsdp_wrapped_module): CheckpointWrapper(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (_checkpoint_wrapped_module): GPTNeoXLayer(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (input_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (post_attention_layernorm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (post_attention_dropout): Dropout(p=0.0, inplace=False)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (post_mlp_dropout): Dropout(p=0.0, inplace=False)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (attention): GPTNeoXAttention(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (rotary_emb): GPTNeoXRotaryEmbedding()\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (query_key_value): Linear(in_features=4096, out_features=12288, bias=True)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (dense): Linear(in_features=4096, out_features=4096, bias=True)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (attention_dropout): Dropout(p=0.0, inplace=False)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (mlp): GPTNeoXMLP(\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (dense_h_to_4h): Linear(in_features=4096, out_features=16384, bias=True)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (dense_4h_to_h): Linear(in_features=16384, out_features=4096, bias=True)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (act): GELUActivation()\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (final_layer_norm): LayerNorm((4096,), eps=1e-05, elementwise_affine=True)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m (embed_out): Linear(in_features=4096, out_features=50280, bias=False)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m )\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m /tmp/ray/session_2025-09-30_14-10-46_627006_2395/runtime_resources/pip/72a6e451f55d87eb50ebbf5bc30a4a57ed513d34/virtualenv/lib/python3.10/site-packages/lightning/pytorch/utilities/model_summary/model_summary.py:231: Precision 16-mixed is not supported by the model summary. Estimated model size in MB will not be accurate. Using 32 bits instead.\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m \n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m | Name | Type | Params | Mode\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m ----------------------------------------------------\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 0 | model | GPTNeoXForCausalLM | 428 M | eval\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m ----------------------------------------------------\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 428 M Trainable params\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 0 Non-trainable params\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 428 M Total params\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 1,714.014 Total estimated model params size (MB)\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 64 Modules in train mode\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m 455 Modules in eval mode\n",
"\u001b[36m(RayTrainWorker pid=4246, ip=10.0.191.43)\u001b[0m LOCAL_RANK: 2 - CUDA_VISIBLE_DEVICES: [0,1,2,3]\u001b[32m [repeated 15x across cluster]\u001b[0m\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m Registered dataset logger for dataset train_12_0\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m Starting execution of Dataset train_12_0. Full logs are in /tmp/ray/session_2025-09-30_14-10-46_627006_2395/logs/ray-data\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m Execution plan of Dataset train_12_0: InputDataBuffer[Input] -> TaskPoolMapOperator[MapBatches(split_text)->MapBatches(tokenize)] -> LimitOperator[limit=400] -> OutputSplitter[split(16, equal=True)]\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m ⚠️ Ray's object store is configured to use only 28.7% of available memory (229.3GiB out of 800.0GiB total). For optimal Ray Data performance, we recommend setting the object store to at least 50% of available memory. You can do this by setting the 'object_store_memory' parameter when calling ray.init() or by setting the RAY_DEFAULT_OBJECT_STORE_MEMORY_PROPORTION environment variable.\n"
]
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "ab803bffe2224e6591bc452cac07f2a8",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"(pid=7661) Running 0: 0.00 row [00:00, ? row/s]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "8d647925625f49c19e16fddce0fab359",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"(pid=7661) - MapBatches(split_text)->MapBatches(tokenize) 1: 0.00 row [00:00, ? row/s]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "30978a8d911a44dcb168b0d5a386a42c",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"(pid=7661) - limit=400 2: 0.00 row [00:00, ? row/s]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"data": {
"application/vnd.jupyter.widget-view+json": {
"model_id": "432c8cb6d3e84b749d9341ff104bb25c",
"version_major": 2,
"version_minor": 0
},
"text/plain": [
"(pid=7661) - split(16, equal=True) 3: 0.00 row [00:00, ? row/s]"
]
},
"metadata": {},
"output_type": "display_data"
},
{
"name": "stderr",
"output_type": "stream",
"text": [
"\u001b[36m(MapBatches(split_text)->MapBatches(tokenize) pid=4089, ip=10.0.191.43)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/transformers/utils/generic.py:441: UserWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead.\n",
"\u001b[36m(MapBatches(split_text)->MapBatches(tokenize) pid=4089, ip=10.0.191.43)\u001b[0m _torch_pytree._register_pytree_node(\n",
"\u001b[36m(MapBatches(split_text)->MapBatches(tokenize) pid=4089, ip=10.0.191.43)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/huggingface_hub/file_download.py:795: FutureWarning: `resume_download` is deprecated and will be removed in version 1.0.0. Downloads always resume when possible. If you want to force a new download, use `force_download=True`.\n",
"\u001b[36m(MapBatches(split_text)->MapBatches(tokenize) pid=4089, ip=10.0.191.43)\u001b[0m warnings.warn(\n",
"\u001b[36m(MapBatches(split_text)->MapBatches(tokenize) pid=4089, ip=10.0.191.43)\u001b[0m Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m /home/ray/anaconda3/lib/python3.10/site-packages/ray/anyscale/data/_internal/cluster_autoscaler/productivity_calculator.py:174: RuntimeWarning: invalid value encountered in divide\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m gpu_fraction_per_op = (optimal_num_tasks_per_op * num_gpus_per_op) / np.sum(\n",
"\u001b[36m(SplitCoordinator pid=7661)\u001b[0m ✔️ Dataset train_12_0 execution finished in 5.10 seconds\n",
"\u001b[36m(RayTrainWorker pid=4088, ip=10.0.163.141)\u001b[0m /tmp/ray/session_2025-09-30_14-10-46_627006_2395/runtime_resources/pip/72a6e451f55d87eb50ebbf5bc30a4a57ed513d34/virtualenv/lib/python3.10/site-packages/lightning/pytorch/loops/fit_loop.py:527: Found 455 module(s) in eval mode at the start of training. This may lead to unexpected behavior during training. If this is intentional, you can ignore this warning.\n"
]
},
{
"name": "stdout",
"output_type": "stream",
"text": [
"Epoch 0: | | 0/? [00:00)"
]
},
"execution_count": 16,
"metadata": {},
"output_type": "execute_result"
}
],
"source": [
"from ray.train.torch import TorchTrainer\n",
"from ray.train import RunConfig, ScalingConfig, CheckpointConfig\n",
"\n",
"# Save Ray Train checkpoints according to the performance on validation set\n",
"run_config = RunConfig(\n",
" name=\"finetune_dolly-v2-7b-trial1\",\n",
" storage_path=storage_path,\n",
" checkpoint_config=CheckpointConfig(num_to_keep=1),\n",
")\n",
"\n",
"# Scale the FSDP training workload across 16 GPUs\n",
"# You can change this config based on your compute resources.\n",
"scaling_config = ScalingConfig(\n",
" num_workers=num_workers, use_gpu=True\n",
")\n",
"\n",
"# Configuration to pass into train_func\n",
"train_config = {\n",
" \"lr\": 2e-5,\n",
" \"eps\": 1e-8,\n",
" \"strategy\": fsdp_strategy,\n",
" \"batch_size_per_worker\": batch_size_per_worker\n",
"}\n",
"\n",
"# Define a TorchTrainer and launch you training workload\n",
"ray_trainer = TorchTrainer(\n",
" train_func,\n",
" train_loop_config=train_config,\n",
" run_config=run_config,\n",
" scaling_config=scaling_config,\n",
" datasets={\"train\": train_ds},\n",
")\n",
"result = ray_trainer.fit()\n",
"\n",
"result\n"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"We finished training in 2877s. The price for an on-demand g4dn.4xlarge instance is `$1.204/hour`, while a g4dn.8xlarge instance costs `$2.176/hour`. The total cost would be `($1.204 * 15 + $2.176) * 2877 / 3600 = $16.17`."
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"## Text-generation with HuggingFace Pipeline\n",
"\n",
"We can use the [HuggingFace Pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines) to generate predictions from our fine-tuned model. Let's input some prompts and see if our tuned Dolly can speak like Shakespeare:"
]
},
{
"cell_type": "code",
"execution_count": null,
"metadata": {
"tags": []
},
"outputs": [],
"source": [
"import os\n",
"from transformers import pipeline\n",
"\n",
"@ray.remote(num_gpus=1)\n",
"def generate_tokens():\n",
" tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, padding_side=\"right\")\n",
"\n",
" ckpt_path = os.path.join(result.checkpoint.path, \"checkpoint.ckpt\")\n",
"\n",
" dolly = DollyV2Model.load_from_checkpoint(ckpt_path, map_location=torch.device(\"cpu\"))\n",
"\n",
" nlp_pipeline = pipeline(\n",
" task=\"text-generation\", \n",
" model=dolly.model, \n",
" tokenizer=tokenizer, \n",
" device_map=\"auto\"\n",
" )\n",
"\n",
" tokens = []\n",
" for prompt in [\"This is\", \"I am\", \"Once more\"]:\n",
" tokens.append(nlp_pipeline(prompt, max_new_tokens=20, do_sample=True, pad_token_id=tokenizer.eos_token_id))\n",
"\n",
" return tokens\n",
"\n",
"ref = generate_tokens.remote()\n",
"output = ray.get(ref)"
]
},
{
"cell_type": "code",
"execution_count": 23,
"metadata": {
"tags": []
},
"outputs": [
{
"name": "stdout",
"output_type": "stream",
"text": [
"[{'generated_text': \"This is more like it:\\n\\nIt's just a guess, but maybe the extra processing power of Intel\"}]\n",
"[{'generated_text': \"I am the biggest fan of your wife's writing, and this novella was fantastic. So interesting to see\"}]\n",
"[{'generated_text': 'Once more I wish I could make sense of it.\" \"My friend, you can leave all this behind you'}]\n"
]
}
],
"source": [
"for generated_tokens in output:\n",
" print(generated_tokens)"
]
},
{
"cell_type": "markdown",
"metadata": {},
"source": [
"References:\n",
"- [PyTorch FSDP Tutorial](https://www.youtube.com/watch?v=8_k76AHu__s&list=PL_lsbAsL_o2BT6aerEKgIoufVD_fodnuT)\n",
"- [Getting Started with Fully Sharded Data Parallel(FSDP)](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html#:~:text=FSDP%20is%20a%20type%20of,sizes%20for%20our%20training%20job.)\n",
"- [Fully Sharded Data Parallel: faster AI training with fewer GPUs](https://engineering.fb.com/2021/07/15/open-source/fsdp/)\n",
"- [Hugging Face: dolly-v2-7b Model Card](https://huggingface.co/databricks/dolly-v2-7b)\n",
"- [Hugging Face: Handling big models for inference](https://huggingface.co/docs/accelerate/usage_guides/big_modeling)"
]
}
],
"metadata": {
"kernelspec": {
"display_name": "Python 3 (ipykernel)",
"language": "python",
"name": "python3"
},
"language_info": {
"codemirror_mode": {
"name": "ipython",
"version": 3
},
"file_extension": ".py",
"mimetype": "text/x-python",
"name": "python",
"nbconvert_exporter": "python",
"pygments_lexer": "ipython3",
"version": "3.10.18"
},
"orphan": true
},
"nbformat": 4,
"nbformat_minor": 4
}